
ElasticSearch原理
Elasticsearch-基礎介紹及索引原理分析
最近在參與一個基於Elasticsearch作為底層數據框架提供大數據量(億級)的實時統計查詢的方案設計工作,花了些時間學習Elasticsearch的基礎理論知識,整理了一下,希望能對Elasticsearch感興趣/想了解的同學有所幫助。 同時也希望有發現內容不正確或者有疑問的地方,望指明,一起探討,學習,進步。
介紹
Elasticsearch 是一個分布式可擴展的實時搜索和分析引擎,一個建立在全文搜索引擎 Apache Lucene(TM) 基礎上的搜索引擎.當然 Elasticsearch 並不僅僅是 Lucene 那麽簡單,它不僅包括了全文搜索功能,還可以進行以下工作:
- 分布式實時文件存儲,並將每一個字段都編入索引,使其可以被搜索。
- 實時分析的分布式搜索引擎。
- 可以擴展到上百臺服務器,處理PB級別的結構化或非結構化數據。
基本概念
先說Elasticsearch的文件存儲,Elasticsearch是面向文檔型數據庫,一條數據在這裏就是一個文檔,用JSON作為文檔序列化的格式,比如下面這條用戶數據:
{
"name" : "John",
"sex" : "Male",
"age" : 25,
"birthDate": "1990/05/01",
"about" : "I love to go rock climbing",
"interests": [ "sports", "music" ]
}
用Mysql這樣的數據庫存儲就會容易想到建立一張User表,有balabala的字段等,在Elasticsearch裏這就是一個文檔,當然這個文檔會屬於一個User的類型,各種各樣的類型存在於一個索引當中。這裏有一份簡易的將Elasticsearch和關系型數據術語對照表:
關系數據庫 ? 數據庫 ? 表 ? 行 ? 列(Columns)
Elasticsearch ? 索引(Index) ? 類型(type) ? 文檔(Docments) ? 字段(Fields)
一個 Elasticsearch 集群可以包含多個索引(數據庫),也就是說其中包含了很多類型(表)。這些類型中包含了很多的文檔(行),然後每個文檔中又包含了很多的字段(列)。Elasticsearch的交互,可以使用Java API,也可以直接使用HTTP的Restful API方式,比如我們打算插入一條記錄,可以簡單發送一個HTTP的請求:
PUT /megacorp/employee/1
{
"name" : "John",
"sex" : "Male",
"age" : 25,
"about" : "I love to go rock climbing",
"interests": [ "sports", "music" ]
}
更新,查詢也是類似這樣的操作,具體操作手冊可以參見Elasticsearch權威指南
索引
Elasticsearch最關鍵的就是提供強大的索引能力了,其實InfoQ的這篇時間序列數據庫的秘密(2)——索引寫的非常好,我這裏也是圍繞這篇結合自己的理解進一步梳理下,也希望可以幫助大家更好的理解這篇文章。
Elasticsearch索引的精髓:
一切設計都是為了提高搜索的性能
另一層意思:為了提高搜索的性能,難免會犧牲某些其他方面,比如插入/更新,否則其他數據庫不用混了。前面看到往Elasticsearch裏插入一條記錄,其實就是直接PUT一個json的對象,這個對象有多個fields,比如上面例子中的name, sex, age, about, interests,那麽在插入這些數據到Elasticsearch的同時,Elasticsearch還默默1的為這些字段建立索引--倒排索引,因為Elasticsearch最核心功能是搜索。
Elasticsearch是如何做到快速索引的
InfoQ那篇文章裏說Elasticsearch使用的倒排索引比關系型數據庫的B-Tree索引快,為什麽呢?
什麽是B-Tree索引?
上大學讀書時老師教過我們,二叉樹查找效率是logN,同時插入新的節點不必移動全部節點,所以用樹型結構存儲索引,能同時兼顧插入和查詢的性能。因此在這個基礎上,再結合磁盤的讀取特性(順序讀/隨機讀),傳統關系型數據庫采用了B-Tree/B+Tree這樣的數據結構:
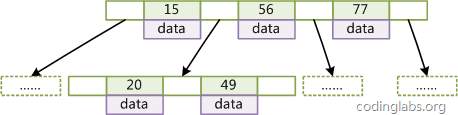
為了提高查詢的效率,減少磁盤尋道次數,將多個值作為一個數組通過連續區間存放,一次尋道讀取多個數據,同時也降低樹的高度。
什麽是倒排索引?

繼續上面的例子,假設有這麽幾條數據(為了簡單,去掉about, interests這兩個field):
| ID | Name | Age | Sex |
| -- |:------------:| -----:| -----:|
| 1 | Kate | 24 | Female
| 2 | John | 24 | Male
| 3 | Bill | 29 | Male
ID是Elasticsearch自建的文檔id,那麽Elasticsearch建立的索引如下:
Name:
| Term | Posting List |
| -- |:----:|
| Kate | 1 |
| John | 2 |
| Bill | 3 |
Age:
| Term | Posting List |
| -- |:----:|
| 24 | [1,2] |
| 29 | 3 |
Sex:
| Term | Posting List |
| -- |:----:|
| Female | 1 |
| Male | [2,3] |
Posting List
Elasticsearch分別為每個field都建立了一個倒排索引,Kate, John, 24, Female這些叫term,而[1,2]就是Posting List。Posting list就是一個int的數組,存儲了所有符合某個term的文檔id。
看到這裏,不要認為就結束了,精彩的部分才剛開始...
通過posting list這種索引方式似乎可以很快進行查找,比如要找age=24的同學,愛回答問題的小明馬上就舉手回答:我知道,id是1,2的同學。但是,如果這裏有上千萬的記錄呢?如果是想通過name來查找呢?
Term Dictionary
Elasticsearch為了能快速找到某個term,將所有的term排個序,二分法查找term,logN的查找效率,就像通過字典查找一樣,這就是Term Dictionary。現在再看起來,似乎和傳統數據庫通過B-Tree的方式類似啊,為什麽說比B-Tree的查詢快呢?
Term Index
B-Tree通過減少磁盤尋道次數來提高查詢性能,Elasticsearch也是采用同樣的思路,直接通過內存查找term,不讀磁盤,但是如果term太多,term dictionary也會很大,放內存不現實,於是有了Term Index,就像字典裏的索引頁一樣,A開頭的有哪些term,分別在哪頁,可以理解term index是一顆樹:
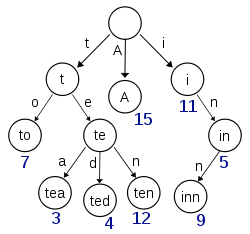
這棵樹不會包含所有的term,它包含的是term的一些前綴。通過term index可以快速地定位到term dictionary的某個offset,然後從這個位置再往後順序查找。
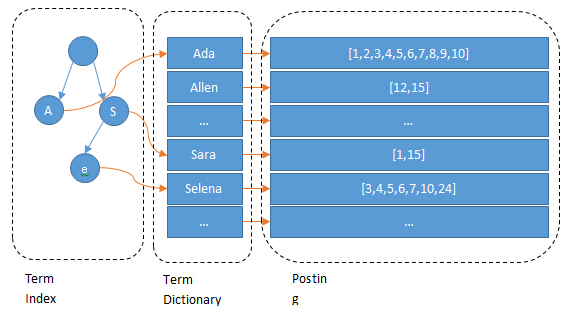
所以term index不需要存下所有的term,而僅僅是他們的一些前綴與Term Dictionary的block之間的映射關系,再結合FST(Finite State Transducers)的壓縮技術,可以使term index緩存到內存中。從term index查到對應的term dictionary的block位置之後,再去磁盤上找term,大大減少了磁盤隨機讀的次數。
這時候愛提問的小明又舉手了:"那個FST是神馬東東啊?"
一看就知道小明是一個上大學讀書的時候跟我一樣不認真聽課的孩子,數據結構老師一定講過什麽是FST。但沒辦法,我也忘了,這裏再補下課:
FSTs are finite-state machines that map a term (byte sequence) to an arbitrary output.
假設我們現在要將mop, moth, pop, star, stop and top(term index裏的term前綴)映射到序號:0,1,2,3,4,5(term dictionary的block位置)。最簡單的做法就是定義個Map<string, integer="">,大家找到自己的位置對應入座就好了,但從內存占用少的角度想想,有沒有更優的辦法呢?答案就是:FST(理論依據在此,但我相信99%的人不會認真看完的)
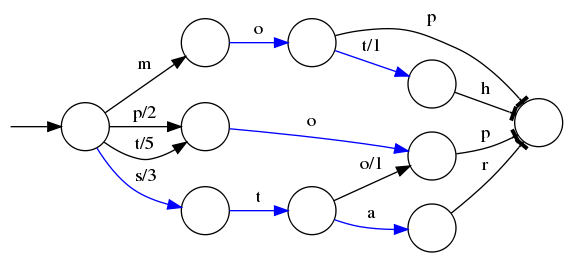
??表示一種狀態
-->表示狀態的變化過程,上面的字母/數字表示狀態變化和權重
將單詞分成單個字母通過??和-->表示出來,0權重不顯示。如果??後面出現分支,就標記權重,最後整條路徑上的權重加起來就是這個單詞對應的序號。
FSTs are finite-state machines that map a term (byte sequence) to an arbitrary output.
FST以字節的方式存儲所有的term,這種壓縮方式可以有效的縮減存儲空間,使得term index足以放進內存,但這種方式也會導致查找時需要更多的CPU資源。
後面的更精彩,看累了的同學可以喝杯咖啡……
壓縮技巧
Elasticsearch裏除了上面說到用FST壓縮term index外,對posting list也有壓縮技巧。
小明喝完咖啡又舉手了:"posting list不是已經只存儲文檔id了嗎?還需要壓縮?"
嗯,我們再看回最開始的例子,如果Elasticsearch需要對同學的性別進行索引(這時傳統關系型數據庫已經哭暈在廁所……),會怎樣?如果有上千萬個同學,而世界上只有男/女這樣兩個性別,每個posting list都會有至少百萬個文檔id。 Elasticsearch是如何有效的對這些文檔id壓縮的呢?
Frame Of Reference
增量編碼壓縮,將大數變小數,按字節存儲
首先,Elasticsearch要求posting list是有序的(為了提高搜索的性能,再任性的要求也得滿足),這樣做的一個好處是方便壓縮,看下面這個圖例: 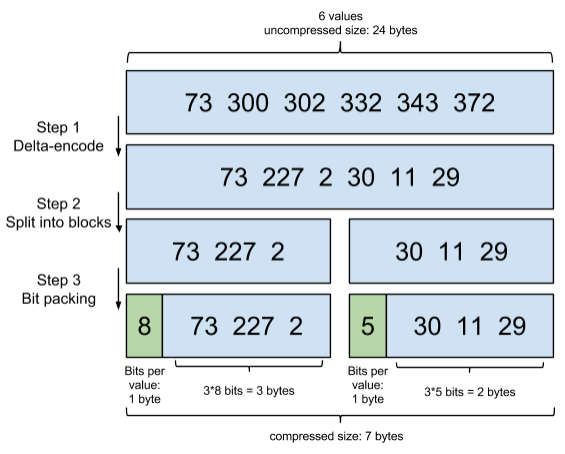
如果數學不是體育老師教的話,還是比較容易看出來這種壓縮技巧的。
原理就是通過增量,將原來的大數變成小數僅存儲增量值,再精打細算按bit排好隊,最後通過字節存儲,而不是大大咧咧的盡管是2也是用int(4個字節)來存儲。
Roaring bitmaps
說到Roaring bitmaps,就必須先從bitmap說起。Bitmap是一種數據結構,假設有某個posting list:
[1,3,4,7,10]
對應的bitmap就是:
[1,0,1,1,0,0,1,0,0,1]
非常直觀,用0/1表示某個值是否存在,比如10這個值就對應第10位,對應的bit值是1,這樣用一個字節就可以代表8個文檔id,舊版本(5.0之前)的Lucene就是用這樣的方式來壓縮的,但這樣的壓縮方式仍然不夠高效,如果有1億個文檔,那麽需要12.5MB的存儲空間,這僅僅是對應一個索引字段(我們往往會有很多個索引字段)。於是有人想出了Roaring bitmaps這樣更高效的數據結構。
Bitmap的缺點是存儲空間隨著文檔個數線性增長,Roaring bitmaps需要打破這個魔咒就一定要用到某些指數特性:
將posting list按照65535為界限分塊,比如第一塊所包含的文檔id範圍在0~65535之間,第二塊的id範圍是65536~131071,以此類推。再用<商,余數>的組合表示每一組id,這樣每組裏的id範圍都在0~65535內了,剩下的就好辦了,既然每組id不會變得無限大,那麽我們就可以通過最有效的方式對這裏的id存儲。
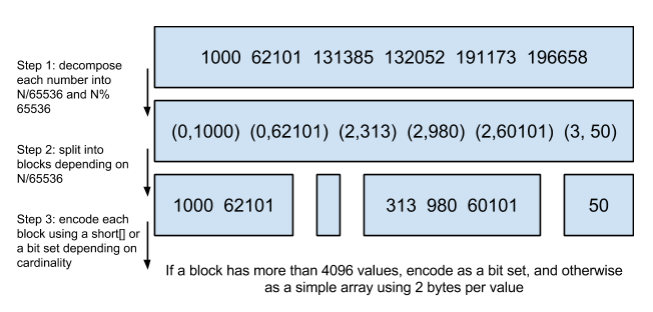
細心的小明這時候又舉手了:"為什麽是以65535為界限?"
程序員的世界裏除了1024外,65535也是一個經典值,因為它=2^16-1,正好是用2個字節能表示的最大數,一個short的存儲單位,註意到上圖裏的最後一行“If a block has more than 4096 values, encode as a bit set, and otherwise as a simple array using 2 bytes per value”,如果是大塊,用節省點用bitset存,小塊就豪爽點,2個字節我也不計較了,用一個short[]存著方便。
那為什麽用4096來區分大塊還是小塊呢?
個人理解:都說程序員的世界是二進制的,4096*2bytes = 8192bytes < 1KB, 磁盤一次尋道可以順序把一個小塊的內容都讀出來,再大一位就超過1KB了,需要兩次讀。
聯合索引
上面說了半天都是單field索引,如果多個field索引的聯合查詢,倒排索引如何滿足快速查詢的要求呢?
- 利用跳表(Skip list)的數據結構快速做“與”運算,或者
- 利用上面提到的bitset按位“與”
先看看跳表的數據結構:
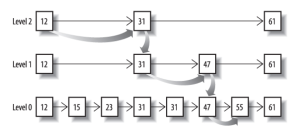
將一個有序鏈表level0,挑出其中幾個元素到level1及level2,每個level越往上,選出來的指針元素越少,查找時依次從高level往低查找,比如55,先找到level2的31,再找到level1的47,最後找到55,一共3次查找,查找效率和2叉樹的效率相當,但也是用了一定的空間冗余來換取的。
假設有下面三個posting list需要聯合索引:
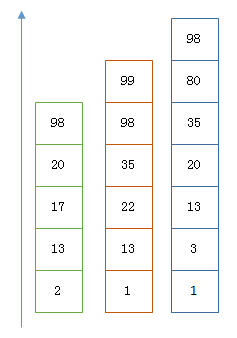
如果使用跳表,對最短的posting list中的每個id,逐個在另外兩個posting list中查找看是否存在,最後得到交集的結果。
如果使用bitset,就很直觀了,直接按位與,得到的結果就是最後的交集。
總結和思考
Elasticsearch的索引思路:
將磁盤裏的東西盡量搬進內存,減少磁盤隨機讀取次數(同時也利用磁盤順序讀特性),結合各種奇技淫巧的壓縮算法,用及其苛刻的態度使用內存。
所以,對於使用Elasticsearch進行索引時需要註意:
- 不需要索引的字段,一定要明確定義出來,因為默認是自動建索引的
- 同樣的道理,對於String類型的字段,不需要analysis的也需要明確定義出來,因為默認也是會analysis的
- 選擇有規律的ID很重要,隨機性太大的ID(比如java的UUID)不利於查詢
關於最後一點,個人認為有多個因素:
其中一個(也許不是最重要的)因素: 上面看到的壓縮算法,都是對Posting list裏的大量ID進行壓縮的,那如果ID是順序的,或者是有公共前綴等具有一定規律性的ID,壓縮比會比較高;
另外一個因素: 可能是最影響查詢性能的,應該是最後通過Posting list裏的ID到磁盤中查找Document信息的那步,因為Elasticsearch是分Segment存儲的,根據ID這個大範圍的Term定位到Segment的效率直接影響了最後查詢的性能,如果ID是有規律的,可以快速跳過不包含該ID的Segment,從而減少不必要的磁盤讀次數,具體可以參考這篇如何選擇一個高效的全局ID方案(評論也很精彩)
轉:http://blog.pengqiuyuan.com/ji-chu-jie-shao-ji-suo-yin-yuan-li-fen-xi/
ElasticSearch原理