
python筆記6-%u60A0和u60a0類似unicode解碼
阿新 • • 發佈:2017-12-18
分享 unicode 返回 div images int es2017 mark 分享圖片
前言
有時候從接口的返回值裏面獲取到的是類似"%u4E0A%u6D77%u60A0%u60A0"這種格式的編碼,不是python裏面的unicode編碼。
python裏面的unicode編碼應該是這種格式:\u4e0a\u6d77\u60a0\u60a0
unicode編碼-python2
1.先看下python的unicode編碼:\u60a0,這個是\u開頭的,裏面的英文是小寫
# coding:utf-8 # 前面加u可以直接打印中文 a = u"\u4e0a\u6d77\u60a0\u60a0" print(a) # 字符串需decode成默認unicode編碼 b = r"\u4e0a\u6d77\u60a0\u60a0" print(b.decode("unicode_escape"))
2.如果在字符串前面加個u,意思是轉化成unicode編碼,如果獲取到的是應該字符串原型,那就需要decode解碼成unicode編碼,python裏面默認的unicode編碼名稱是unicode_escape
替換%-python2
1.如果是這種帶%的編碼,先替換成,這樣就是unicode編碼了,雖然裏面的英文字符是大小,還好這裏不區分大小寫。
# coding:utf-8 c = "%u4E0A%u6D77%u60A0%u60A0" # 解決辦法一:替換% d = c.replace("%", "\\") print(d.decode('unicode_escape'))
解決辦法二:unichr
1.先切割成單個字符,再用unichr轉換成中文,再連成字符串,這個有點復雜了
# coding:utf-8 def switch_to_ch(f): '''轉換成中文''' g = f.split("%u")[1:] h = [''+unichr(int(i, 16)) for i in g] return "".join(h) if __name__ == "__main__": f = "%u4e0a%u6d77%u60a0%u60a0" ch = switch_to_ch(f) print(ch)
python3解碼
1.python3默認的編碼就是unicode,這個跟python2還不太一樣,如果直接給字符串decode會報錯:AttributeError: ‘str‘ object has no attribute ‘ecode‘
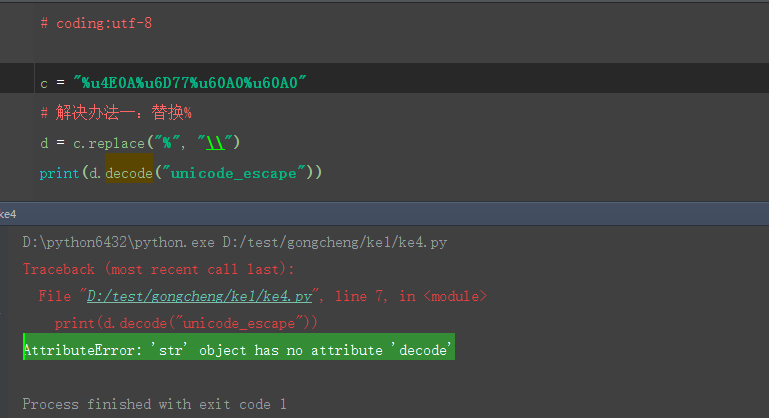
2.python3先encode成utf-8編碼,再decode成默認的unicode就可以了
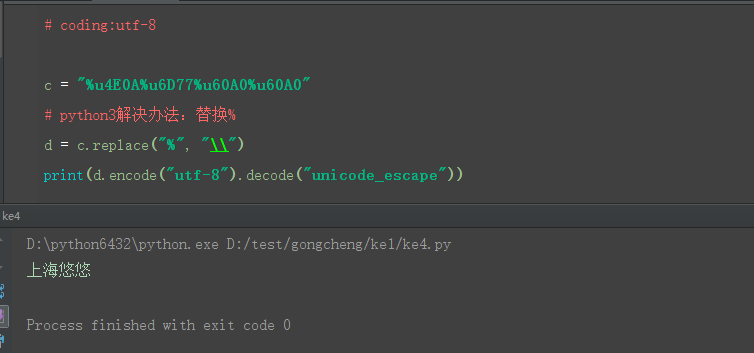
3.代碼參考
# coding:utf-8
c = "%u4E0A%u6D77%u60A0%u60A0"
# python3解決辦法:替換%
d = c.replace("%", "\\")
print(d.encode("utf-8").decode("unicode_escape"))python筆記6-%u60A0和\u60a0類似unicode解碼