
非聚集索引和聚集索引
一.非聚集索引(MyISAM的索引方式):
使用B+Tree作為索引結構,葉節點的data域存放的是數據記錄的地址.主鍵索引圖:

輔助索引圖:
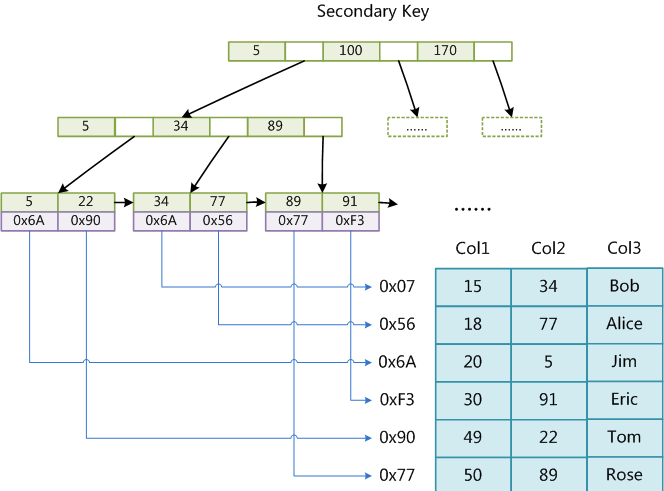
主鍵索引和輔助索引沒有本質上的區別,data域都保存的是數據行的地址.
二.聚集索引(InnoDB的索引方式):
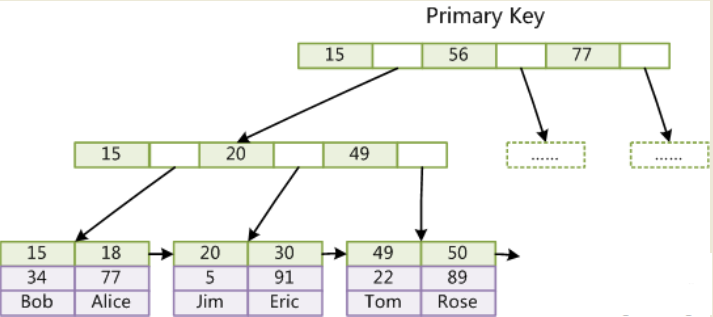
InnoDB的數據文件本身就是索引文件。在InnoDB中,表數據文件本身就是按B+Tree組織的一個索引結構,這棵樹的葉節點data域保存了完整的數據記錄。這個索引的key是數據表的主鍵,因此InnoDB表數據文件本身就是主索引。
主鍵索引圖:
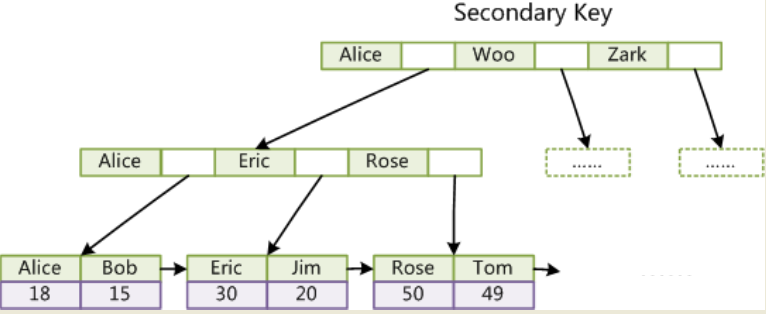
輔助索引:
InnoDB的輔助索引data域存儲相應記錄主鍵的值而不是地址。換句話說,InnoDB的所有輔助索引都引用主鍵作為data域.
ps:
1.如果innodb表沒有主鍵索引,innodb會自動找一個類似於此的唯一非空列,如果找不到,會增加一個隱藏列來做主索引.
2.Innodb中的每張表都會有一個聚集索引,而聚集索引又是以物理磁盤順序來存儲的,自增主鍵會把數據自動向後插入,避免了插入過程中的聚集索引排序問題。
三.覆蓋索引
覆蓋索引指的是數據的讀取不必經過數據行,而是直接從索引中讀取.這是mysql而言,是效率最好的讀取方式.
對於覆蓋索引而言,myisam和innodb有截然不同的表現(非聚集索引和聚集索引)
建立表:
CREATE TABLE `test` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`time` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `time` (`time`)
) ENGINE=MyISAM;
插入數據:
insert into test(time) values(1); insert into test(time) values(2);
我們來查詢一條數據,看看mysql解釋器表現:
mysql> explain select id from test where time=1; +----+-------------+-------+-------+---------------+---------+---------+-------+------+-------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-------+-------+---------------+---------+---------+-------+------+-------+ | 1 | SIMPLE | test | const | PRIMARY | PRIMARY | 4 | const | 1 | | +----+-------------+-------+-------+---------------+---------+---------+-------+------+-------+
註意Extra列,沒有出現using index;也就是沒有使用覆蓋索引;這很好理解,因為非聚集索引,該查詢先查詢了time索引(或key cache),找到對應記錄的地址,然後去數據行找數據了;mysql每次查詢只能用到一個索引.
如果是以下語句,就用到了覆蓋索引:
mysql> explain select time from test where time=1; +----+-------------+-------+------+---------------+------+---------+-------+------+--------------------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-------+------+---------------+------+---------+-------+------+--------------------------+ | 1 | SIMPLE | test | ref | time | time | 5 | const | 1 | Using where; Using index | +----+-------------+-------+------+---------------+------+---------+-------+------+--------------------------+
用到了time索引,只要求返回time列,不必去數據行找數據;直接從索引中找到數據返回;
現在我們將該表轉為innodb,看看innodb的表現:
mysql> explain select id from test where time=1; +----+-------------+-------+------+---------------+------+---------+-------+------+--------------------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-------+------+---------------+------+---------+-------+------+--------------------------+ | 1 | SIMPLE | test | ref | time | time | 5 | const | 1 | Using where; Using index | +----+-------------+-------+------+---------------+------+---------+-------+------+--------------------------+
用到了覆蓋索引.
mysql> explain select time from test where time=1; +----+-------------+-------+------+---------------+------+---------+-------+------+--------------------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-------+------+---------------+------+---------+-------+------+--------------------------+ | 1 | SIMPLE | test | ref | time | time | 5 | const | 1 | Using where; Using index | +----+-------------+-------+------+---------------+------+---------+-------+------+--------------------------+
四.文件排序和索引掃描排序
非聚集索引和聚集索引