
全鏈路設計與實踐

背景
隨著公司業務的高速發展,公司服務之間的調用關系愈加復雜,如何理清並跟蹤它們之間的調用關系就顯的比較關鍵。線上每一個請求會經過多個業務系統,並產生對各種緩存或者 DB 的訪問,但是這些分散的數據對於問題排查,或者流程優化提供的幫助有限。在這樣復雜的業務場景下,業務流會經過很多個微服務的處理和傳遞,我們難免會遇到這些問題:
- 一次請求的流量從哪個服務而來? 最終落到了哪個服務中去?
- 為什麽這個請求這麽慢? 到底哪個環節出了問題?
- 這個操作需要依賴哪些東西? 是數據庫還是消息隊列? Redis掛了,哪些業務受影響?
設計目標
- 低消耗性:跟蹤系統對業務系統的影響應該做到足夠小。在一些高度優化過的服務,即使一點點損耗也容易察覺到,而且有可能迫使在線負責的部署團隊不得不將跟蹤系統關停
- 低侵入性:作為非業務組件,應當盡可能少侵入或者無侵入業務系統,對於使用方透明,減少開發人員的負擔
- 時效性:從數據的收集產生,到數據計算處理,再到最終展現,都要求盡可能快
- 決策支持:這些數據是否能在決策支持層面發揮作用,特別是從 DevOps 的角度
- 數據可視化:做到不用看日誌通過可視化進行篩選
實現功能
- 故障定位:調用鏈路跟蹤,一次請求的邏輯軌跡可以完整清晰的展示出來。
- 性能分析:調用鏈的各個環節分別添加調用耗時,可以分析出系統的性能瓶頸,並針對性的優化。
- 數據分析:調用鏈是一條完整的業務日誌,可以得到請求的行為路徑,匯總分析應用在很多業務場景
設計思路
對於上面那些問題,業內已經有了一些具體實踐和解決方案。通過調用鏈的方式,把一次請求調用過程完整的串聯起來,這樣就實現了對請求鏈路的監控。
在業界,目前已知的分布式跟蹤系統,比如「Twitter Zipkin 與淘寶鷹眼」,設計思想都是來自 Google Dapper 的論文 「Dapper, a Large-Scale Distributed Systems Tracing Infrastructure」
典型分布式調用過程
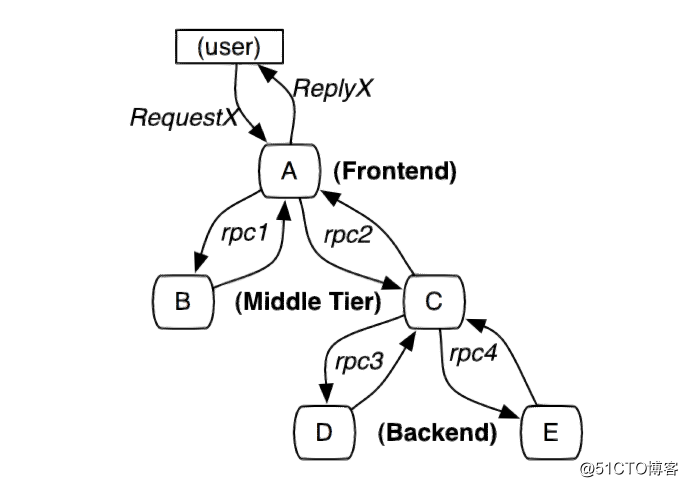
圖1:這個路徑由用戶的X請求發起,穿過一個簡單的服務系統。用字母標識的節點代表分布式系統中的不同處理過程。
分布式服務的跟蹤系統需要記錄在一次特定的請求後系統中完成的所有工作的信息。舉個例子,圖1展現的是一個和5臺服務器相關的一個服務,包括:前端(A),兩個中間層(B和C),以及兩個後端(D和E)。當一個用戶(這個用例的發起人)發起一個請求時,首先到達前端,然後發送兩個 RPC 到服務器 B 和 C 。B 會馬上做出反應,但是 C 需要和後端的 D 和 E 交互之後再返還給 A ,由 A 來響應最初的請求。對於這樣一個請求,簡單實用的全鏈路跟蹤的實現,就是為服務器上每一次你發送和接收動作來收集與跟蹤
調用鏈路關系圖
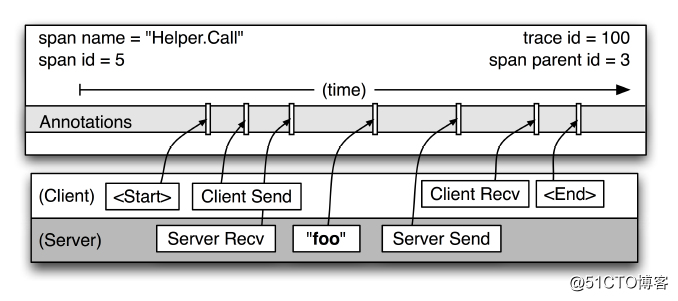
cs - CLIENT_SEND,客戶端發起請求
sr - SERVER_RECIEVE,服務端收到請求
ss - SERVER_SEND,服務端處理完成,發送結果給客戶端
cr - CLIENT_RECIEVE,客戶端收到響應技術選型
| 公司 | 選項 | 是否開源 | 優缺點 |
|---|---|---|---|
| 淘寶 | EagleEye | 否 | 主要基於內部 HSF 實現,HSF 沒有開源,故鷹眼也沒有開源 |
| Zipkin | 是 | 基於 Http 實現,支持語言較多,比較適合我們公司業務 | |
| 點評 | CAT | 是 | 自定義改造難度大,代碼比較復雜,侵入代碼,需要埋點 |
| 京東 | Hydra | 是 | 主要基於 Dubbo 實現,不適合公司 Http 請求為主的場景 |
綜上,考慮到公司目前以 Http 請求為主的場景,最終決定采用參考 Zipkin 的實現思路,同時以 OpenTracing 標準來兼容多語言客戶端
系統設計
整體架構圖及說明
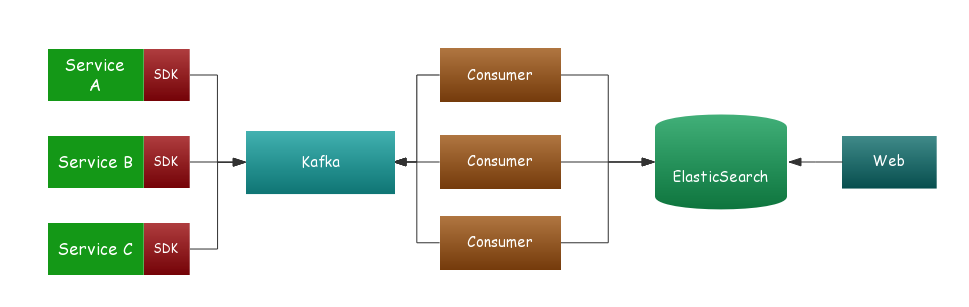
一般全鏈路跟蹤系統主要有四個部分:數據埋點、數據傳輸、數據存儲、查詢界面
數據埋點
- 通過集成 SDK 到滬江統一開發框架中,進行低侵入性的數據收集
- 采用 AOP 切面方式,將收集的數據存儲在本地線程變量 ThreadLocal 中,對應用透明
- 數據記錄 TraceId、事件應用、接口、開始時間、耗時
- 數據采用異步線程隊列的方式發送到 Kafka 隊列中,減少對業務的影響
目前支持的中間件有:
- Http 中間件
- Mysql 中間件
- RabbitMQ 中間件
數據傳輸
我們在 SDK 與後端服務之間加了一層 Kafka ,這樣做既可以實現工程解耦,又可以實現數據的延遲消費,起到削峰填谷的作用。我們不希望因為瞬時 QPS 過高而導致數據丟失,當然為此也付出了一些實效性上的代價。
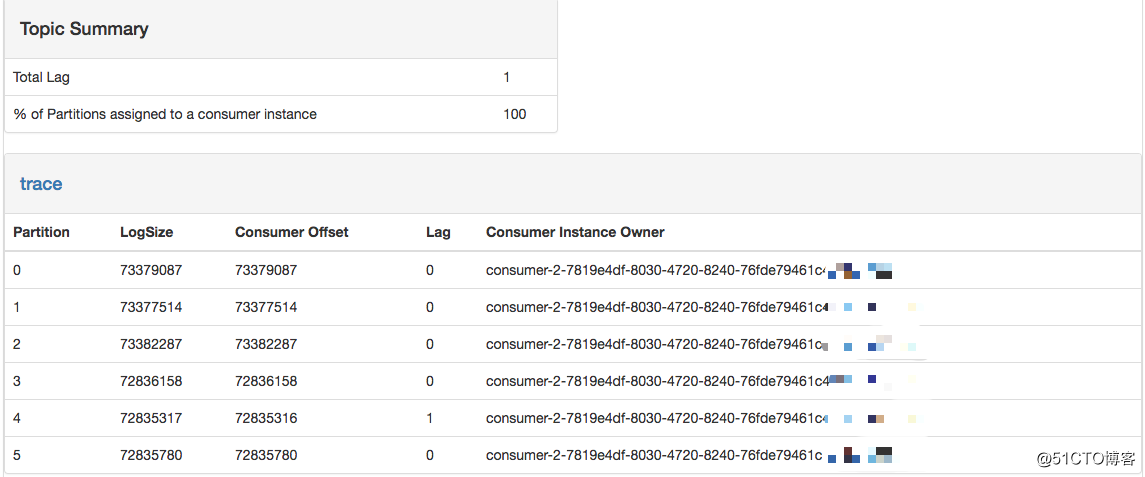
Kafka Manager 展示
數據存儲
數據存儲采用 ElasticSearch ,主要存儲 Span 與 Annotation 相關的數據,考慮到數據量的規模,先期只保存最近 1 個月的數據。
ELasticSearch Head 數據

查詢界面
通過可視化 Web 界面來查詢分布式調用鏈路,同時還提供根據項目維度分析依賴聚合
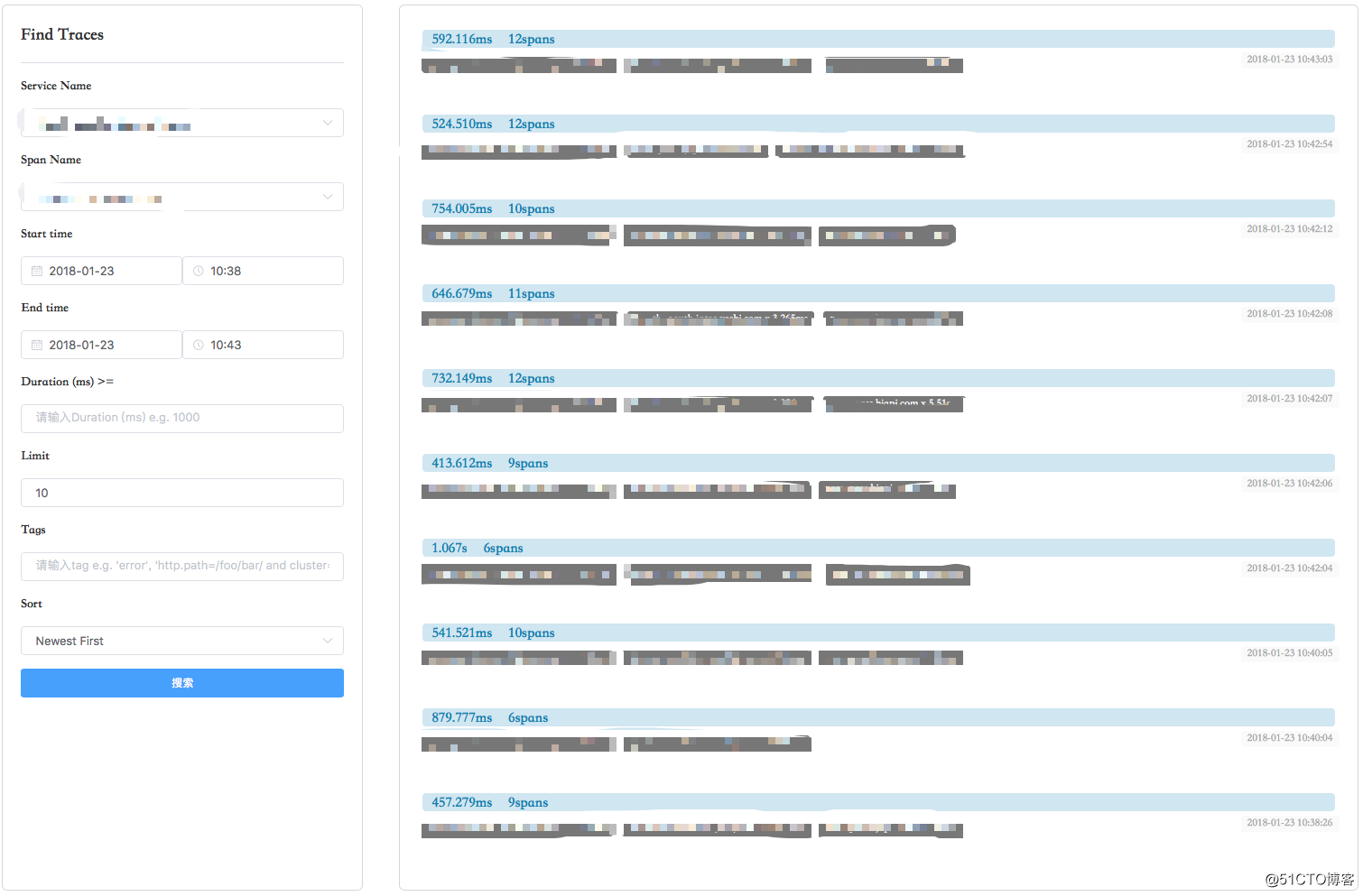
查詢頁面
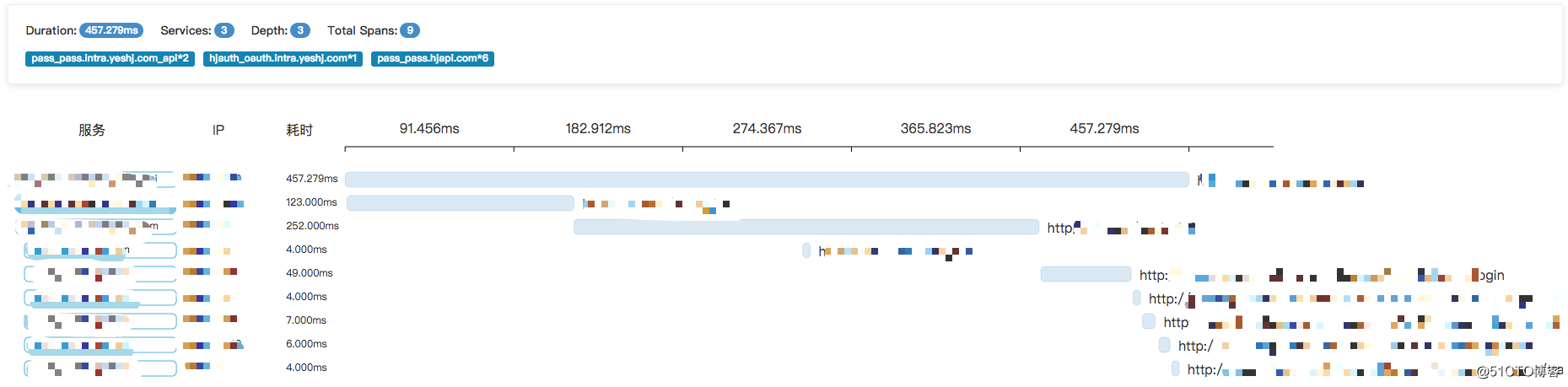
Trace 樹
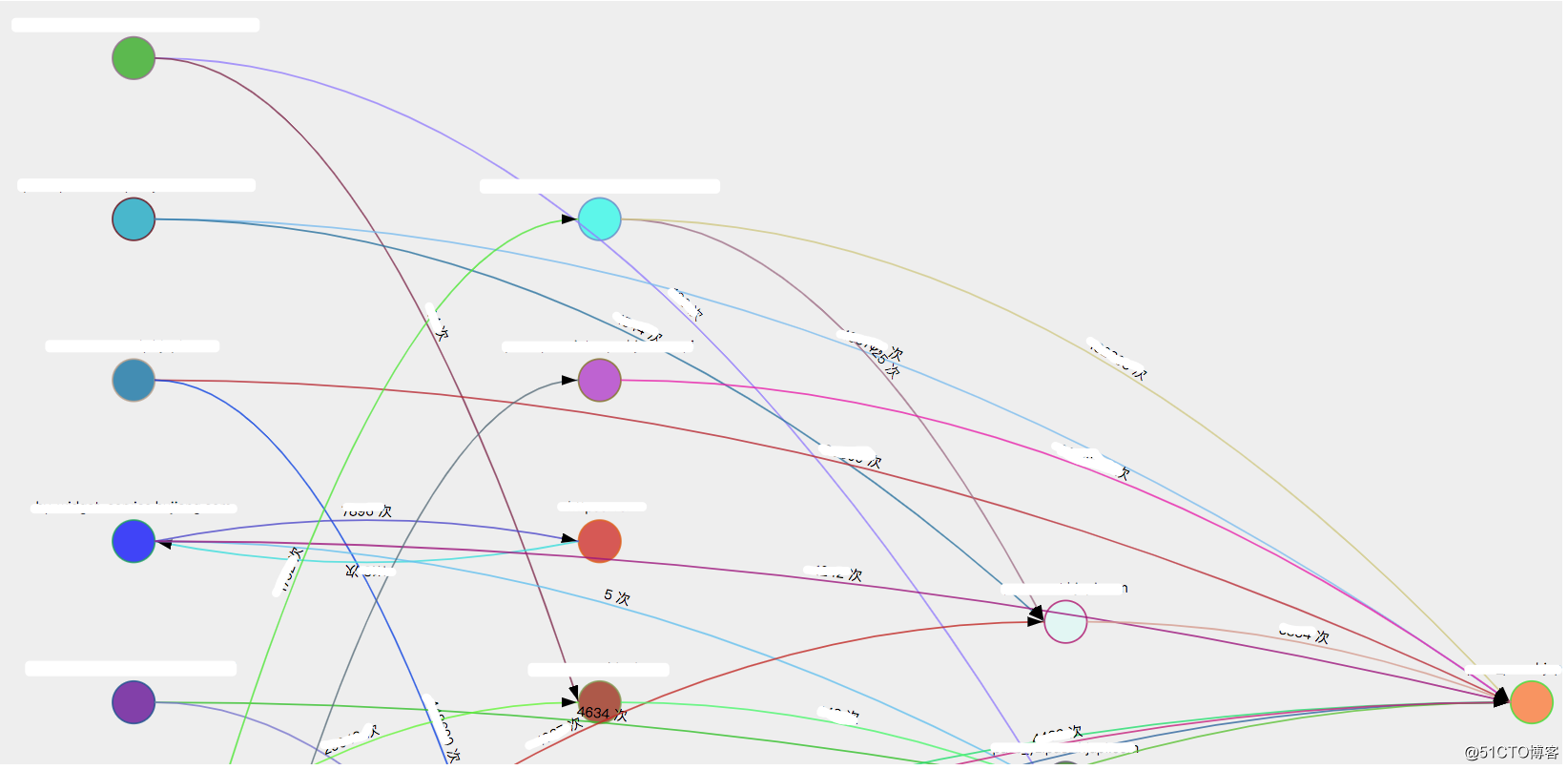
依賴分析
遇到的一些坑
Web 頁面加載超時
問題
使用 Zipkin 官網 UI 的時候,會偶發性的出現業務加載超時。
解決方案
原因是 Zipkin 加載頁面的時候會一次性加載該項目裏面所有的 Span ,當項目使用 Restful 形式的 API 時,就會產生幾百萬的 Span。最後,我們重寫 UI 頁面采用懶加載的方式,默認展示最近 10 條 Span,同時支持輸入字符來動態查詢 Span 的功能。
Span 堆積過多
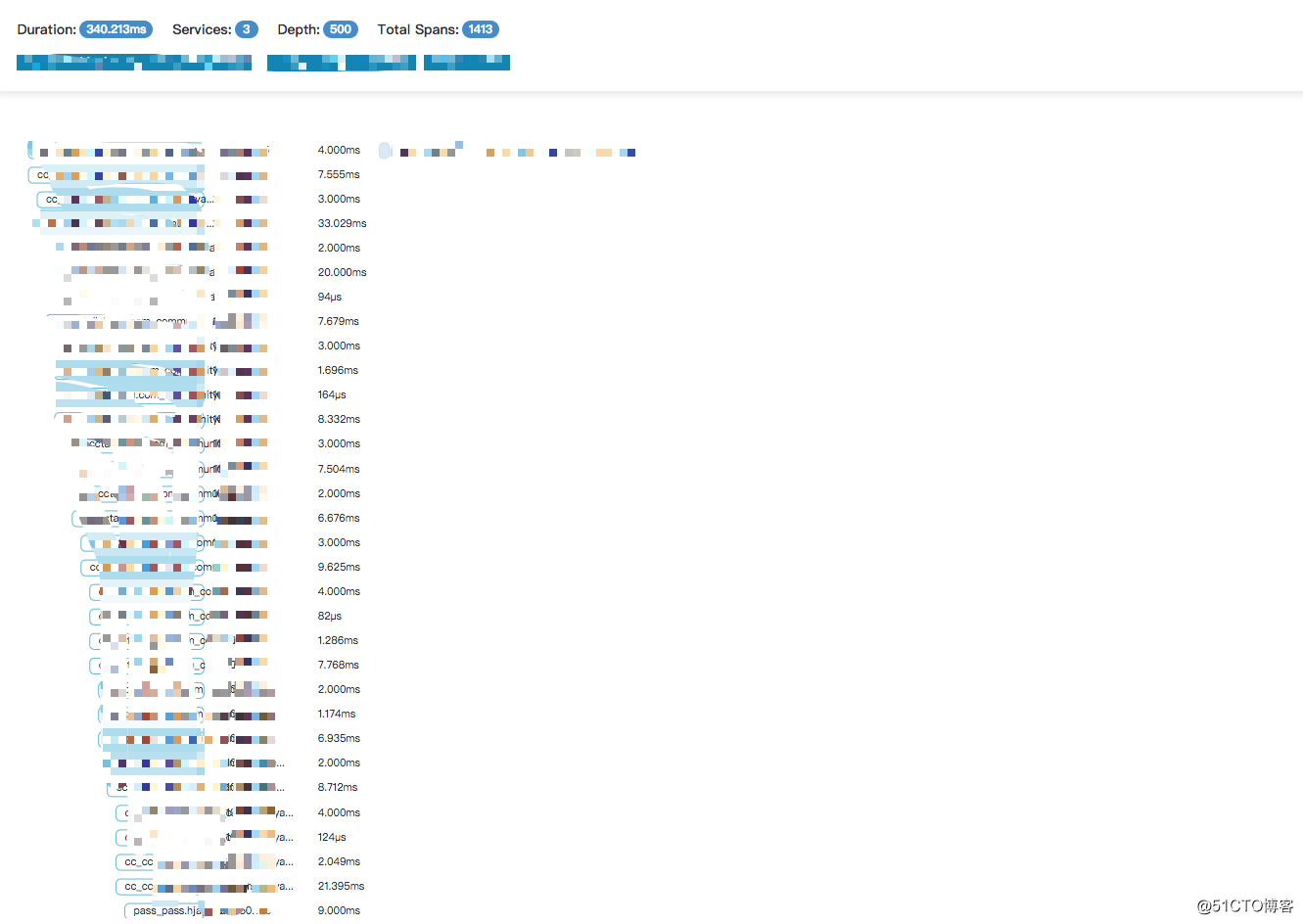
問題
當使用頁面查詢 Trace 的時候,發現某個鏈路堆積到上千條 Span
解決方案
排查下來,業務方使用 HttpClient 中間件發送 Http 請求超時的時候,SDK 並未攔截超時對應的異常,導致事件一直在存儲在線程對應的 ThreadLocal 中
總結
全鏈路跟蹤系統關鍵點:調用鏈。
每次請求都生成全局唯一的 TraceID,通過該 ID 將不同的系統串聯起來。實現調用鏈跟蹤,路徑分析,幫助業務人員快速定位性能瓶頸,排查故障原因。
參考資料
- Google Dapper http://bigbully.github.io/Dapper-translation/
- Twitter Zipkin
- 窩窩網 Tracing 文章 http://www.cnblogs.com/zhengyun_ustc/p/55solution2.html
全鏈路設計與實踐