
在python獲取網頁的代碼中添加頭信息模擬瀏覽器
阿新 • • 發佈:2018-01-14
alt 把他 無法 app 兩種 port tex 方法 vpd 為什麽要添加頭部信息,因為有時候有些網頁會有反爬蟲的設置,導致無法獲取正常的網頁,在這裏,在代碼的頭部添加一個headers信息,模擬成瀏覽器去訪問網頁。
方法1:使用build_opener()來添加
沒有添加頭部信息的代碼
import urllib2
url = "http://blog.51cto.com/lsfandlinux/2046467"
file = urllib2.urlopen(url)
html = file.read()
print html接下來添加頭部信息,首先在瀏覽器打開百度一下,然後檢查網頁的頭部信息,找到User-Agent,這就是我們用來模擬瀏覽器要用到的信息,把他復制下來。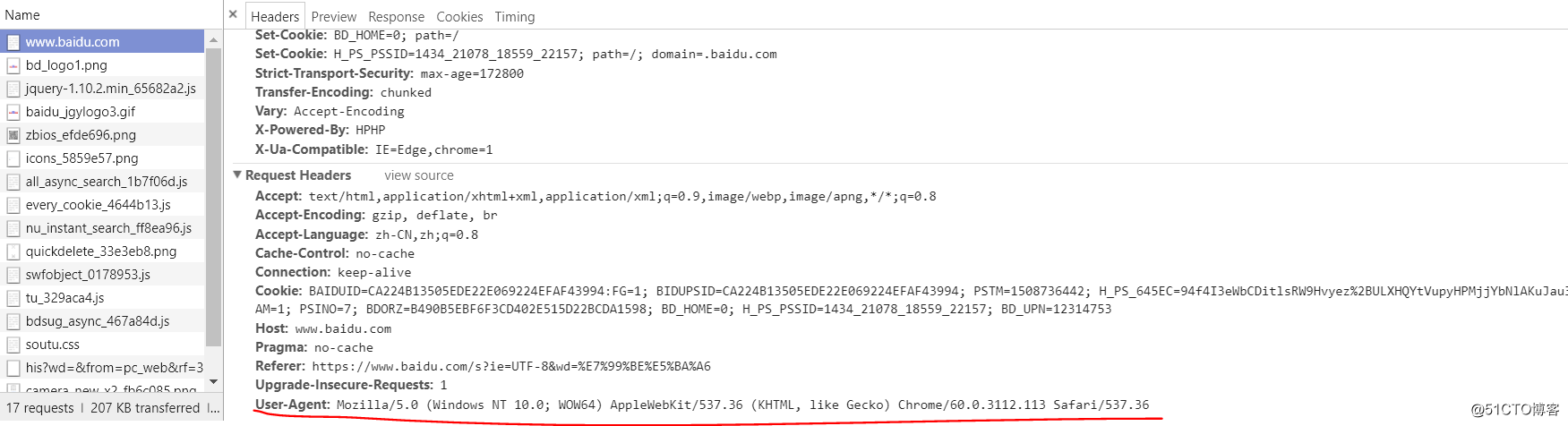
然後在代碼裏面添加頭部信息的變量存儲對應的headers信息,定義的格式為(“User-Agent”,具體信息)。
方法1:使用build_opener()來添加
import urllib2 url = "http://blog.51cto.com/lsfandlinux/2046467" headers = ("User-Agent","Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.113 Safari/537.36") opener = urllib2.build_opener() opener.addheaders = [headers] file = opener.open(url) html = file.read() print html
我們利用opener.open(url)就是打開網頁,這個opener就是具有頭部信息的操作了。
方法2:利用add_header()來添加
import urllib2 url = "http://blog.51cto.com/lsfandlinux/2046467" req = urllib2.Request(url) req.add_header("User-Agent","Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.113 Safari/537.36") file = urllib2.urlopen(req) html = file.read() print html
該方法是通過urllib2裏的Request來創建一個Request對象賦值給變量req,然後使用add_header添加頭部信息。
在python獲取網頁的代碼中添加頭信息模擬瀏覽器