
Linux內存初始化(一)
一、前言
一直以來,我都非常著迷於兩種電影拍攝手法:一種是慢鏡頭,將每一個細節全方位的展現給觀眾。另外一種就是快鏡頭,多半是反應一個時代的變遷,從非常長的時間段中,截取幾個典型的snapshot,合成在十幾秒的鏡頭中,可以讓觀眾很快的了解一個事物的發展脈絡。對應到技術層面,慢鏡頭有點類似情景分析,把每一行代碼都詳細的進行解析,了解技術的細節。快鏡頭類似數據流分析,勾勒一個過程中,數據結構的演化。本文采用了快鏡頭的方法,對內存初始化部分進行描述,不糾纏於具體函數的代碼實現,只是希望能給大家一個概略性的印象(有興趣的同學可以自行研究代碼)。BTW,在本文中我們都是基於ARM64來描述體系結構相關的內容。
二、啟動之前
在詳細描述linux kernel對內存的初始化過程之前,我們必須首先了解kernel在執行第一條語句之前所面臨的處境。這時候的內存狀況可以參考下圖:
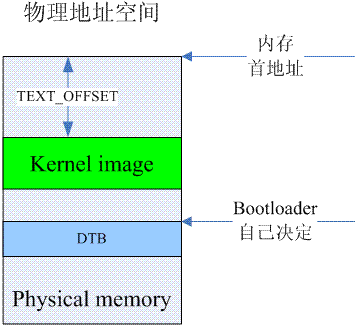
bootloader有自己的方法來了解系統中memory的布局,然後,它會將綠色的kernel image和藍色dtb image copy到了指定的內存位置上。kernel image最好是位於main memory起始地址偏移TEXT_OFFSET的位置,當然,TEXT_OFFSET需要和kernel協商好。kernel image是否一定位於起始的main memory(memory address最低)呢?也不一定,但是對於kernel而言,低於kernel image的內存,kernel是不會納入到自己的內存管理系統中的。對於dtb image的位置,linux並沒有特別的要求。由於這時候MMU是turn off的,因此CPU只能看到物理地址空間。對於cache的要求也比較簡單,只有一條:kernel image對應的cache必須clean to PoC,即系統中所有的observer在訪問kernel image對應內存地址的時候是一致性的。
三、匯編時代
一旦跳轉到linux kernel執行,內核則完全掌控了內存系統的控制權,它需要做的事情首先就是要打開MMU,而為了打開MMU,必須要創建linux kernel正常運行需要的頁表,這就是本節的主要內容。
在體系結構相關的匯編初始化階段,我們會準備二段地址的頁表:一段是identity mapping,其實就是把地址等於物理地址的那些虛擬地址mapping到物理地址上去,打開MMU相關的代碼需要這樣的mapping(別的CPU不知道,但是ARM ARCH強烈推薦這麽做的)。第二段是kernel image mapping,內核代碼歡快的執行當然需要將kernel running需要的地址(kernel txt、rodata、data、bss等等)進行映射了。具體的映射情況可以參考下圖:
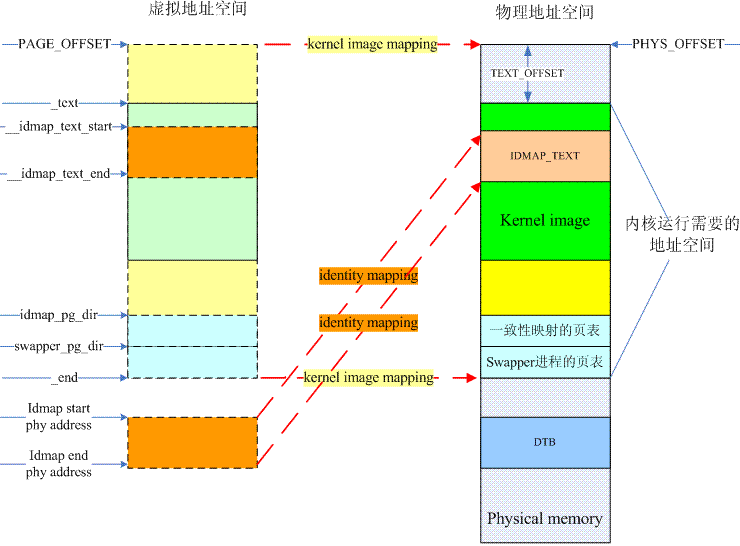
turn on MMU相關的代碼被放入到一個特別的section,名字是.idmap.text,實際上對應上圖中物理地址空間的IDMAP_TEXT這個block。這個區域的代碼被mapping了兩次,做為kernel image的一部分,它被映射到了__idmap_text_start開始的虛擬地址上去,此外,假設IDMAP_TEXT block的物理地址是A地址,那麽它還被映射到了A地址開始的虛擬地址上去。雖然上圖中表示的A地址似乎要大於PAGE_OFFSET,不過實際上不一定需要這樣的關系,這和具體處理器的實現有關。
編譯器感知的是kernel image的虛擬地址(左側),在內核的鏈接腳本中定義了若幹的符號,都是虛擬地址。但是在內核剛開始,沒有打開MMU之前,這些代碼實際上是運行在物理地址上的,因此,內核起始剛開始的匯編代碼基本上是PIC的,首先需要定位到頁表的位置,然後在頁表中填入kernel image mapping和identity mapping的頁表項。頁表的起始位置比較好定(bss段之後),但是具體的size還是需要思考一下的。我們要選擇一個合適的size,確保能夠覆蓋kernel image mapping和identity mapping的地址段,然後又不會太浪費。我們以kernel image mapping為例,描述確定Tranlation table size的思考過程。假設48 bit的虛擬地址配置,4k的page size,這時候需要4級映射,地址被分成9(level 0 or PGD) + 9(level 1 or PUD) + 9(level 2 or PMD) + 9(level 3 or PTE) + 12(page offset),假設我們分配4個page分別保存Level 0到level 3的translation table,那麽可以建立的最大的地址映射範圍是512(level 3中有512個entry) X 4k = 2M。2M這個size當然不理想,無法容納kernel image的地址區域,怎麽辦?使用section mapping,讓PMD執行block descriptor,這樣使用3個page就可以mapping 512 X 2M = 1G的地址空間範圍。當然,這種方法有一點副作用就是:PAGE_OFFSET必須2M對齊。對於16K或者64K的page size,使用section mapping就有點不合適了,因為這時候對齊的要求太高了,對於16K page size,需要32M對齊,對於64K page size,需要512M對齊。不過,這也沒有什麽,畢竟這時候page size也變大了,不使用section mapping也能覆蓋很大區域。例如,對於16K page size,一個16K page size中可以保存2K個entry,因此能夠覆蓋2K X 16K = 32M的地址範圍。對於64K page size,一個64K page size中可以保存8K個entry,因此能夠覆蓋8K X 64K = 512M的地址範圍。32M和512M基本是可以滿足需求的。最後的結論:swapper進程(內核空間)需要預留頁表的size是和page table level相關,如果使用了section mapping,那麽需要預留PGTABLE_LEVELS - 1個page。如果不使用section mapping,那麽需要預留PGTABLE_LEVELS 個page。
上面的結論起始是適合大部分情況下的identity mapping,但是還是有特例(需要考慮的點主要和其物理地址的位置相關)。我們假設這樣的一個配置:虛擬地址配置為39bit,而物理地址是48個bit,同時,IDMAP_TEXT這個block的地址位於高端地址(大於39 bit能表示的範圍)。在這種情況下,上面的結論失效了,因為PGTABLE_LEVELS 是和虛擬地址的bit數、PAGE_SIZE的定義相關,而是和物理地址的配置無關。linux kernel使用了巧妙的方法解決了這個問題,大家可以自己看代碼理解,這裏就不多說了。
一旦設定完了頁表,那麽打開MMU之後,kernel正式就會進入虛擬地址空間的世界,美中不足的是內核的虛擬世界沒有那麽大。原來擁有的整個物理地址空間都消失了,能看到的僅僅剩下kernel image mapping和identity mapping這兩段地址空間是可見的。不過沒有關系,這只是剛開始,內存初始化之路還很長。
四、看見DTB
雖然可以通過kernel image mapping和identity mapping來窺探物理地址空間,但終究是管中窺豹,不了解全局,那麽內核是如何了解對端的物理世界呢?答案就是DTB,但是問題來了,這時候,內核還沒有為DTB這段內存創建映射,因此,打開MMU之後的kernel還不能直接訪問,需要先創建dtb mapping,而要創建address mapping,就需要分配頁表內存,而這時候,還沒有了解內存布局,內存管理模塊還沒有初始化,如何來分配內存呢?
下面這張圖片給出了解決方案:
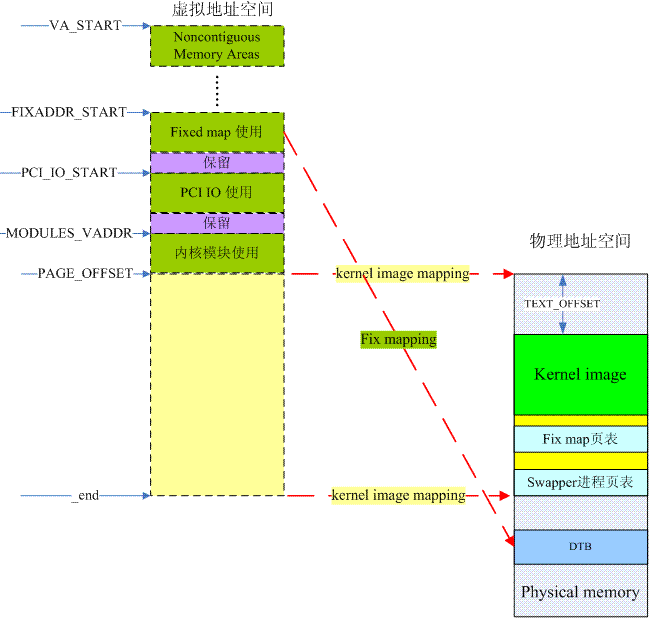
整個虛擬地址空間那麽大,可以被平均分成兩半,上半部分的虛擬地址空間主要各種特定的功能,而下半部分主要用於物理內存的直接映射。對於DTB而言,我們借用了fixed-mapped address這個概念。fixed map是被linux kernel用來解決一類問題的機制,這類問題的共同特點是:(1)在很早期的階段需要進行地址映射,而此時,由於內存管理模塊還沒有完成初始化,不能動態分配內存,也就是無法動態分配創建映射需要的頁表內存空間。(2)物理地址是固定的,或者是在運行時就可以確定的。對於這類問題,內核定義了一段固定映射的虛擬地址,讓使用fix map機制的各個模塊可以在系統啟動的早期就可以創建地址映射,當然,這種機制不是那麽靈活,因為虛擬地址都是編譯時固定分配的。
好,我們可以考慮創建第三段地址映射了,當然,要創建地址映射就要創建各個level中描述符。對於fixed-mapped address這段虛擬地址空間,由於也是位於內核空間,因此PGD當然就是復用swapper進程的PGD了(其實整個系統就一個PGD),而其他level的Translation table則是靜態定義的(arch/arm64/mm/mmu.c),位於內核bss段,由於所有的Translation table都在kernel image mapping的範圍內,因此內核可以毫無壓力的訪問,並創建fixed-mapped address這段虛擬地址空間對應的PUD、PMD和PTE的entry。所有中間level的Translation table都是在early_fixmap_init函數中完成初始化的,最後一個level則是在各個具體的模塊進行的,對於DTB而言,這發生在fixmap_remap_fdt函數中。
系統對dtb的size有要求,不能大於2M,這個要求主要是要確保在創建地址映射(create_mapping)的時候不能分配其他的translation table page,也就是說,所有的translation table都必須靜態定義。為什麽呢?因為這時候內存管理模塊還沒有初始化,即便是memblock模塊(初始化階段分配內存的模塊)都尚未初始化(沒有內存布局的信息),不能動態分配內存。
五、early ioremap
除了DTB,在啟動階段,還有其他的模塊也想要創建地址映射,當然,對於這些需求,內核統一采用了fixmap的機制來應對,fixmap的具體信息如下圖所示:
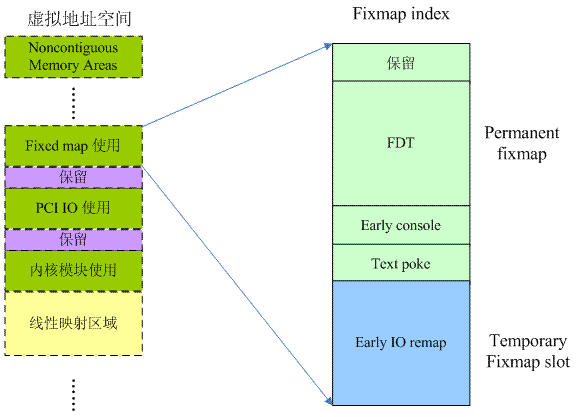
從上面這個圖片可以看出fix-mapped虛擬地址分成兩段,一段是permanent fix map,一段是temporary fixmap。所謂permanent表示映射關系永遠都是存在的,例如FDT區域,一旦完成地址映射,內核可以訪問DTB之後,這個映射關系一直都是存在的。而temporary fixmap則不然,一般而言,某個模塊使用了這部分的虛擬地址之後,需要盡快釋放這段虛擬地址,以便給其他模塊使用。
你可能會很奇怪,因為傳統的驅動模塊中,大家通常使用ioremap函數來完成地址映射,為了還有一個early IO remap呢?其實ioremap函數的使用需要一定的前提條件的,在地址映射過程中,如果某個level的Translation tabe不存在,那麽該函數需要調用夥伴系統模塊的接口來分配一個page size的內存來創建某個level的Translation table,但是在啟動階段,內存管理的夥伴系統還沒有ready,其實這時候,內核連系統中有多少內存都不知道的。而early io remap則在early_ioremap_init之後就可以被使用了。更具體的信息請參考mm/early_ioremap.c文件。
結論:如果想要在夥伴系統初始化之前進行設備寄存器的訪問,那麽可以考慮early IO remap機制。
六、內存布局
完成DTB的映射之後,內核可以訪問這一段的內存了,通過解析DTB中的內容,內核可以勾勒出整個內存布局的情況,為後續內存管理初始化奠定基礎。收集內存布局的信息主要來自下面幾條途徑:
(1)choosen node。該節點有一個bootargs屬性,該屬性定義了內核的啟動參數,而在啟動參數中,可能包括了mem=nn[KMG]這樣的參數項。initrd-start和initrd-end參數定義了initial ramdisk image的物理地址範圍。
(2)memory node。這個節點主要定義了系統中的物理內存布局。主要的布局信息是通過reg屬性來定義的,該屬性定義了若幹的起始地址和size條目。
(3)DTB header中的memreserve域。對於dts而言,這個域是定義在root node之外的一行字符串,例如:/memreserve/ 0x05e00000 0x00100000;,memreserve之後的兩個值分別定義了起始地址和size。對於dtb而言,memreserve這個字符串被DTC解析並稱為DTB header中的一部分。更具體的信息可以參考device tree基礎文檔,了解DTB的結構。
(4)reserved-memory node。這個節點及其子節點定義了系統中保留的內存地址區域。保留內存有兩種,一種是靜態定義的,用reg屬性定義的address和size。另外一種是動態定義的,只是通過size屬性定義了保留內存區域的長度,或者通過alignment屬性定義對齊屬性,動態定義類型的子節點的屬性不能精準的定義出保留內存區域的起始地址和長度。在建立地址映射方面,可以通過no-map屬性來控制保留內存區域的地址映射關系的建立。更具體的信息可以閱讀參考文獻[1]。
通過對DTB中上述信息的解析,其實內核已經基本對內存布局有數了,但是如何來管理這些信息呢?這也就是著名的memblock模塊,主要負責在初始化階段用來管理物理內存。一個參考性的示意圖如下:

內核在收集了若幹和memory相關的信息後,會調用memblock模塊的接口API(例如:memblock_add、memblock_reserve、memblock_remove等)來管理這些內存布局的信息。內核需要動態管理起來的內存資源被保存在memblock的memory type的數組中(上圖中的綠色block,按照地址的大小順序排列),而那些需要預留的,不需要內核管理的內存被保存在memblock的reserved type的數組中(上圖中的青色block,也是按照地址的大小順序排列)。要想了解進一步的信息,請參考內核代碼中的setup_machine_fdt和arm64_memblock_init這兩個函數的實現。
七、看到內存
了解到了當前的物理內存的布局,但是內核仍然只是能夠訪問部分內存(kernel image mapping和DTB那兩段內存,上圖中黃色block),大部分的內存仍然處於黑暗中,等待光明的到來,也就是說需要創建這些內存的地址映射。
在這個時間點上,創建內存的地址映射有一個悖論:創建地址映射需要分配內存,但是這時候夥伴系統沒有ready,無法動態分配。也許你會說,memblock不是已經ready了嗎,不可以調用memblock_alloc進行物理內存的分配嗎?當然可以,memblock_alloc分配的物理內存仍然需要通過虛擬地址訪問,而這些內存都還沒有創建地址映射,因此內核一旦訪問memblock_alloc分配的物理內存,悲劇就會發生了。
怎麽辦呢?內核采用了一個巧妙的辦法:那就是控制創建地址映射,memblock_alloc分配頁表內存的順序。也就是說剛開始的時候創建的地址映射不需要頁表內存的分配,當內核需要調用memblock_alloc進行頁表物理地址分配的時候,很多已經創建映射的內存已經ready了,這樣,在調用create_mapping的時候不需要分配頁表內存。更具體的解釋參考下面的圖片:
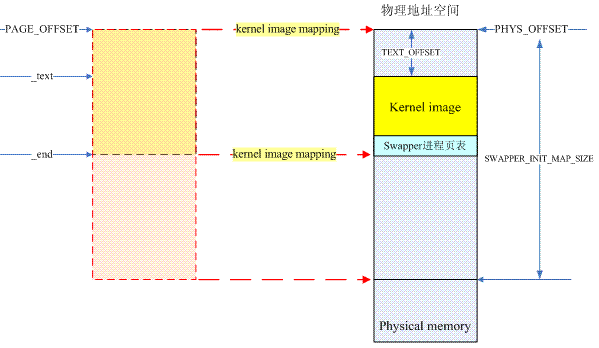
我們知道,在內核編譯的時候,在BSS段之後分配了幾個page用於swapper進程地址空間(內核空間)的映射,當然,由於kernel image不需要mapping那麽多的地址,因此swapper進程translation table的最後一個level中的entry不會全部的填充完畢。換句話說:swapper進程頁表可以支持遠遠大於kernel image mapping那一段的地址區域,實際上,它可以支持的地址段的size是SWAPPER_INIT_MAP_SIZE。為(PAGE_OFFSET,PAGE_OFFSET+SWAPPER_INIT_MAP_SIZE)這段虛擬內存創建地址映射,mapping到(PHYS_OFFSET,PHYS_OFFSET+SWAPPER_INIT_MAP_SIZE)這段物理內存的時候,調用create_mapping不會發生內存分配,因為所有的頁表都已經存在了,不需要動態分配。
一旦完成了(PHYS_OFFSET,PHYS_OFFSET+SWAPPER_INIT_MAP_SIZE)這段物理內存的地址映射,這時候,終於可以自由使用memblock_alloc進行內存分配了,當然,要進行限制,確保分配的內存位於(PHYS_OFFSET,PHYS_OFFSET+SWAPPER_INIT_MAP_SIZE)這段物理內存中。完成所有memory type類型的memory region的地址映射之後,可以解除限制,任意分配memory了。而這時候,所有memory type的地址區域(上上圖中綠色block)都已經可見,而這些寶貴的內存資源就是內存管理模塊需要管理的對象。具體代碼請參考paging_init--->map_mem函數的實現。
八、結束語
目前為止,所有為內存管理做的準備工作已經完成:收集了整個內存布局的信息,memblock模塊中已經保存了所有需要管理memory region的信息,同時,系統也為所有的內存(reserved除外)創建了地址映射。雖然整個內存管理系統沒有ready,但是通過memblock模塊已經可以在隨後的初始化過程中進行動態內存的分配。 有了這些基礎,隨後就是真正的內存管理系統的初始化了,我們下回分解。
參考文獻:
1、Documentation/devicetree/bindings/reserved-memory/reserved-memory.txt
2、linux4.4.6內核代碼
Linux內存初始化(一)