
tensorflow入門 (一)
轉載:作者:地球的外星人君
鏈接:https://www.zhihu.com/question/49909565/answer/207609620
來源:知乎
著作權歸作者所有。商業轉載請聯系作者獲得授權,非商業轉載請註明出處。
分享一篇文章面向普通開發者的機器學習入門,作者@貍小華
前言
最近在摸索這方面相關的知識,本著整理鞏固,分享促進的精神。所以有了這篇博文。
需要註意的是,本文受眾:對機器學習感興趣,且願意花點時間學習的應用(業務)程序員
我本意是盡量簡單,易於理解,快速上手,短時間能跑出來東西,這樣子才能正向激勵我們的學習欲望。
基於上述條件,需要你已經有一定的開發經驗,微不足道的數學能力,以及善用搜索引擎的覺悟。開發環境搭建
開發環境搭建
首先,我希望你是Linux系用戶,如果你是巨硬黨,裝一個VirtualBox吧,然後再裝個ubuntu,由於我們只是入個門,對性能要求不高的。
機器學習相關的框架也很多,我這裏選擇了Keras,後端采用的Tensorflow 。那麽理所當然的,會用到python來開發,沒有python經驗也莫慌,影響並不大。
1.ubuntu自帶python 我就不介紹怎麽安裝了吧?
先安裝pip(-dev
我用的python2.7,後文統一)打開你的終端,輸入這個:(我建議更換下apt-get為國內鏡像,安裝完pip後也更換為國內鏡像吧)
sudo apt-get install python-pip python
2.安裝tensorflow和keras,matplotlib
還是打開終端,輸入輸入
mac端:
source activate ml_env27
>>conda install -c menpo menpoproject
>>pip install --upgrade tensorflow (use tensorflow-gpu if you want GPU support)
>>pip install -Iv keras==1.2.2 (make sure you install version 1.2.2)
>>conda install scikit-image h5py bidict psutil imageio
安裝好依賴環境
python 測試
Python
import tensorflow as tf hello = tf.constant(‘Hello, TensorFlow!‘) sess = tf.Session() print(sess.run(hello))
exit()
3.以後就用anconda配置好的環境配合pycharm來進行試驗。

一些理論知識:
卷積神經網絡CNN淺析
我建議你先把CNN當作一個黑盒子,不要關心為什麽,只關心結果。
這裏借用了一個分辨X和o的例子來這裏看原文,就是每次給你一張圖,你需要判斷它是否含有"X"或者"O"。並且假設必須兩者選其一,不是"X"就是"O"。
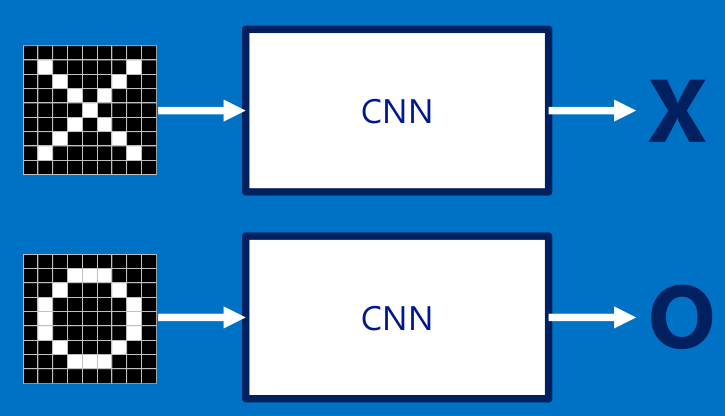
下面看一下CNN是怎麽分辨輸入的圖像是x還是o,如果需要你來編程分辨圖像是x還是o,你會怎麽做?
可能你第一時間就想到了逐個像素點對比。但是,如果圖片稍微有點變化呢?像是下面這個x,它不是標準的x,我們可以分辨它是x,
但是對於計算機而言,它就只是一個二維矩陣,逐個像素點對比肯定是不行的。

CNN就是用於解決這類問題的,它不在意具體每個點的像素,而是通過一種叫卷積的手段,去提取圖片的特征。
什麽是特征?
特征就是我們用於區分兩種輸入是不是同一類的分辨點,像是這個XXOO的例子,如果要你描述X和O的區別,你會怎麽思考?X是兩條線交叉,O是封閉的中空的。。。
我們來看個小小的例子,如果下面兩張圖,需要分類出喜歡和不喜歡兩類,那麽你會提取什麽作為區分的特征?(手動滑稽)

卷積層
所以對於CNN而言,第一步就是提取特征,卷積就是提取猜測特征的神奇手段。而我們不需要指定特征,任憑它自己去猜測,就像上圖,
我們只需要告訴它,我們喜歡左邊的,不喜歡右邊的,然後它就去猜測,區分喜不喜歡的特征是黑絲,還是奶子呢?
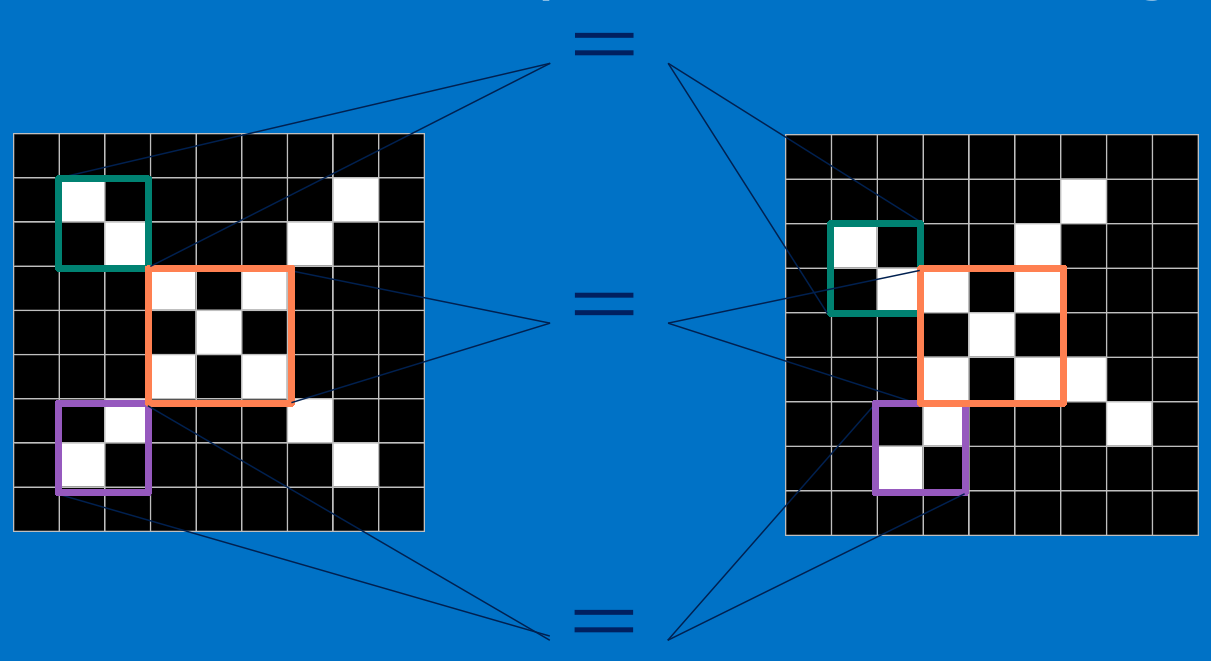
假設,我們上面這個例子,CNN對於X的猜測特征如上,現在要通過這些特征來分類。
計算機對於圖像的認知是在矩陣上的,每一張圖片有rgb二維矩陣(不考慮透明度)所以,一張圖片,
應該是3x高度x寬度的矩陣。而我們這個例子就只有黑白,所以可以簡單標記1為白,-1為黑。是個9x9的二維矩陣。

我們把上面的三個特征作為卷積核(我們這裏是假設已經訓練好了CNN,訓練提出的特征就是上面三個,我們可以通過這三個特征去分類 X ),去和輸入的圖像做卷積(特征的匹配)。
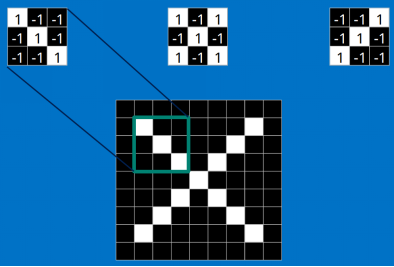
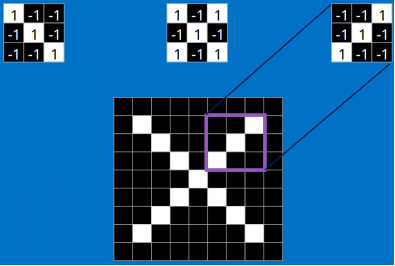

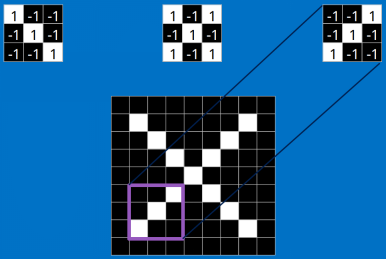
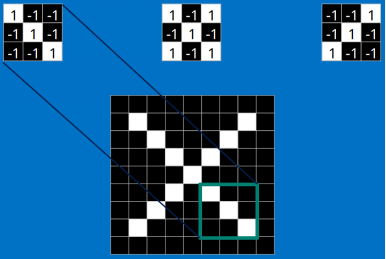
看完上面的,估計你也能看出特征是如何去匹配輸入的,這就是一個卷積的過程,具體的卷積計算過程如下(只展示部分):
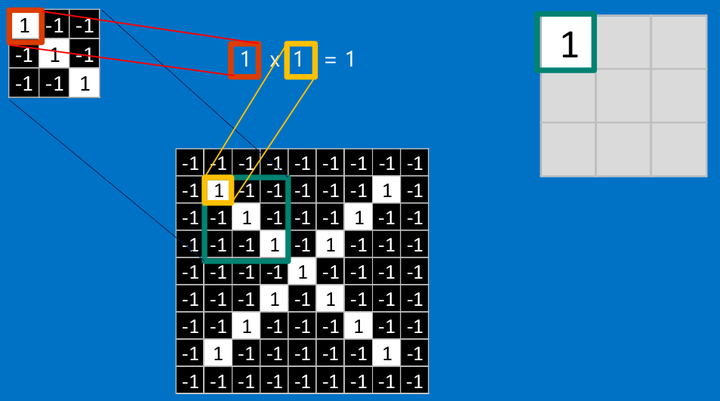
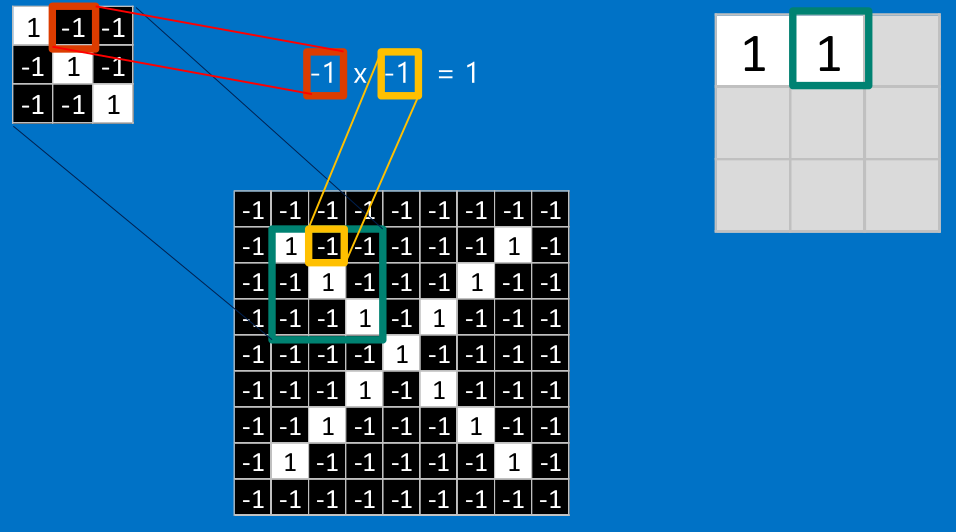
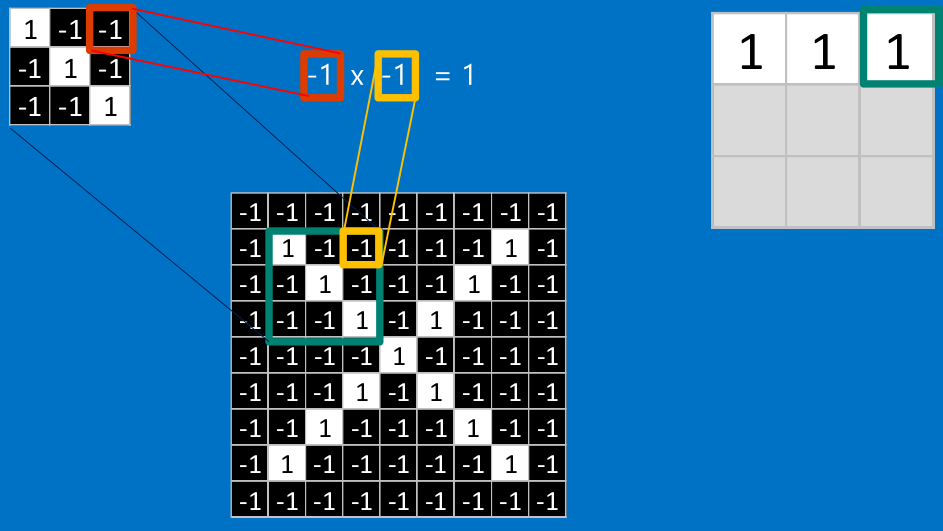
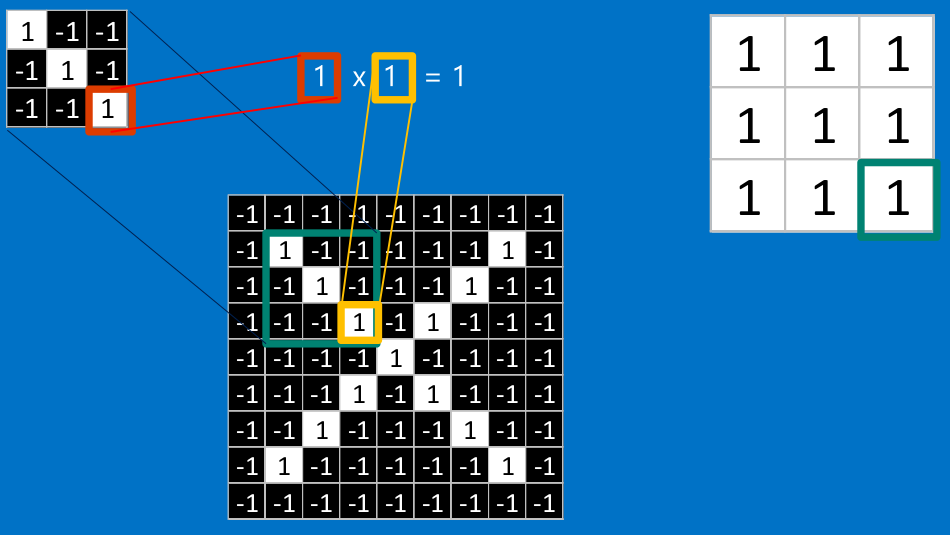
把計算出的結果填入新的矩陣
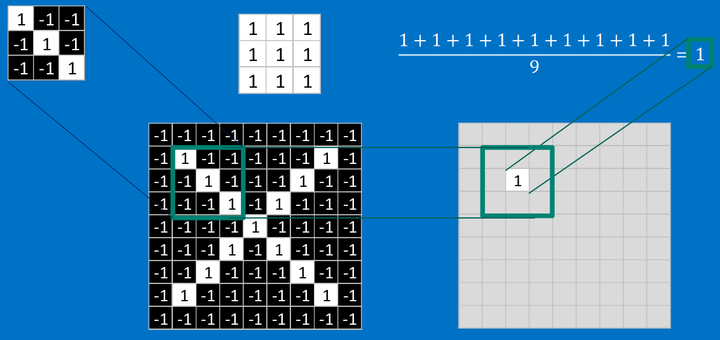
其他部分也是相同的計算
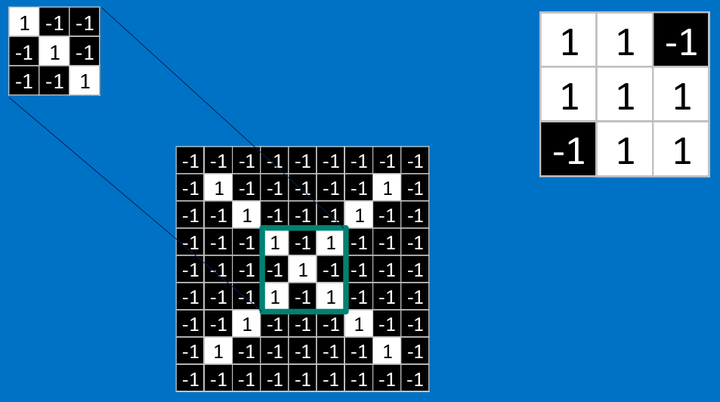
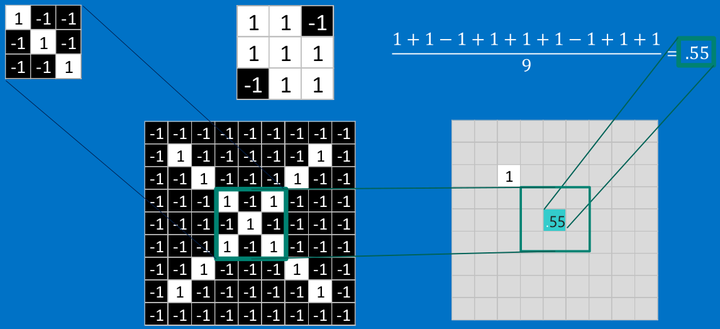
最後,我們整張圖用卷積核計算完成後:

三個特征都計算完成後:

不斷地重復著上述過程,將卷積核(特征)和圖中每一塊進行卷積操作。最後我們會得到一個新的二維數組。
其中的值,越接近為1表示對應位置的匹配度高,越是接近-1,表示對應位置與特征的反面更匹配,而值接近0的表示對應位置沒有什麽關聯。
以上就是我們的卷積層,通過特征卷積,輸出一個新的矩陣給下一層。
池化層
在圖像經過以上的卷積層後,得到了一個新的矩陣,而矩陣的大小,則取決於卷積核的大小,和邊緣的填充方式,總之,在這個XXOO的例子中,我們得到了7x7的矩陣。池化就是縮減圖像尺寸和像素關聯性的操作,只保留我們感興趣(對於分類有意義)的信息。
常用的就是2x2的最大池。
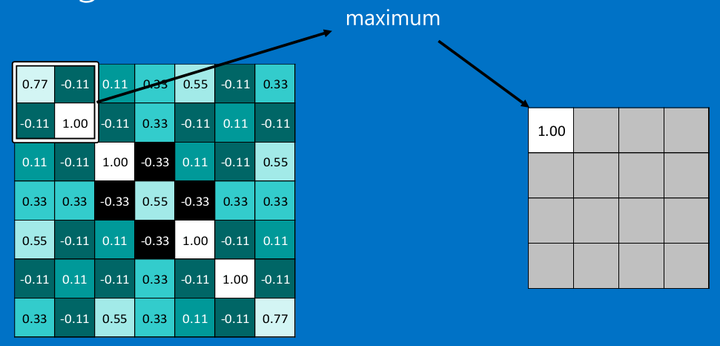
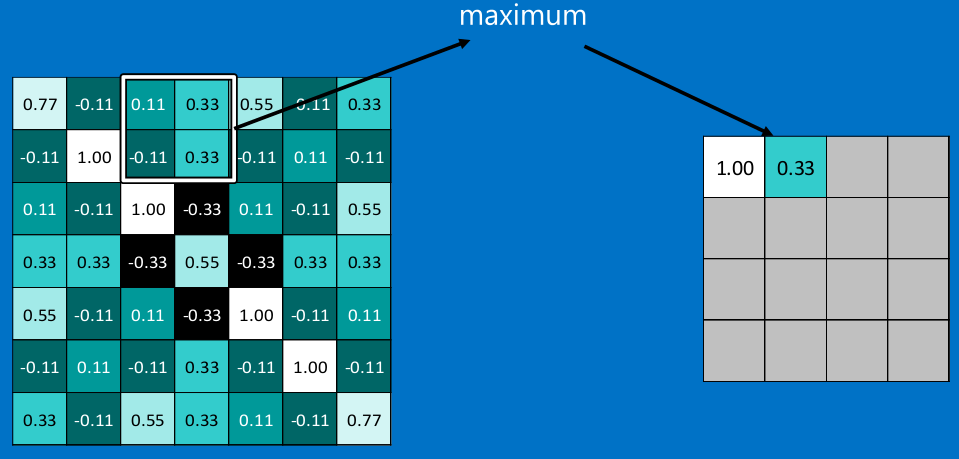
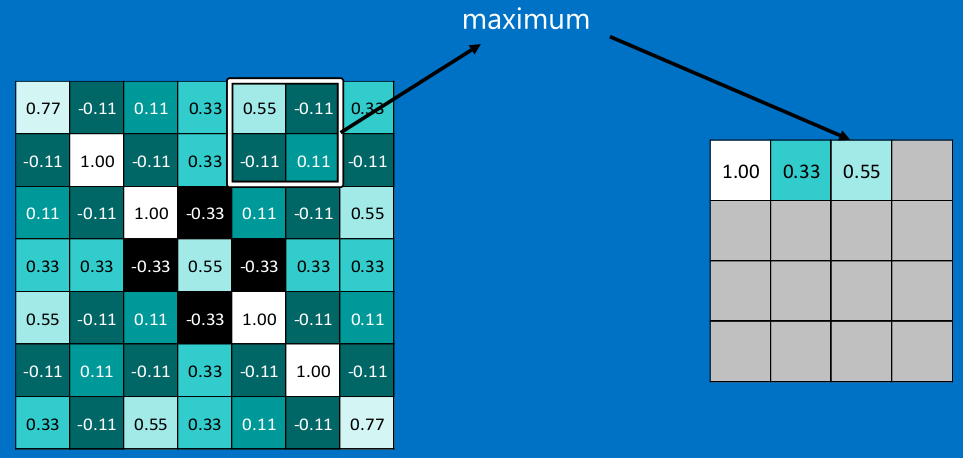
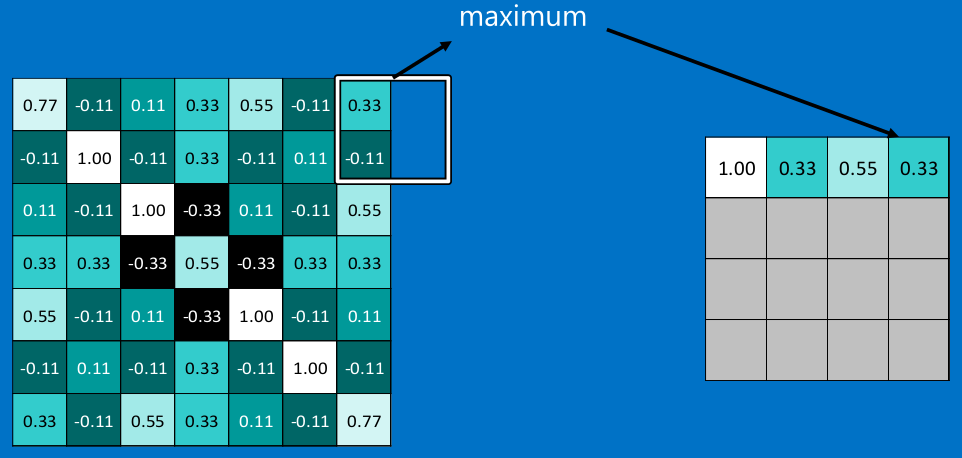
看完上面的圖,你應該知道池化是什麽操作了。
通常情況下,我們使用的都是2x2的最大池,就是在2x2的範圍內,取最大值。因為最大池化(max-pooling)保留了每一個小塊內的最大值,所以它相當於保留了這一塊最佳的匹配結果(因為值越接近1表示匹配越好)。這也就意味著它不會具體關註窗口內到底是哪一個地方匹配了,而只關註是不是有某個地方匹配上了。
這也就能夠看出,CNN能夠發現圖像中是否具有某種特征,而不用在意到底在哪裏具有這種特征。這也就能夠幫助解決之前提到的計算機逐一像素匹配的死板做法。

同樣的操作以後,我們就輸出了3個4x4的矩陣。
全連接層
全連接層一般是為了展平數據,輸出最終分類結果前的歸一化。 我們把上面得到的4x4矩陣再卷積+池化,得到2x2的矩陣

全連接就是這樣子,展開數據,形成1xn的‘條‘型矩陣。
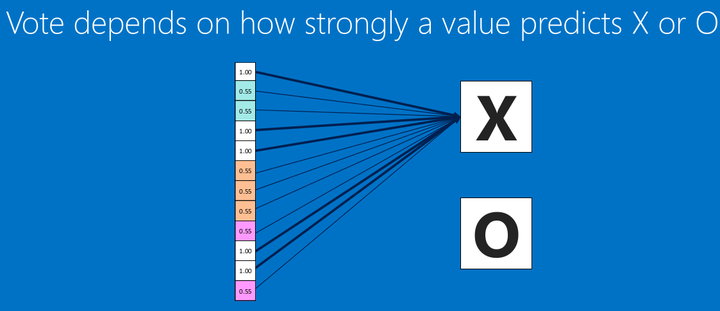
然後再把全連接層連接到輸出層。之前我們就說過,這裏的數值,越接近1表示關聯度越大,然後我們根據這些關聯度,分辨到底是O還是X.
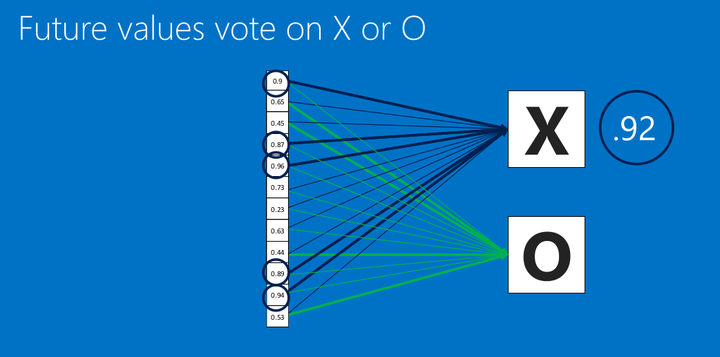
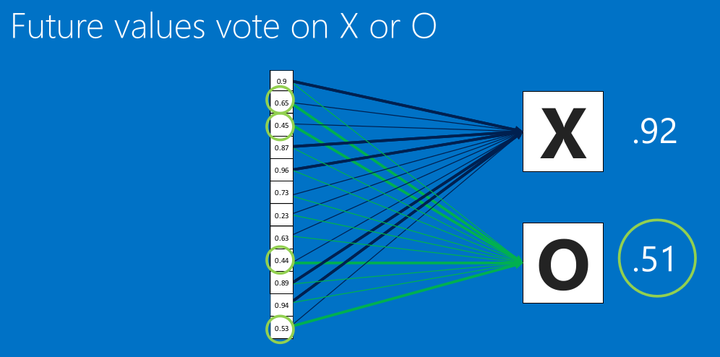
看上圖(圈圈裏面的幾個關鍵信息點),這裏有個新的圖像丟進我們的CNN了,根據卷積>池化>卷積>池化>全連接的步驟,我們得到了新的全連接數據,然後去跟我們的標準比對,得出相似度,可以看到,相似度是X的為0.92 所以,我們認為這個輸入是X。
一個基本的卷積神經網絡就是這樣子的。回顧一下,它的結構:

Relu是常用的激活函數,所做的工作就是max(0,x),就是輸入大於零,原樣輸出,小於零輸出零,這裏就不展開了。
CNN實現手寫數字識別
感覺,這個mnist的手寫數字,跟其他語言的helloworld一樣了。我們這裏來簡單實現下。首先,我建議你先下載好數據集,keras的下載太慢了(下載地址)。
下載好以後,按下面的位置放,你可能要先運行下程序,讓他自己創建文件夾,不然,你就手動創建吧。
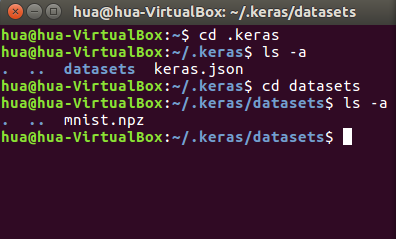
新建個python文件,test.py然後輸入下面的內容
#coding: utf-8 from keras.datasets import mnist import matplotlib.pyplot as plt # 加載數據 (X_train, y_train), (X_test, y_test) = mnist.load_data() # 展示下第一張圖 plt.imshow(X_train[0], cmap=plt.get_cmap(‘PuBuGn_r‘)) plt.show()
運行後出來張圖片,然後關掉就行,這裏只是看看我們加載數據有沒有問題。
x_train,x_test是我們的圖像矩陣數據,是28x28大小,然後有12500條吧好像。然後y_train,y_test都是標簽數據,標明這張圖代表是數字幾。
#coding: utf-8 #Simple CNN import numpy from keras.datasets import mnist from keras.models import Sequential from keras.layers import Dense from keras.layers import Dropout from keras.layers import Flatten from keras.layers.convolutional import Conv2D from keras.layers.convolutional import MaxPooling2D from keras.utils import np_utils seed = 7 numpy.random.seed(seed) #加載數據 (X_train, y_train), (X_test, y_test) = mnist.load_data() # reshape to be [samples][channels][width][height] X_train = X_train.reshape(X_train.shape[0],28, 28,1).astype(‘float32‘) X_test = X_test.reshape(X_test.shape[0],28, 28,1).astype(‘float32‘) # normalize inputs from 0-255 to 0-1 X_train = X_train / 255 X_test = X_test / 255 # one hot encode outputs y_train = np_utils.to_categorical(y_train) y_test = np_utils.to_categorical(y_test) num_classes = y_test.shape[1] # 簡單的CNN模型 def baseline_model(): # create model model = Sequential() #卷積層 model.add(Conv2D(32, (3, 3), padding=‘valid‘, input_shape=(28, 28,1), activation=‘relu‘)) #池化層 model.add(MaxPooling2D(pool_size=(2, 2))) #卷積 model.add(Conv2D(15, (3, 3), padding=‘valid‘ ,activation=‘relu‘)) #池化 model.add(MaxPooling2D(pool_size=(2, 2))) #全連接,然後輸出 model.add(Flatten()) model.add(Dense(128, activation=‘relu‘)) model.add(Dense(num_classes, activation=‘softmax‘)) # Compile model model.compile(loss=‘categorical_crossentropy‘, optimizer=‘adam‘, metrics=[‘accuracy‘]) return model # build the model model = baseline_model() # Fit the model model.fit(X_train, y_train, validation_data=(X_test, y_test), epochs=10, batch_size=128, verbose=2)
代碼也挺簡單,因為keras也是封裝的挺好的了。基本你看懂了前面的就沒問題。
Epoch 1/10 3s - loss: 0.2791 - acc: 0.9203 - val_loss: 0.1420 - val_acc: 0.9579 Epoch 2/10 3s - loss: 0.1122 - acc: 0.9679 - val_loss: 0.0992 - val_acc: 0.9699 Epoch 3/10 3s - loss: 0.0724 - acc: 0.9790 - val_loss: 0.0784 - val_acc: 0.9745 Epoch 4/10 3s - loss: 0.0509 - acc: 0.9853 - val_loss: 0.0774 - val_acc: 0.9773 Epoch 5/10 3s - loss: 0.0366 - acc: 0.9898 - val_loss: 0.0626 - val_acc: 0.9794 Epoch 6/10 3s - loss: 0.0265 - acc: 0.9930 - val_loss: 0.0639 - val_acc: 0.9797 Epoch 7/10 3s - loss: 0.0185 - acc: 0.9956 - val_loss: 0.0611 - val_acc: 0.9811 Epoch 8/10 3s - loss: 0.0150 - acc: 0.9967 - val_loss: 0.0616 - val_acc: 0.9816 Epoch 9/10 4s - loss: 0.0107 - acc: 0.9980 - val_loss: 0.0604 - val_acc: 0.9821 Epoch 10/10 4s - loss: 0.0073 - acc: 0.9988 - val_loss: 0.0611 - val_acc: 0.9819
然後你就能看到這些輸出,acc就是準確率了,看後面的val_acc就行。
tensorflow入門 (一)