
深入淺出高可靠性技術
· 可靠性:Availability,可靠性=MTBF/ (MTBF+MTTR): ○ MTBF(Mean Time Between Failure:平均無故障時間):衡量穩定程度 ○ MTTR(Mean Time to Repair:故障平均修復時間):衡量故障響應修復速度 · 高可靠性的應用: ○ 網絡高可靠性主要是指當設備或網絡出現故障時,網絡提供服務的不間斷性。 1.可靠性達到5 個9 以上; 2.可靠性99.999%意味著每年故障時間不超過5 分鐘; 3.可靠性99.9999%意味著每年故障時間不超過30 秒。 ○ 園區網高可靠性技術: 1.鏈路備份技術; 2.設備備份技術:包含設備自身備份技術以及設備間備份技術; 3.堆疊技術。 · 鏈路備份技術: ○ 鏈路備份技術用於避免由於單鏈路故障導致的網絡通信中斷。當主鏈路中斷後,備用鏈路會成為新的主用鏈路。 ○ 備份技術有三種:鏈路聚合、RRPP、Smart Link。 · 鏈路聚合: ○ 鏈路聚合是把多條物理鏈路聚合在一起,形成一條邏輯鏈路。 ○ 采用鏈路聚合可以提供鏈路冗余性,又可以提高鏈路的帶寬。 **· RRPP**: ○ RRPP(Rapid Ring Protection Protocol,快速環網保護協議)是一個專門應用於以太網環的鏈路層協議。 ○ 在以太網環上一條鏈路斷開時,RRPP能迅速恢復環網上各個節點之間的通信通路,具備較高的收斂速度。 ** Smart Link**: Smart Link 解決方案,實現了主備鏈路的冗余備份,具備快速收斂性能,收斂速度可達到亞秒級。 · 設備備份技術: ○ 設備備份技術用於避免由於單設備故障導致的網絡通信中斷。當主設備中斷後,備用板卡或備用設備會成為新的主設備。 ○ 技術:1.設備自身的備份技術; 2.設備間的備份技術VRRP。 · 設備自身的備份技術: ○ 主備備份指備用主控板作為主用主控板的一個完全映象,除了不處理業務,不控制系統外,其它與主用主控板保持完全同步。 ○ 當主用板發生故障或者被拔出時,備用板將迅速自動取代主用板成為新的主用板,以保證設備的繼續運行。 ○ 主備備份應用於分布式網絡產品的主控板,提高網絡設備的可靠性。 · 設備間的備份技術VRRP: VRRP 將可以承擔網關功能的路由器加入到備份組中,形成一臺虛擬路由器。 · **IRF**(Intelligent Resilient Framework,智能彈性架構) 是將多臺設備通過堆疊口連接在一起形成一臺“聯合設備”。用戶對這臺“聯合設備”進行管理,可以實現對堆疊中的所有設備進行管理。 · IRF 高可靠性: ○ 堆疊系統由多臺成員設備組成,Master 設備負責堆疊的運行、管理和維護,Slave 設備在作為備份的同時也可以處理業務。 ○ 一旦Master 設備故障,系統會迅速自動選舉新的Master,以保證通過堆疊的業務不中斷,從而實現了設備級的1:N 備份。 ○ 成員設備之間物理堆疊口支持聚合功能,堆疊系統和上、下層設備之間的物理連接也支持聚合功能,這樣通過多鏈路備份提高了堆疊系統的可靠性。
二. 鏈路聚合
· 鏈路聚合的產生
○ 鏈路聚合是把多條物理鏈路聚合在一起,形成一條邏輯鏈路。
○ 采用鏈路聚合可以提供鏈路冗余性,又可以提高鏈路的帶寬。
· 鏈路聚合在IEEE 802.3 結構中的位置,是處於MAC CLIENT 和MAC 之間,一個可選的子層。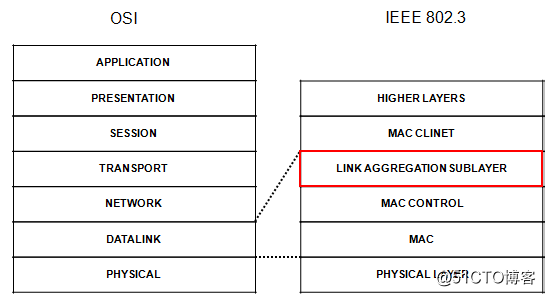
· 鏈路聚合的相關概念:
○ 聚合接口:是一個手工配置的邏輯接口,鏈路聚合組是隨著聚合接口的創建而自動生成的。
○ 聚合組:是一組以太網接口的集合。
○ 聚合成員端口的狀態:Selected狀態(可以轉發數據),Unselected狀態(不能能轉發數據)。
○ 操作Key:操作Key 是在鏈路聚合時,聚合控制根據成員端口的某些配置自動生成的一個配置組合,包括端口屬性配置(包含端口速率、雙工模式和鏈路狀態配置)和第二類配置
○ 第二類配置:包含:端口隔離、QinQ配置、VLAN配置、MAC地址學習配置,如果成員端口與聚合端口的第二類配置不同的,該成員端口不能成為Selected端口。
· LACP(Link Aggregation Control Protocol)鏈路聚合控制協議:
○ LACP 協議通過LACPDU(Link Aggregation ControlProtocol Data Unit,鏈路聚合控制協議數據單元)與對端交互信息。
○ 鏈路的兩端分別稱為Actor和Partner,雙方通過交換LACPDU報文,與其他端口比較系統的優先級,系統MAC地址、端口優先級。端口號、 操作Key。選擇能夠匯聚的端口,從而雙方可以對接口處於Selected 狀態達成一致。
聚合接口的速率是Selected 成員端口的速率之和,聚合接口的雙工狀態與Selected 成員端口的雙工狀態一致。
· 鏈路聚合模式:
○ 靜態聚合模式:
§ 端口不與對端設備交互信息。
§ 選擇參考端口根據本端設備信息。
§ 用戶命令創建和刪除靜態聚合組。
○ 動態聚合模式:
§ 端口的LACP 協議自動使能,與對端設備交互LACP 報文。
§ 選擇參考端口根據本端設備與對端設備交互信息。
§ 用戶命令創建和刪除動態聚合組。
· 靜態聚合流程: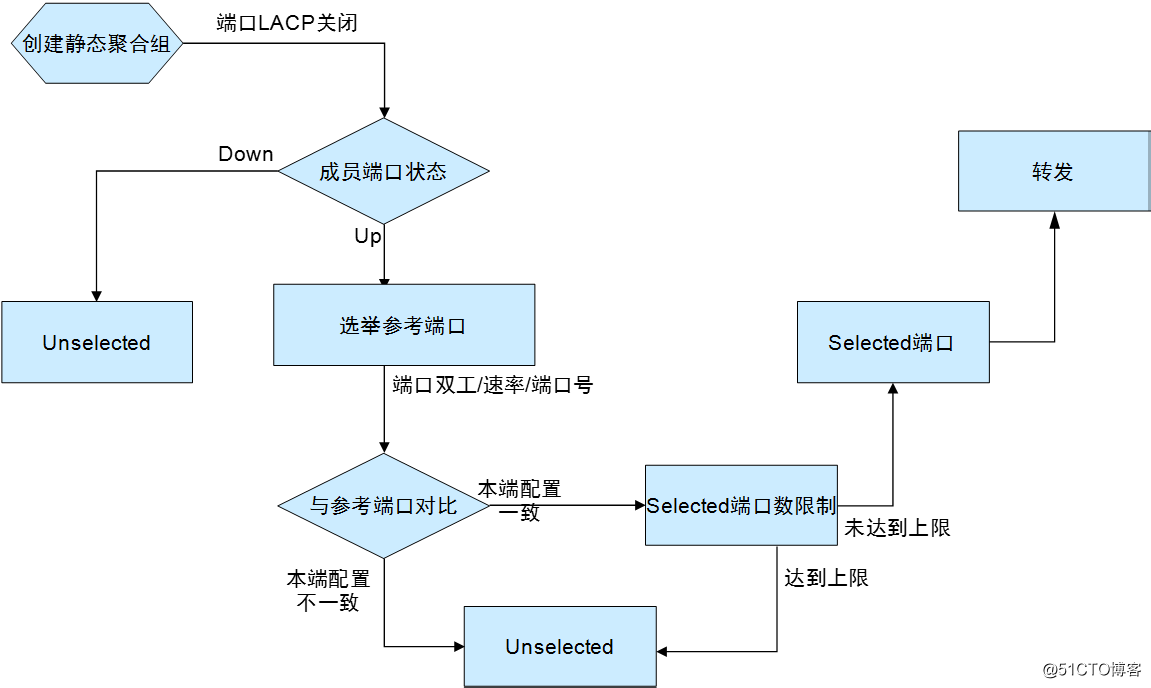
○ 當聚合組內有處於up 狀態的端口時,系統按照端口全雙工/高速率、全雙工/低速率、半雙工/高速率、半雙工/低速率的優先次序,選擇優先次序最高且處於up狀態的、端口的第二類配置和對應聚合接口的第二類配置相同的端口作為該組的參考端口(優先次序相同的情況下,端口號最小的端口為參考端口)。
○ 與參考端口的端口屬性配置和第二類配置一致且處於up狀態的端口成為可能處於Selected狀態的候選端口,其它端口將處於Unselected 狀態。
○ 聚合組中處於Selected 狀態的端口數是有限制的,當候選端口的數目未達到上限時,所有候選端口都為Selected 狀態,其它端口為Unselected 狀態;當候選端口的數目超過這一限制時,系統將按照端口號從小到大的順序選擇一些候選端口保持在Selected 狀態,端口號較大的端口則變為Unselected 狀態。
○ 因硬件限制(如不能跨板聚合)而無法與參考端口聚合的端口將處於Unselected 狀態。
· 動態聚合流程: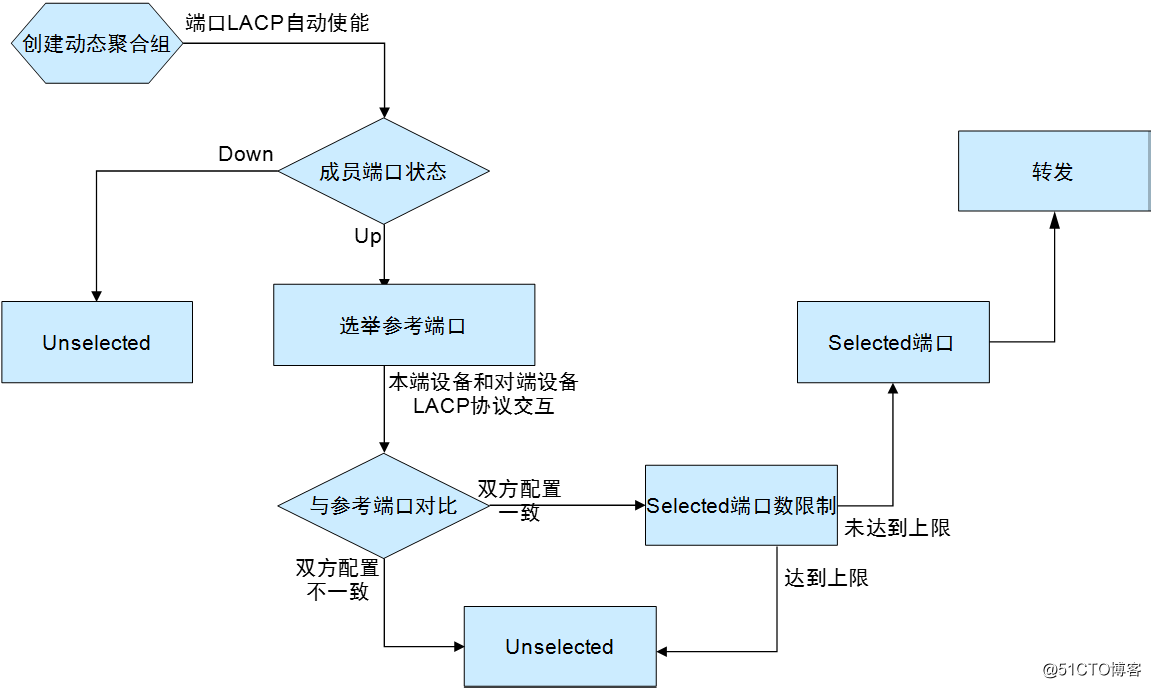
○ 比較兩端系統的設備ID(設備ID=系統的LACP 協議優先級+系統MAC 地址)。先比較系統的LACP 協議優先級,如果相同再比較系統MAC 地址。設備ID 小的一端被認為較優(系統的LACP 協議優先級和MAC 地址越小,設備ID 越小)。
○ 比較設備ID 較優的一端的端口ID(端口ID=端口的LACP 協議優先級+端口號)。對於設備ID 較優的一端的各個端口,首先比較端口的LACP 協議優先級,如果優先級相同再比較端口號。端口ID 小的端口作為參考端口(端口的LACP 協議優先級和端口號越小,端口ID 越小)。
○ 與參考端口的端口屬性配置和第二類配置一致且處於up 狀態的端口、並且該端口的對端端口與參考端口的對端端口的配置也一致時,該端口才成為可能處於Selected 狀態的候選端口。否則,端口將處於Unselected 狀態。
○ 聚合組中處於Selected 狀態的端口數是有限制的,當候選端口的數目未達到上限時,所有候選端口都為Selected 狀態,其它端口為Unselected 狀態;當候選端口的數目超過這一限制時,系統將按照端口ID 從小到大的順序選擇一些端口保持在Selected 狀態,端口ID 較大的端口則變為Unselected 狀態。同時,對端設備會感知這種狀態的改變,相應端口的狀態將隨之變化。
○ 因硬件限制(如不能跨板聚合)而無法與參考端口聚合的端口將處於Unselected 狀態。
· 靜態聚合組配置命令:
○ 創建二層聚合端口,聚合組默認工作在靜態聚合模式:
[Switch] interface bridge-aggregation interface-number
○ 將以太網端口加入聚合組:
[Switch-Ethernet1/0/1] port link-aggregation group number
· 動態聚合組配置命令:
○ 創建二層聚合端口:
[Switch] interface bridge-aggregation interface-number
○ 配置聚合組工作在動態聚合模式下:
[Switch-Bridge-Aggregation1] link-aggregation mode dynamic
○ 將以太網端口加入聚合組:
[Switch-Ethernet1/0/1] port link-aggregation group number
○ 配置系統的LACP 協議優先級:
[Switch] lacp system-priority system-priority
○ 配置端口的LACP 協議優先級:
[Switch-Ethernet1/0/1] lacp port-priority port-priority
○ 配置聚合組的聚合負載分擔模式:
[Switch] link-aggregation load-sharing mode { destination-ip | destination-mac | destination-port | ingress-port | source-ip | source-mac | source-port }三. smart link和monitor link
· Smart Link:
Smart Link 解決方案,實現了主備鏈路的冗余備份,具備快速收斂性能,收斂速度可達到亞秒級。
· Smart Link相關概念:
○ Smart Link 組:也稱為靈活鏈路組,一個Smart Link 組包含兩個成員端口,其中一個被指定為主端口(Master Port),另一個被指定為副端口(Slave Port),不同的Smart Link 組可以包含同一個端口。正常情況下,只有一個端口(主端口或副端口)處於轉發(ACTIVE)狀態,另一個端口被阻塞(BLOCK),處於待命(STANDBY)狀態。可能主端口被阻塞,但仍是主端口。
○ Flush報文:Smart Link組通過發送Flush報文通知其他設備進行MAC地址轉發表和ARP/ND表項的刷新操作。
○ 保護VLAN: 是Smart Link 組內承載數據流量的用戶數據VLAN。端口可以加入多個Smart Link 組,這些Smart Link 組保護不同的VLAN。各Smart Link 組分別獨立計算組內端口的轉發狀態。是通過引用MSTP 實例來實現的。
○ 發送控制VLAN(Control VLAN):是Smart Link 組用於廣播發送FLUSH 報文。
○ 接收控制VLAN: 是上遊設備用於接收並處理FLUSH 報文的VLAN。
· FLUSH 報文格式:
○ Destination MAC :為未知組播地址。可以通過判斷該地址是否為0x010FE200-0004 來區分該報文是否為FLUSH 報文。
○ Source MAC :表示發送FLUSH 報文的設備的橋MAC 地址。
○ Control Type: 表示控制類型。目前只有刪除MAC 地址轉發表項和ARP 表項一種(0x01)。
○ Control Version: 表示版本號。當前版本號為0x00,用於後續版本的擴展。
○ Device ID :表示發送FLUSH 報文的設備的橋MAC 地址。
○ Control VLAN ID :表示發送控制VLAN 的ID 號。
○ Auth-mode: 表示認證模式,和Password 一起使用,便於以後進行安全性擴展。
○ VLAN Bitmap :表示VLAN 位圖,用於攜帶需要刷新地址表的VLAN 列表。
○ FCS :表示幀校驗和,用於檢查報文的合法性。
· MAC 及ARP 更新的機制目前有以下兩種:
○ 由Smart Link 組從新的鏈路上發送FLUSH 報文進行刷新,流量不會中斷:
與支持Smart Link功能的設備對接Smart Link功能,設備由Smart Link 組從新的鏈路上發送FLUSH 報文進行刷新表項
1.當上遊設備收到FLUSH 報文時,判斷該FLUSH 報文的發送控制VLAN 是否在收到報文的端口配置的接收控制VLAN 列表中。
2.如果不在接收控制VLAN 列表中,設備對該FLUSH 報文不做處理,直接轉發;
3.如果在接收控制VLAN 列表中,設備將提取FLUSH 報文中的VLAN Bitmap 數據,將設備在這些VLAN 內學習到的MAC 及ARP 表項刪除。
4.對於需要進行二層轉發的報文,該設備會通過二層廣播方式進行轉發;
5.對於需要進行三層轉發的報文,設備會通過ARP 探測方式先更新ARP 表項,然後將報文轉發出去。
○ 自動通過流量刷新(表項自動老化、重新學習)但刷新期間流量會中斷。
與不支持Smart Link功能的設備對接Smart Link功能,設備自動通過流量刷新表項。
· Smart Link 組支持兩種模式:
○ 角色搶占模式、
當主用鏈路故障恢復後,主端口將搶占為轉發狀態,副端口則進入待命狀態。
只有當主用鏈路故障時,副端口才會從待命狀態切換到轉發狀態。
○ 非角色搶占模式
當主用鏈路故障恢復後,副端口將繼續處於轉發狀態,主端口繼續處於待命狀態,這樣可以保持流量的穩定。
· 通過Smart Link 實現流量的負載分擔:
○ 在同一個雙上行鏈路組網中,可能同時存在多個VLAN 的數據流量,Smart Link 可以實現流量的負載分擔,即不同VLAN 的流量沿不同的路徑進行轉發。通過把上行鏈路的端口分別配置為兩個Smart Link 組的成員(每個Smart Link 組的保護VLAN 不同),且端口在不同組中的轉發狀態不同,這樣就能實現不同Smart Link 組保護VLAN 的流量轉發路徑不同,從而達到負載分擔的目的。
○ 在實現負載分擔時,建議將Smart Link 組配置為角色搶占模式,否則無法保證流量按照用戶的想法一直在兩條鏈路上進行分擔。因為,如果配置為非角色搶占模式,剛開始可以實現流量分流,但鏈路故障後所有流量將集中在同一條鏈路上傳輸,鏈路恢復後流量繼續在同一條鏈路上傳輸,這樣就無法達到負載分擔的目的。
· Monitor Link產生
當交換機的上行端口所在鏈路出現故障時配置,Smart Link 組的設備由於主端口未發生故障,不會出現鏈路切換,導致流量中斷。
· Monitor Link 概念:
Monitor Link 組:也叫監控組,每個組由上行鏈路和下行鏈路共同組成,成員角色由用戶決定。
上行鏈路(Uplink):是Monitor Link 組被監控的鏈路。
下行鏈路(Downlink):是Monitor Link 組的受動鏈路。
· Monitor Link 運作機制:
○ 當Monitor Link 組中所有上行鏈路成員端口都為Down 時,將強制使其下行鏈路成員端口都為Down 狀態。
○ 當Monitor Link 組中只要有一個上行鏈路成員端口從Down 轉為Up 狀態時,將使下行鏈路成員端口都恢復為Up 狀態。
即(下行端口(Downlink Port)的狀態隨上行端口(Uplink Port)狀態的變化而變化)。
· Smart Link 組配置命令:
○ 創建Smart Link 組:
[Switch] smart-link group group-id
○ 配置Smart Link 組的保護VLAN:
[Switch-smlk-group1] protected-vlan reference-instance instance-id-list
○ 開啟發送Flush 報文功能:
[Switch-smlk-group1] flush enable [ control-vlan vlan-id ]
○ 配置Smart Link 組成員端口:
[Switch-smlk-group1] port interface-type interface-number { master | slave }
○ 端口視圖下配置Smart Link 組的成員端口:
[Switch-Ethernet1/0/1] port smart-link group group-id { master | slave }
○ 配置Smart Link 搶占功能:
[Switch-smlk-group1] preemption mode role
· Monitor Link 組配置命令:
○ 創建Monitor Link 組:
[Switch] monitor-link group group-id
○ 在Monitor Link 組視圖下配置上行鏈路成員:
[Switch-mtlk-group1] port interface-type interface-number uplink
○ 在Monitor Link 組視圖下配置下行鏈路成員:
[Switch-mtlk-group1] port interface-type interface-number downlink
○ 在端口視圖下配置Monitor Link 組上行鏈路成員:
[Switch-Ethernet1/0/1] port monitor-link group group-id uplink
○ 在端口視圖下配置Monitor Link 組下行鏈路成員:
[Switch-Ethernet1/0/1] port monitor-link group group-id downlink四. RRPP
· RRPP功能:
○ RRPP(Rapid Ring Protection Protocol,快速環網保護協議)是一個專門應用於以太網環的鏈路層協議。
○ 拓撲收斂速度快(低於50ms),收斂時間與環網上節點數無關。
· H3C 所實現的RRPP 協議還有如下特點:
○ 在相交環拓撲中,一個環拓撲的變化不會引起其他環的拓撲振蕩,數據傳輸更為穩定。
○ 支持RRPP 環網的負載分擔,充分利用了物理鏈路的帶寬。
· RRPP基本概念:
○ RRPP域:具有相同的域ID和控制VLAN且相互連通的設備構成一個RRPP域。
○ RRPP 環:是一個環形連接的以太網網絡拓撲。
○ 節點:RRPP環上的每一臺設備都是一個節點。
○ 主節點:每個環有且僅有一個主節點,主節點是環網狀態主動檢測機制的發起者,也是檢測到RRPP環故障後執行操作的決策者。
○ 傳輸節點:RRPP 環上除主節點外的所有其它節點是傳輸節點,傳輸節點負責透傳主節點的HELLO 報文,並監測自己的直連RRPP 鏈路的狀態,把鏈路DOWN 事件通知主節點。
○ 邊緣節點:同時位於主環和子環上的節點,在主環上是傳輸節點,在子環上是邊緣節點。
○ 輔助邊緣節點:同時位於主環和子環上的節點,在主環上是傳輸節點,在子環上是輔助邊緣節點。用於檢測主環完整性和進行環路預防。
○ 控制VLAN:是用來傳遞RRPP 協議報文的VLAN。
○ 數據VLAN:是用來傳遞數據報文的VLAN。
○ 主端口和副端口:主節點和傳輸節點個子有兩個端口接入RRPP環,其中一個為主端口,另一個為副端口,主節點上的主端口用來發送探測環路的報文,副端口用來接受該報文,在RRPP環處於健康狀態時,副端口處在邏輯上阻塞數據VLAN,只允許控制VLAN報文通過,當RRPP換處於撕裂狀態時,主節點的副端口將解除數據VLAN的阻塞狀態,傳輸節點的主端口和副端口都用來傳輸數據VLAN和控制VLAN的。
○ 公共端口和邊緣端口:公共端口是邊緣節點和輔助邊緣節點接入主環的端口,邊緣端口是邊緣節點和輔助邊緣節點接入子環的端口。
· 環形物理拓撲常見的三種組網形式為:
○ 每個RRPP 環都是其所在的RRPP 域的一個局部單元。
○ 單環、相交環、相切環。
· 主節點有如下兩種狀態:
○ Complete State(完整狀態):當環網上所有的鏈路都處於UP 狀態,主節點可以從副端口收到自己發送的HELLO 報文,就說主節點處於Complete 狀態,此時主節點會阻塞副端口以防止數據報文在環形拓撲上形成廣播環路。
○ Failed State(故障狀態):當環網上有鏈路處於故障狀態時,主節點處於Failed 狀態,此時主節點的副端口放開對數據報文的阻塞,以保證環網上的通信不中斷。
○ 主節點的狀態代表了整個RRPP 環的狀態。即,主節點處於Complete(Failed)狀態時,RRPP 環也處於Complete(Failed)狀態。
· 傳輸節點有如下3 種狀態:
○ Link-Up State(UP 狀態):傳輸節點的主端口和副端口都處於UP 狀態時,就說傳輸節點處於Link-Up 狀態。
○ Link-Down State(Down 狀態):傳輸節點的主端口或副端口處於Down 狀態時,就說傳輸節點處於Link-Down 狀態。
○ Preforwarding State(臨時阻塞狀態):傳輸節點的主端口或副端口處於阻塞狀態時,就說傳輸節點處於Pre-forwarding 狀態。
· RRPP 運作機制:
○ Polling 機制:RRPP 環的主節點主動檢測環網健康狀態的機制。
○ 鏈路狀態變化通知機制:提供了比Polling機制更快環網拓撲改變的處理機制,發起者是傳輸節點。
· 環網故障可以通過兩種方式檢測出來:
○ 輪詢機制:主節點通過輪詢機制來主動檢測環網狀態:主節點周期性的從其主端口發送HELLO 報文,依次經過各傳輸節點在環上傳播。如果主節點在規定時間內收不到自己發送的HELLO 報文,認為環網發生鏈路故障。主節點將狀態切換到Failed 狀態,放開副端口,並從主、副端口發送COMMON-FLUSH-FDB 報文通知環上所有傳輸節點刷新MAC 表項和ARP/ND 表項。
○ Link Down 通知機制:節點總是在監測自己的端口鏈路狀態,一旦發現端口Down 將立即采取措施:當傳輸節點上的RRPP 端口發生鏈路DOWN 時,該節點將從與故障端口配對的狀態為UP 的RRPP 端口發送LINK-DOWN 報文通知主節點(LINK-DOWN 上主節點收到LINK-DOWN 報文後,放開副端口,立即將狀態切換到Failed 狀態。由於網絡拓撲發生改變,主節點還需要刷新MAC 表項和ARP/ND表項, 並從主、副端口發送COMMON-FLUSH-FDB 報文通知所有傳輸節點刷新MAC 表項ARP/ND 表項。
· 環網故障恢復檢測及處理機制:
○ 傳輸節點端口恢復的瞬間,主節點還不能馬上知道這一信息,因此其副端口還處於放開狀態。這時如果傳輸節點立即遷移回Link-Up 狀態,勢必造成數據報文在環網上形成瞬時環路,因此處於Link-Down 狀態的傳輸節點的主、副端口都恢復時,傳輸節點立即阻塞剛剛恢復的端口,遷移到Pre-forwarding狀態。環網恢復的過程是由主節點主動發起的。環上所有鏈路恢復正常後,當處於Failed 狀態的主節點重新收到自己發出的HELLO 報文,將阻塞副端口,將狀態遷移回Complete狀態。
○ 鏈路狀態變化通知機制的缺陷:
若雙歸屬的兩個子環借助邊緣節點相互連接,則當主環故障發生後,兩個子環的主節點副端口都放開,會形成環路。
○ 主環上子環協議報文通道狀態檢查機制:
主環上子環協議報文通道狀態檢測機制,是在子環主節點副端口放開之前,阻塞邊緣節點的邊緣端口,從而避免子環間形成數據環路。
○ 環組機制:
為減少Edge-Hello 報文的收發數量,將邊緣節點和輔助邊緣節點上的兩個RRPP環配置為一個環組。
· 報文類型說明
○ Health(Hello) :健康檢測報文,由主節點發起,對網絡進行環路完整性檢測。
○ Link-Down:鏈路Down 報文,由發生直連鏈路狀態Down的傳輸節點、邊緣節點或者輔助邊緣節點發起,通知主節點環路上有鏈路Down,物理環路消失。
○ Common-Flush-Fdb:刷新Fdb 報文,由主節點發起,通知傳輸節點、邊緣節點或者輔助邊緣節點更新各自Mac地址轉發表。
○ Complete-Flush-Fdb:環網恢復刷新Fdb 報文,由主節點發起,通知傳輸節點、邊緣節點或者輔助邊緣節點更新各自Mac 地址轉發表,同時通知傳輸節點放開臨時阻塞端口。
○ Edge-Hello:主環完整性檢查報文,由子環的邊緣節點發起,同子環的輔助邊緣節點接收,子環通過此報文檢查其所在域主環的環路完整性。
○ Major-Fault:主環故障通知報文,當子環的輔助邊緣節點在規定時間內收不到邊緣節點發送的
○ Edge-Hello:報文時發起,向邊緣節點報告其所在域主環發生故障。
· RRPP 配置命令:
○ 創建RRPP 域:
[Switch] rrpp domain domain-id
○ 配置控制VLAN:
[Switch-rrpp-domain1] control-vlan vlan-id
○ 配置保護VLAN:
[Switch-rrpp-domain1] protected-vlan reference-instance instance-id-list
○ 配置主節點:
[Switch-rrpp-domain1] ring ring-id node-mode master [ primary-port interface-type interface-number ] [ secondary-port interface-type interface-number ] level level-value
○ 配置傳輸節點:
[Switch-rrpp-domain1] ring ring-id node-mode transit [ primary-port interface-type interface-number ] [ secondary-port interface-type interface-number ] level level-value
○ 配置邊緣節點:
[Switch-rrpp-domain1] ring ring-id node-mode edge [ edge-port interface-type interface-number ]
○ 配置輔助邊緣節點:
[Switch-rrpp-domain1] ring ring-id node-mode assistant-edge [ edge-port interface-type interface-number ]
○ 使能RRPP 協議:
[Switch] rrpp enable
○ 使能RRPP 環:
[Switch-rrpp-domain1] ring ring-id enable
○ 創建RRPP 環組:
[Switch] rrpp ring-group ring-group-id
○ 將子環加入RRPP 環組:
[Switch-rrpp-ring-group1] domain domain-id ring ring-id-list五. VRRP
· VRRP 負載分擔:
VRRP 將多臺路由器同時承擔業務,形成多臺虛擬路由器,分擔內網與外網之間的流量。
· VRRP 概述:
○ RFC 3768 定義的VRRPv2是一種容錯協議,在提高可靠性的同時,簡化了主機的配置。
○ VRRP 協議報文使用固定的組播地址224.0.0.18進行發送。
○ 虛擬路由器由LAN 上唯一的VirtualRouter ID 標識。並具有虛MAC 地址:00-00-5E-00-01-{vrid}。
· VRRP相關概念:
○ VRRP 備份組:將局域網內的一組運行VRRP協議路由器劃分在一起,稱為一個備份組,功能相當於一臺虛擬路由器。
○ 虛擬路由器號(VRID):虛擬路由器的標識。有相同VRID 的一組路由器構成一個虛擬路由器。
○ Master 路由器:虛擬路由器中承擔報文轉發任務的路由器(優先級最高)。
○ Backup 路由器:Master 路由器出現故障時,能夠代替Master 路由器工作的路由器。
○ 虛擬MAC地址(Virtual MAC Address):一個虛擬路由器有一個虛擬MAC地址,格式為:00-00-5E-00-01-{vrid},當虛擬路由器回應ARP請求時,回應的是虛擬MAC地址。
○ IP 地址擁有者:接口IP 地址與虛擬IP 地址相同的路由器被稱為IP 地址擁有者。
○ 優先級(Priority):VRRP根據優先級來確定參與備份組的Master(優先級最優)和Backup路由器,缺省值:100,範圍1-254,0 為系統保留給路由器放棄Master 位置時候使用,255保留給IP地址擁有者。
○ 非搶占方式:如果Backup 路由器工作在非搶占方式下,則只要Master 路由器沒有出現故障,Backup 路由器即使隨後被配置了更高的優先級也不會成為Master 路由器。
○ 搶占方式:如果Backup 路由器工作在搶占方式下,當它收到VRRP 報文後,會將自己的優先級與通告報文中的優先級進行比較。如果自己的優先級比當前的Master 路由器的優先級高,就會主動搶占成為Master 路由器;否則,將保持Backup 狀態。
○ 認證類型(Authentication Type):無認證、簡單字符認證、MD5認證。
· VRRP 監視接口功能:
○ 當Master 路由器連接上行鏈路的接口處於Down 狀態時,路由器主動降低自己的優先級,使得備份組內重新選擇Master,承擔轉發任務。
§ VRRP 可以利用NQA技術監視上行鏈路連接的遠端主機或者網絡狀況。例如,Master 設備上啟動NQA的ICMP-echo 探測功能,探測遠端主機的可達性。當ICMP echo 探測失敗時,它可以通知本設備探測結果,達到降低VRRP優先級的目的。
§ VRRP 也可以利用BFD技術監視上行鏈路連接的遠端主機或者網絡狀況。由於BFD的精度可以到達10ms,通過BFD能夠快速檢測到鏈路狀態的變化,達到快速搶占的目的。
§ Backup 路由器在Master 路由器壞掉之後,正常情況下需要等待Master_Down_Interval 才能切換為新的Master 的位置,這段時間內主機將無法正常通信。Backup 路由器監視Master 路由器采用的是具有快速檢測功能的BFD 技術。在Backup 設備上使用該技術監視Master 路由器的狀態,一旦Master 路由器發生故障,Backup就可以自動切換成為新的Master路由器,將切換時間縮短到毫秒級。
· VRRP 協議狀態機:
○ Master 狀態:定期發送VRRP廣播報文,響應對虛擬IP地址的ARP請求。
○ Backup 狀態:接受Master發送的VRRP廣播報文,不響應對虛擬IP地址的ARP請求,丟棄目的地址為虛擬MAC地址的IP報文。
○ Initialize(初始化)狀態:不對VRRP報文做任何處理。
· VRRP 相關命令:
○ 配置虛擬IP 地址和MAC 地址的對應關系:
[Switch] vrrp method { real-mac | virtual-mac }此關系需在備份組創建之前設定,否則不允許修改此關系。
○ 創建VRRP 備份組並配置虛擬IP 地址:
[Switch-Ethernet1/0/1] vrrp vrid virtual-router-id virtual-ip virtual-address
○ 配置路由器在備份組中的優先級:
[Switch-Ethernet1/0/1] vrrp vrid virtual-router-id priority priority-value
○ 配置備份組中的路由器工作在搶占方式,並配置搶占延遲時間:
[Switch-Ethernet1/0/1] vrrp vrid virtual-router-id preempt-mode [ timer delay delay-value ]
○ 配置監視指定接口:
[Switch-Ethernet1/0/1] vrrp vrid virtual-router-id track interface interface-type interface-number [ reduced priority-reduced ]
○ 配置備份組發送和接收VRRP 報文的認證:
[Switch-Ethernet1/0/1] vrrp vrid virtual-router-id authentication-mode { md5 | simple } key
○ 配置備份組中Master 路由器發送VRRP 通告報文的時間間隔:
[Switch-Ethernet1/0/1] vrrp vrid virtual-router-id timer advertise adver-interval
○ 顯示VRRP 備份組的狀態信息:
[Switch] display vrrp [ verbose ] [ interface interface-type interface-number [ vrid virtual-router-id ] ]
· 虛擬IP地址不能為0.0.0.0、255.255.255.255、Loopback地址、非A/B/C類地址和其它非法IP地址(0.0.0.1)。虛IP地址和接口ip地址在同一網段,且為合法的主機地址時,備份組才能夠正常工作。否則備份組會始處於Initialize狀態。六. IRF
· IRF產生背景:
○ 盒式設備成本低廉,缺乏不中斷的業務保護,無法應用於重要的場合。
○ 框式分布式設備具有高可用性、高性能、高端口密度的優點,經常被應用於一些重要場合。
· IRF (Intelligent Resilient Framework:智能彈性架構)堆疊:
將多臺設備通過堆疊口連接起來,形成一臺虛擬的邏輯設備。其優點有:簡化管理、提高性能、彈性擴展、高可靠性。
· IRF 堆疊相關概念:
○ Master 設備:IRF 堆疊中的成員設備,負責管理整個堆疊。
○ Slave 設備:IRF 堆疊中的成員設備,隸屬於Master 設備,作為此設備的備份設備運行。
○ 物理堆疊口:成員設備上用於堆疊連接的物理端口。
○ 堆疊口:物理堆疊口需要和邏輯堆疊口綁定。
○ 聚合堆疊口:由多個物理堆疊口聚合的堆疊口。
· IRF 堆疊物理拓撲有兩種:
○ 鏈形拓撲
○ 環形拓撲:具有較高的可靠性。
· IRF堆疊的形成
○ IRF 中的每臺設備都是通過和自己直接相鄰的其它成員設備之間交互IRF Hello 報文來收集整個IRF 的拓撲關系。Hello報文包括堆疊口連接關系、成員設備編號、成員設備優先級、成員設備的成員橋MAC地址等。
○ 拓撲收集完成後,會進入角色選舉階段,確定成員設備角色。
· 角色選舉規則:
○ 當前Master優先於非Master成員。
○ 成員設備均是框式分布式設備時,本地主用板做於本地備用主控板。
○ 成員設備均是框式分布式設備時,原Master備用主控板做於非Master成員上的主控板。
○ 成員優先級大的優先。
○ 系統運行時間長的優先。
○ 成員橋MAC 小的優先。
○ 選舉階段Master會負責成員編號沖突處理、軟件版本加載、堆疊合並管理
· IRF堆疊虛擬設備
○ 盒式設備堆疊後形成的虛擬設備相當於一臺框式分布式設備,堆疊中的Master 相當於虛擬設備的主用主控板,Slave 設備相當於備用主控板。
○ 框式分布式設備堆疊後形成的虛擬設備擁有更多的備用主控板和接口板。
· IRF 堆疊維護的主要功能是:
○ 監控成員設備的加入和離開,並隨時收集新的拓撲,維護現有拓撲。
○ 成員加入:
新加入設備本身未形成堆疊則選為Slave。如形成堆疊,相當於兩個堆疊合並(Merge),進行堆疊競選,失敗的一方所有堆疊成員設備需要重啟。然後全部作用Slave設備加入競選獲勝一方。
○ 判斷成員離開方式:
直接相鄰成員設備定期(200ms)交換Hello報文,如持續多個周期(通常為10個)未收到直接鄰居的Hello報文,則認為該成員離開堆疊系統,將其從拓撲中隔離出來。
如發現堆疊口Down,則擁有該堆疊口的成員設備會緊急廣播通知堆疊中其它成員,立即重新計算當前拓撲不用等到Hello超時。
如離開的是Master設備,會重新進行選舉。
· IRF 的配置同步包括兩個步驟:初始化時的批量同步和穩定運行時的實時同步:
○ 批量同步:
當多臺設備組合形成IRF 時,先選舉出Master 設備。Master 設備使用自己的啟動配置文件啟動,Master 設備啟動完成後,將配置批量同步給所有Slave 設備,Slave 設備完成初始化,IRF 形成;在IRF 運行過程中,有新的成員設備加入時,也會進行批量同步。新設備重啟以Slave 的身份加入IRF,Mater 會將當前的配置批量同步給新設備。新設備以同步過來的配置完成初始化,而不再讀取本地的啟動配置文件。
○ 實時同步:
所有設備初始化完成後,IRF 作為單一網絡設備在網絡中運行。用戶使用Console 口或者Telnet 方式登錄到IRF 中任意一臺成員設備,都可以對整個IRF 進行管理和配置。Master 設備作為IRF 系統的管理中樞,負責響應用戶的登錄請求,即用戶無論使用什麽方式,通過哪臺成員設備登錄IRF,最終都是對Master 設備進行配置。
· IRF 中采用的是1:N 冗余
Master 負責處理業務,多個Slave 作為Master 的備份,隨時與Master 保持同步。
· IRF 堆疊協議熱備份:
在1:N 冗余環境下,協議熱備份負責將協議的配置信息以及支撐協議運行的數據(比如狀態機或者會話表項等)備份到其它所有成員設備,從而使得IRF 系統能夠作為一臺獨立的設備在網絡中運行。
· IRF 堆疊上/下行鏈路的冗余備份:
IRF 支持的新型分布式聚合技術則可以跨設備配置鏈路備份,用戶可以將不同成員設備上的物理以太網端口配置成一個聚合端口,防止單點故障導致的網絡中斷。
· IRF 堆疊堆疊口的冗余備份:
IRF 采用聚合技術來實現IRF 端口的冗余備份。IRF 端口的連接可以由多條IRF 物理鏈路聚合而成,多條物理鏈路之間可以對流量進行負載分擔。
· IRF 堆疊報文轉發原理:
IRF 采用分布式彈性轉發技術實現報文的二/三層轉發。IRF 系統中的每個成員設備都有完整的二/三層轉發能力,當它收到待轉發的二/三層報文時,可以通過查詢本機的二/三層轉發表得到報文的出接口(以及下一跳),然後將報文從正確的出接口送出去,這個出接口可以在本機上也可以在其它成員設備上,並且將報文從本機送到另外一個成員設備是一個純粹內部的實現,對外界是完全屏蔽的,即對於三層報文來說,不管它在IRF 系統內部穿過了多少成員設備,在跳數上只增加1,即表現為只經過了一個網絡設備。
· IRF 典型應用:
○ IRF 堆疊擴展端口數量:
當接入的用戶數增加到原交換機端口密度不能滿足接入需求時,可以通過可以增加新交換機與原交換機組成堆疊系統來實現。
○ IRF 堆疊擴展系統處理能力:
當中心的交換機轉發能力不能滿足需求時,可以增加新交換機與原交換機組成堆疊系統來實現。
○ IRF 堆疊擴展帶寬:
當邊緣交換機上行帶寬增加時,可以增加新交換機與原交換機組成堆疊系統來實現。
○ 跨越空間使用IRF:
IRF 堆疊可以通過光纖將相距遙遠的設備連接形成堆疊設備。(1 樓、2 樓、3 樓)
· IRF 堆疊配置命令:
○ 綁定設備的邏輯堆疊口和物理堆疊口,同時開啟當前設備的堆疊功能:
[Switch] irf member member-id irf-port irf-port-id port port-list
○ 配置IRF 成員編號:
[Switch] irf member member-id renumber new-member-id
○ 配置堆疊中指定成員設備的優先級:
[Switch] irf member member-id priority priority 配置堆疊口命令和配置成員優先級命令需要重啟設備才能生效。
○ 訪問IRF 堆疊:
<Switch> irf switch-to member-id
○ 在Slave 設備上只允許執行以下命令:
display
quit
return
system-view
debugging
terminal debugging
terminal trapping
terminal logging
· 成員設備之間IRF 物理端口支持聚合功能,IRF 系統和上、下層設備之間的物理連接也支持聚合功能,這樣通過多鏈路備份提高了IRF 系統的可靠性;IRF 系統由多臺成員設備組成,Master 設備負責IRF 系統的運行、管理和維護,Slave 設備在作為備份的同時也可以處理業務,一旦Master 設備故障,系統會迅速自動選舉新的Master,以保證通過IRF 系統的業務不中斷,從而實現了設備的1:N 備份。IRF 是網絡可靠性保障的最優解決方案。一個IRF 中同時只能存在一臺Master,其它成員設備都是Slave。
· 兩個IRF 各自已經穩定運行,通過物理連接和必要的配置,形成一個IRF,這個過程稱為IRF 合並(merge)。一個IRF 形成後,由於IRF 鏈路故障,導致IRF 中兩相鄰成員設備物理上不連通,一個IRF 變成兩個IRF,這個過程稱為IRF 分裂(split)。
· 當IRF 端口狀態變為up 後,成員設備會將已知的拓撲信息周期性的從up 狀態的IRF 端口發送出去。成員設備收到直接鄰居的拓撲信息後,會更新本地記錄的拓撲信息。經過一段時間的收集,所有設備上都會收集到完整的拓撲信息(稱為拓撲收斂)。此時會進入角色選舉階段。
· 使用IRF 專用線纜連接IRF 物理端口。專用線能夠為成員設備間報文的傳輸提供很高的可靠性和性能。如果使用以太網接口作為IRF 物理端口,則使用交叉網線連接IRF 物理端口即可。這種連接方式提高了現有資源的利用率,有利於節約成本(不需要購置IRF 專用接口卡或者光模塊等)。深入淺出高可靠性技術