
Texygen文本生成,交大計算機系14級的朱耀明
文本生成哪家強?上交大提出基準測試新平臺 Texygen
2018-02-12 13:11測評新智元報道
來源:arxiv
編譯:Marvin
【新智元導讀】上海交通大學、倫敦大學學院朱耀明, 盧思迪,鄭雷,郭家賢, 張偉楠, 汪軍,俞勇等人的研究團隊最新推出Texygen平臺,這是一個支持開放域文本生成模型研究的基準平臺。Texygen不僅實現了大部分的文本生成模型,而且還覆蓋了一系列衡量生成文本的多樣性、質量和一致性的評測指標。
項目地址: https://github.com/geek-ai/Texygen
論文:https://arxiv.org/abs/1802.01886
上海交通大學、倫敦大學學院朱耀明, 盧思迪,鄭雷,郭家賢, 張偉楠 , 汪軍,俞勇等人的研究團隊最新推出Texygen,這是一個支持開放域文本生成模型研究的基準平臺。Texygen不僅實現了大部分的文本生成模型,而且還提供了一系列衡量生成文本的多樣性、質量和一致性的評測指標。Texygen平臺可以幫助規範文本生成的研究,促進研究人員提供自己所呈現工作的官方開源實現。這將有助於提高文本生成的未來研究工作的可復現性和可靠性。
Texygen項目主要貢獻者,上海交大計算機系14級的朱耀明同學表示:
目前計算機視覺與自然語言處理是人工智能的兩大主要應用,生成對抗網絡(GAN)作為深度學習界的一項技術,在前者的運用上日臻成熟,而在與後者的結合上還略欠火候。這次設計Texygen平臺一方面目的便是總結了一下生成對抗網絡在文本生成的前沿進展,並給大家的工作提供一個比較與交流的平臺。另一方面,文本生成由於其任務的特殊性,至今還沒有一項能讓所有人信服的自動測試指標。因此,Texygen也實現了幾大主流評價方法並提出了自己的指標,望能在文本生成評測這一主題下給研究者們一些啟發,推動這方面的工作邁向下一階段。
Texygen項目貢獻者之一,上海交大致遠學院15級計算機科學班的盧思迪同學感言道:
在開發新的模型的過程中,我們也比較了文本生成這一領域與圖像生成/計算機視覺的相關問題的異同。我們發現,一個較為顯著的問題是,與卷積神經網絡(Convolution Neural Network)在那些領域的大放異彩不同,循環神經網絡(Recurrent Neural Network)作為一種自回歸(auto-regressive)工具並不夠專一化。其包含的用於簡化網絡結構、提高收斂性能的假設過少,使得對語言模型、文本生成模型的訓練變得相對而言較難取得革命性突破。我們將在Texygen的幫助下對這類問題進行進一步思考,同時也希望這個平臺能夠幫助學界的朋友們在這一問題上取得更多進展。
Texygen項目的指導者,上海交大計算機系John Hopcroft Center的助理教授張偉楠說:
基於生成式對抗網絡(GAN)做圖像生成的研究工作現在已經隨處可見,這些模型之所以可以橫向對比,其重要原因在於人們提出了Inception Score等評價指標,對於新生成的圖像給出量化的評測和對比,進而推進研究的前沿。在文本生成方面,盡管近一年的研究工作越來越多,但像Inception Score這樣的指標還並未發明出來。我們希望借助著Texygen平臺,研究者們能更多地思考什麽是一個好的文本生成評測指標以及如何公平地評測文本生成模型,這樣才能真正推動這個領域朝著健康的方向發展。
評估文本生成模型的3個挑戰
開放域文本生成問題的目標是對離散token的連續生成進行建模。它具有很多的實際應用,包括但不限於機器翻譯[2],AI聊天機器人[9],自動生成圖像說明[15],問題回答和信息檢索[13]。與我們所已經看到的文本生成實際應用的各種成果相對的,文本生成模型的基礎研究並沒有取得太多重大進展。目前為止,大多數文本生成模型的基礎算法仍然是最大似然估計(MLE)[11]或其變體。值得註意的是,由於這些常見的選擇並不是這一序列生成問題的完美目標函數(正如文獻[6]中所指出的“exposure bias”),研究人員一直在尋找替代的優化方法和目標函數。
生成對抗網絡(GAN)[4]的成功激發了人們對文本離散數據對抗性訓練研究的興趣。例如,序列生成對抗網絡SeqGAN是應用REINFORCE算法[14]解決原始GAN目標函數的離散優化的早期嘗試之一。自那以後,研究人員提出了許多改進SeqGAN的方法來進一步提升SeqGAN的性能,例如梯度消失(MaliGAN [3],RankGAN [10],LeakGAN [5]使用的自舉再激活),以及生成長文本時的魯棒性(LeakGAN)。
然而,在評估文本生成模型時,學界面臨3個主要的挑戰。首先,一個好的文本生成模型的標準是什麽還不明確。盡管研究人員已經開發了諸如困惑度(perplexity)[7], 基於人造數據的負對數似然估計(NLL)[16],基於圖靈測試的人類評分,以及BLEU[12]等標準,但還沒有一個單一的評測指標足夠全面,可以評測一個文本生成模型性能的方方面面。因此,需要對多個評測指標進行評估才能得出明確的答案。
其次,研究人員並沒有義務公開他們的源代碼,這為第三方復現他們所報告的實驗結果帶來了不必要的額外困難。
第三,文本生成會遇到質量和多樣性權衡的問題。在模型性能一定的情況下,人們可以通過調節一些參數來修改這一權衡。這使得研究者發布的工作是否具有重大突破變得更加難以衡量。據我們所知,關於文本生成的多樣性還沒有一個好的評測指標。因此,我們迫切需要一個可靠的平臺,它可以對現有的文本生成模型進行全面的評估,並在一個共同的框架中促進新模型的開發。
在本文中,我們發布了Texygen,這是一個用於文本生成模型的完全開源的基準測試平臺。Texygen不僅包含了大部分的基準模型的良好實現,而且還提供了各種評測指標來評估生成文本的多樣性、質量和一致性。通過這些指標,我們可以對不同的文本生成模型進行更全面的評估。我們希望這個平臺能夠幫助規範文本生成研究的進程,提高這個領域研究工作的可復現性,並鼓勵更高層次的應用。
Texygen平臺
Texygen為文本生成模型提供了一個標準的自頂向下的多維評估系統。目前,Texygen包含兩個基本組件:訓練好的基準模型和可自動計算的評估標準。Texygen還提供了該平臺的開源代碼庫,研究人員可以在其中找到API的規範和手冊,以便實現他們的模型並使用Texygen進行評估。
基線模型
在目前版本的Texygen,我們實現了各種基於likelihood的模型,例如基礎的MLE語言模型,SeqGAN [16],MaliGAN [3],RankGAN [10],TextGAN(Adversarial Feature Matching)[17],GSGAN(GAN with Gumbel Softmax trick )[8]和LeakGAN [5]。這些基準模型包含有監督的likelihood方法,對抗方法和層次化方法。雖然以後會增加更多模型,但我們相信現在的覆蓋率已經足以為任何新模型提供一個充分的參照。
評測指標(Metrics)
到目前為止,Texygen實現了5個文本生成的評測指標,涵蓋了以下類別的各個方面。Texygen還提供易用的API來檢索自己的模型和生成的文本的結果。
基於文檔相似度的指標。生成的文檔質量的最直觀的評測指標是文檔與自然語言或者訓練數據集的類似程度:
- BLEU:基於詞袋(bag of words)模型的評測指標。以詞和詞組為基本單位。
- EmbSim :使用模型輸出的序列訓練出的詞向量的相互相似性特征定義的評測指標。以基本詞元(token)為基本單位。
基於似然性(likelihood)的指標:
- NLL-oracle:基於人造數據的似然度估計。衡量待評測語言模型的輸出在構造出的人造數據模型衡量下的負對數似然。
- NLL-test:基於測試數據的似然度估計。衡量構造出測試數據在待評測語言模型的衡量下的負對數似然。
基於多樣性評價的指標:
- Self-BLEU:基於詞袋(bag of words)模型的評測指標。衡量一個模型的每一句輸出與此模型其他輸出的相似性。以詞和詞組為基本單位。
Texygen平臺的架構
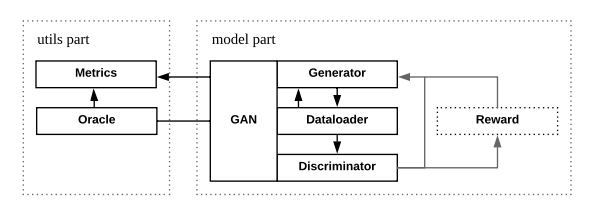
圖1: Texygen的架構
Texygen是通過TensorFlow實現的[1]。如圖1所示,系統由兩部分組成,主要包括3個模塊,彼此高度分離,易於定制化。
在utils部分,我們提供用戶Metrics類和Oracle類。前者有3個用於計算BLEU score、NLL loss和EmbSim的子類,後者則允許用戶初始化3種不同類型的Oracle:基於LSTM的,基於GRU的和基於SRU的。默認的oracle是基於LSTM的。
在模型部分,用戶只需要與GAN類(作為一個主要類)交互就可以開始訓練過程,而不必關心生成器、鑒別器和獎勵(對於基於RL的GAN而言)類。Texygen還提供了兩種不同類型的GAN訓練過程:人造數據訓練和真實數據訓練。前者使用oracle LSTM生成的數據,後者使用真實世界的數據集(例如,COCO image caption數據集)。
實驗
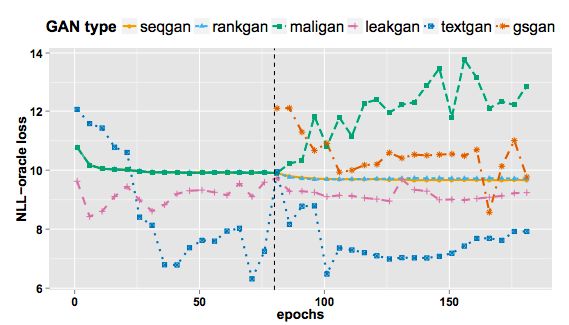
圖2:整個訓練過程的NLL-oracle loss的比較
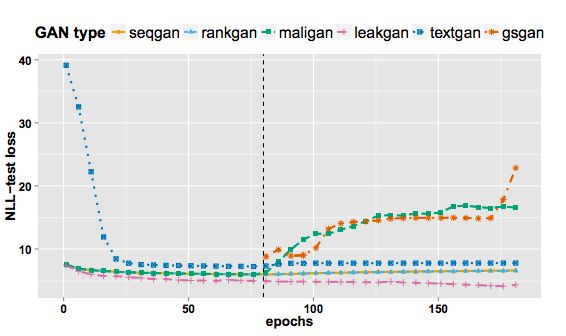
圖3:整個訓練過程的NLL-test loss的比較
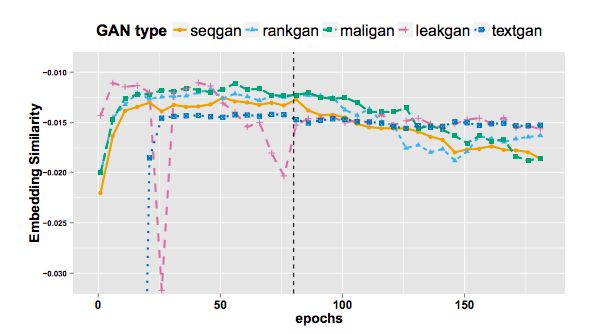
圖4:整個訓練過程的EmbSim比較
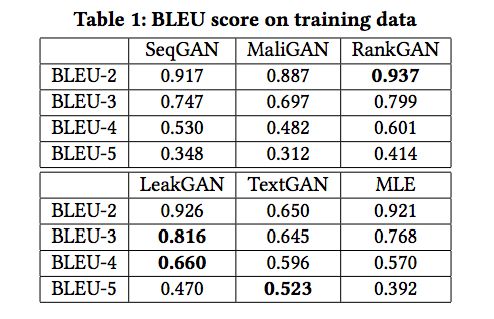
表1:訓練數據的BLEU score
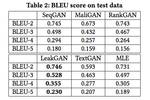
表2:測試數據的BLEU score
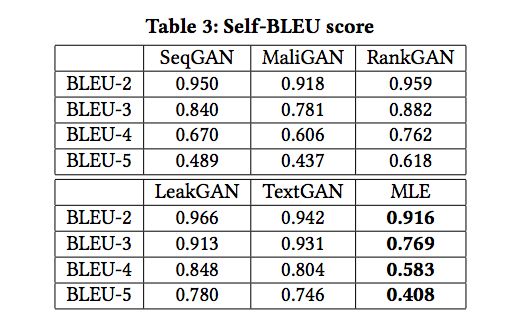
表3: Self-BLEU score
結論和將來的工作
Texygen是一個文本生成的基準平臺,幫助研究人員評估自己的模型,並從不同的角度公平,方便地與現有的基準模型進行比較。Texygen已經設計和實現了各種評估標準,以提供一個全面的基準。
我們發現並不是所有的NLP 評測指標都適用於文本生成模型。例如,上下文無關語法(context free grammar,CFG)是文本語法分析中廣泛使用的評測指標,並且在一些相關工作中被用作評測指標[8]。但實際上,我們發現這個metric不能區分不同的文本生成模型,甚至傾向於支持更嚴重的mode collapse,因為這些模型只能學習幾個語法。未來,我們將不斷加入對新的模型和新的metric實現支持,以更好地對文本生成任務進行基準測試。
項目地址: https://github.com/geek-ai/Texygen
論文:https://arxiv.org/abs/1802.01886
Texygen文本生成,交大計算機系14級的朱耀明