
2-性能術語與指標詳解
1.並發數
在理解並發數之前,先提出3個常見的概念,分別是系統用戶數、在線用戶數和並發用戶數。小白發現很多人都會把這3個概念混淆,其實是不一樣的。以BestTest的論壇作為例子,對應的解釋分別如下。
系統用戶數:簡單地說就是該系統的註冊用戶數。例如,BestTest論壇裏存在6666個註冊用戶,他們可以是活躍的,也可以是僵屍的。
在線用戶數:即登錄系統的用戶。例如,其中有666個用戶的狀態為在線,但在線用戶並不一定都會對服務器產生壓力,因為有的用戶登錄後什麽都不幹。
並發用戶數:是對服務器產生壓力的用戶。例如,可能在線的666個用戶中,只有20%的用戶對服務器產生了壓力,這20%的用戶數就是並發用戶數。
那為什麽要關註並發用戶數而不是其他用戶數呢?上面已經提到過,最直接的原因就是只有並發用戶數才對系統產生真正的壓力。就好像一個人提1斤的東西不覺得重,但是提150斤的東西,那可就難以提動了。
在實際應用中,並發數可以通過分析服務器日誌得以確定,這種方式更加準確。一般常用的日誌分析工具有AWStats、Webalizer、Analog、Deep Log Analyzer等。也可以通過業界的一些計算模型得到,後續章節中會學習。
這裏再延伸一下並發的概念。一般有兩種理解方式:一種為所有用戶在同一時刻做同一種操作,主要是為了驗證程序或數據庫對並發的處理能力;另一種為多個用戶對被測系統發起了多個請求,這些請求可以是同一種操作,也可以是不同的操作,類似於混合場景的概念。
2.響應時間
小白通過查找資料發現,大部分資料都是說“響應時間=網絡響應時間+應用程序響應時間”諸如此類的解釋。小白一時間有點摸不著頭腦。於是,靜下心來開始認真分析、研究。
我們可以換個角度去看待這個概念。首先從大的方向上可以把一個系統分為前端與後端,而響應時間也可以按照這個劃分來理解。讓我們先看圖1-1再來理解。
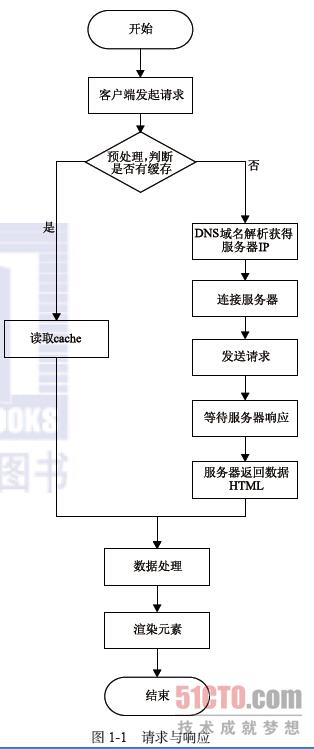
通過圖1-1可以清楚地看出在沒有緩存的情況下,一個請求發出去後,需要經過網絡傳輸、DNS解析等步驟才能到達服務器,服務器處理完後,經由網絡傳輸返回給客戶端,而客戶端接收到以後,要進行解析渲染展示給用戶。這裏需要註意,網絡時間包括請求傳輸的時間和響應傳輸的時間,而服務器也可能是多層處理。
這下邏輯就非常清楚了,可以總結為:響應時間=網絡傳輸(請求)時間+服務器處理(一層或多層)時間+網絡傳輸(響應)時間+頁面前端解析渲染時間。小白終於明白響應時間背後的來龍去脈了。
在實際應用過程中,需要明白響應時間的長短取決於用戶的實際需求,而不是盲目設定該指標。畢竟在BestTest論壇查找一個帖子和在數據統計系統中查找一個月的數據匯總與明細統計是完全不同的,它們的業務有各自獨有的特點,不能簡單地一概而論。
前端頁面的解析展示時間一般在做非前端性能測試中不太會關註,因為每個瀏覽器解析頁面的方式不一樣,時間也會不一樣。
3. 每秒通過事務數
TPS是指每秒通過事務數,是直接反映系統性能的指標,該值大時,系統性能會比較好,當然每個系統都有它的上限,不可能無限大。將它與平均事務響應時間進行對比,可以分析事務數量對響應時間的影響。
例如,當壓力加大時,TPS曲線如果變化緩慢或者有平坦的趨勢,很有可能是服務器開始出現瓶頸了。如果環境沒有發生大的變化,對於同一系統會存在一個最大處理事務能力,它並不隨著並發用戶的多少而改變。就好像傳說中的北京五道口地鐵檢票機一樣,只有兩臺進站檢票的機器,一次一臺機器只能通過一個人,不論是來10個人,還是100個人。
4.每秒點擊數
每秒點擊數代表用戶每秒向Web服務器提交的HTTP請求數。但這裏需要註意的是提交一個登錄請求,對於用戶來說感覺是一個請求,但對於後端服務器來說也許是多個請求,所以點擊一次不代表就是一個請求。例如,點擊一個鏈接,該操作返回的頁面上有6張圖片,因為下載每張圖片都需要一個HTTP請求,所以這個頁面下載完成之後的點擊數應該是7。
每秒點擊數從側面可以反映客戶端的狀況,每秒點擊數不正常,一般可能是網絡問題或者腳本問題導致,需要進一步具體分析。
5.吞吐量
經常在網上看到“吞吐量”與“吞吐率”的概念,也有不少人把兩者混淆。吞吐量是指單位時間內系統處理的請求數量,能直接反映服務器承受的壓力,是需要重點關註的指標。而吞吐率一般指用戶在給定的一秒內從服務器獲得的數據量,簡而言之就是服務器返回的數據量。
例如,一個食品廠的生產效率很高,一天能生產很多食品,但是工廠只有兩輛三輪車在運輸,不難想象會出現什麽樣的可怕場景。這個時候工廠運輸食品的能力就成為了瓶頸,也就是它的吞吐量/吞吐率出現了瓶頸。
6.思考時間
思考時間可以從兩個宏觀的角度來理解。
1)思考時間就是用戶進行操作時,每個請求或者操作之間的間隔時間,是為了更加真實地模擬用戶的操作場景。因為在實際使用中不太可能會出現不斷地發送請求,一般都是一個請求後,等待一段時間,然後發送下一個請求,惡意攻擊除外。
2)小白發現在BestTest論壇連續發帖時會提示“兩次發帖時間間隔不能小於15秒鐘”,這時如果要滿足業務的特定需求就需要加上思考時間15s了。這下小白對思考時間有了進一步的認識,很是高興。
另外,小白經常在網上看到關於0思考時間的討論,自己也有點疑惑,於是請教了經理。經理告訴他,如果想了解系統的最大承受能力或者極端情況下系統的性能表現,則可以設置為0思考時間。但如果是預估系統的性能,就應該最大可能地模擬真實思考時間。一般都會加上思考時間,只是在分析時要去掉思考時間。
7.資源利用率
小白通過查找資料發現,關於資源利用率的資料太多也太雜,根本無法梳理,而且會越看越亂,無奈之下向經理求助,經理告訴他雖然指標很多,但很多時候每個指標間都是有關聯的,而且重點的就是那麽幾個,只要把這幾個理解透徹就行了。小白按照經理的指導開始學習、理解重點的幾個指標。
CPU:它就像是人的大腦,主要是進行判斷和處理,能反映出系統的繁忙程度,一般分為系統CPU與用戶CPU,其中系統CPU是處理系統本身所占用的資源,用戶CPU則是處理程序所占用的資源,對象不同。
Load Average:指一段時間內CPU正在處理和等待CPU處理的任務,也就是CPU使用隊列的長度的統計信息。這裏的Load Average值就好像地鐵裏等待進站上車的乘客,越多則Load Average值也越大。
Memory:它就像是人大腦的記憶區域,將各種信息收集起來存放。數據從內存中讀取要比從磁盤上讀取速度快,而內存經常發生內存泄露或內存溢出的現象,是需要重點留意的。不過這裏需要註意,短時間的可用內存越來越少,不代表一定有內存泄露或溢出。
隊列:可以理解成地鐵進站的排隊現象,隊列長,說明處理能力可能達到了極限或者遇到了阻塞。
IO:與磁盤的交互,重點關註交換頻率和磁盤隊列長度。
網絡:重點關註網絡的流量,看是否存在網絡帶寬的瓶頸。
2-性能術語與指標詳解