
在 Rolling Update 中使用 Health Check - 每天5分鐘玩轉 Docker
現有一個正常運行的多副本應用,接下來對應用進行更新(比如使用更高版本的 image),Kubernetes 會啟動新副本,然後發生了如下事件:
正常情況下新副本需要 10 秒鐘完成準備工作,在此之前無法響應業務請求。
但由於人為配置錯誤,副本始終無法完成準備工作(比如無法連接後端數據庫)。
先別繼續往下看,現在請花一分鐘思考這個問題:如果沒有配置 Health Check,會出現怎樣的情況?
因為新副本本身沒有異常退出,默認的 Health Check 機制會認為容器已經就緒,進而會逐步用新副本替換現有副本,其結果就是:當所有舊副本都被替換後,整個應用將無法處理請求,無法對外提供服務。如果這是發生在重要的生產系統上,後果會非常嚴重。
如果正確配置了 Health Check,新副本只有通過了 Readiness 探測,才會被添加到 Service;如果沒有通過探測,現有副本不會被全部替換,業務仍然正常進行。
下面通過例子來實踐 Health Check 在 Rolling Update 中的應用。
用如下配置文件 app.v1.yml 模擬一個 10 副本的應用:
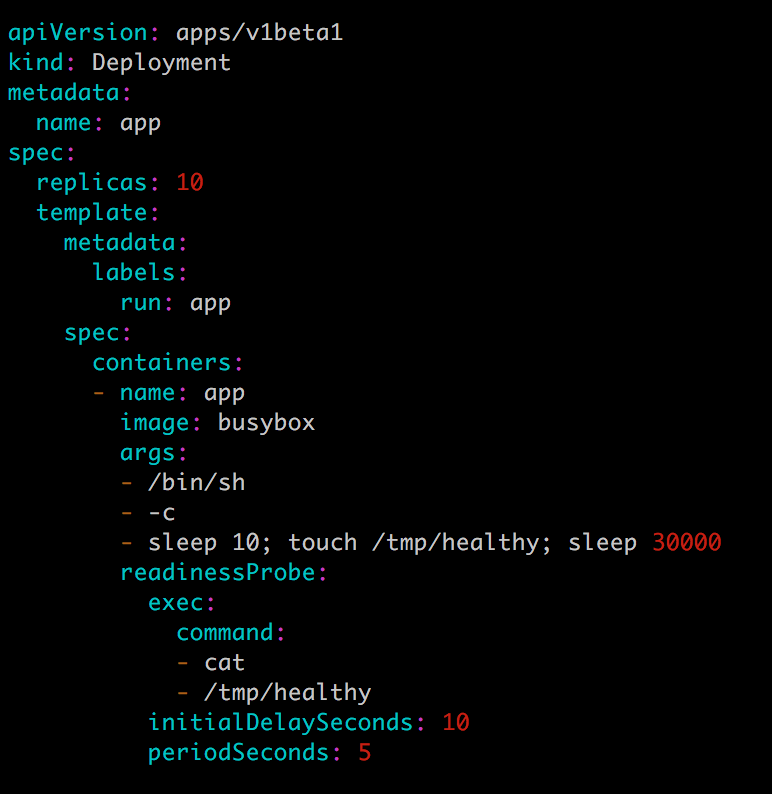
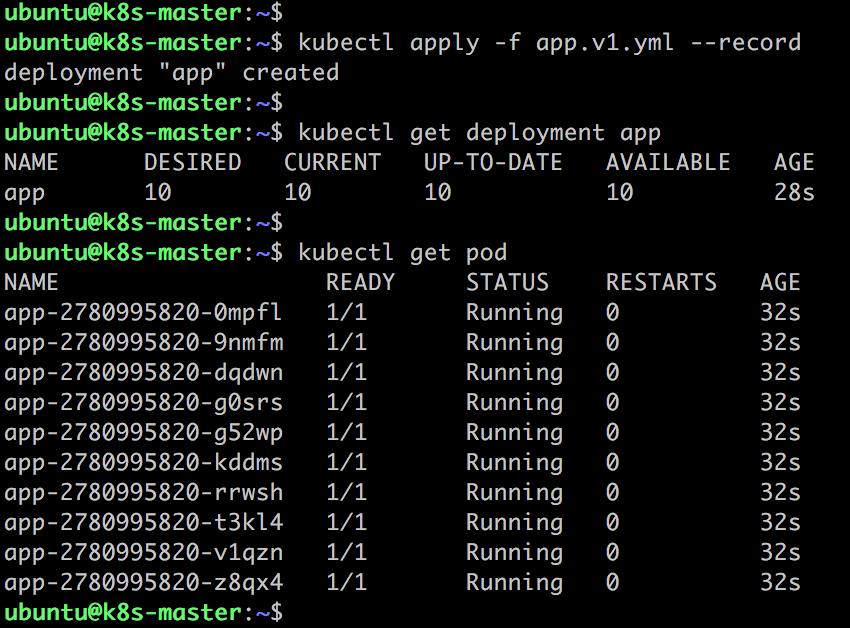
10 秒後副本能夠通過 Readiness 探測。
接下來滾動更新應用,配置文件 app.v2.yml 如下:
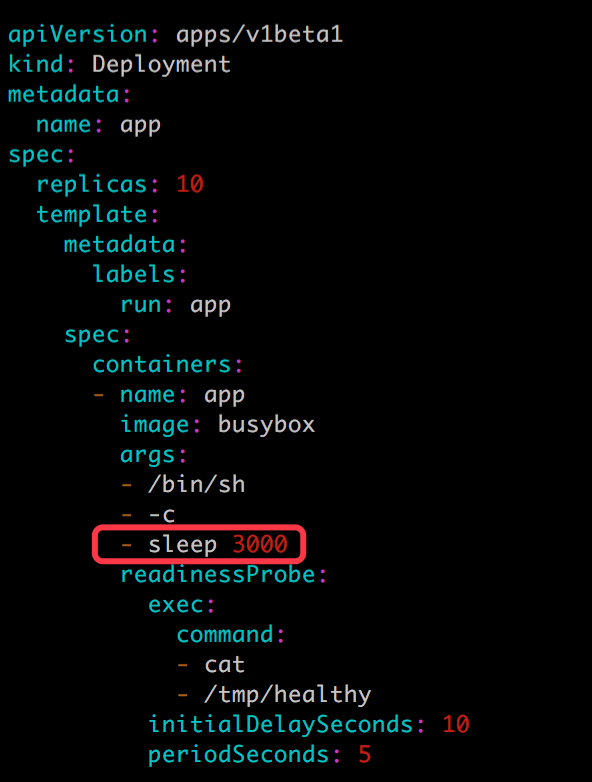
很顯然,由於新副本中不存在 /tmp/healthy,是無法通過 Readiness 探測的。驗證如下:
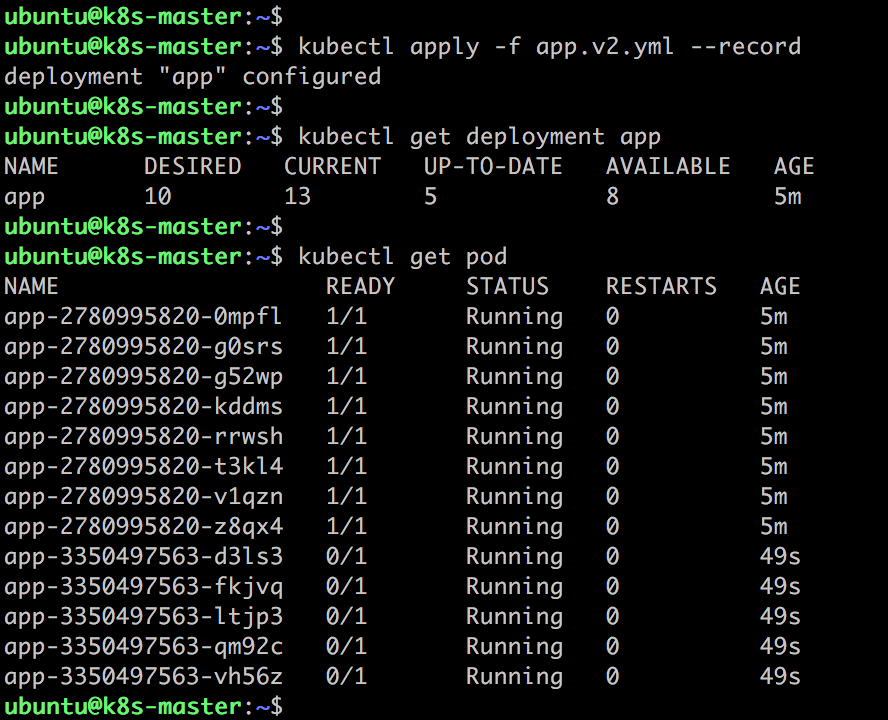
這個截圖包含了大量的信息,值得我們詳細分析。
先關註 kubectl get pod 輸出:
從 Pod 的
AGE欄可判斷,最後 5 個 Pod 是新副本,目前處於 NOT READY 狀態。舊副本從最初 10 個減少到 8 個。
再來看 kubectl get deployment app 的輸出:
DESIRED10 表示期望的狀態是 10 個 READY 的副本。CURRENT13 表示當前副本的總數:即 8 個舊副本 + 5 個新副本。UP-TO-DATE5 表示當前已經完成更新的副本數:即 5 個新副本。AVAILABLE8 表示當前處於 READY 狀態的副本數:即 8個舊副本。
在我們的設定中,新副本始終都無法通過 Readiness 探測,所以這個狀態會一直保持下去。
上面我們模擬了一個滾動更新失敗的場景。不過幸運的是:Health Check 幫我們屏蔽了有缺陷的副本,同時保留了大部分舊副本,業務沒有因更新失敗受到影響。
接下來我們要回答:為什麽新創建的副本數是 5 個,同時只銷毀了 2 個舊副本?
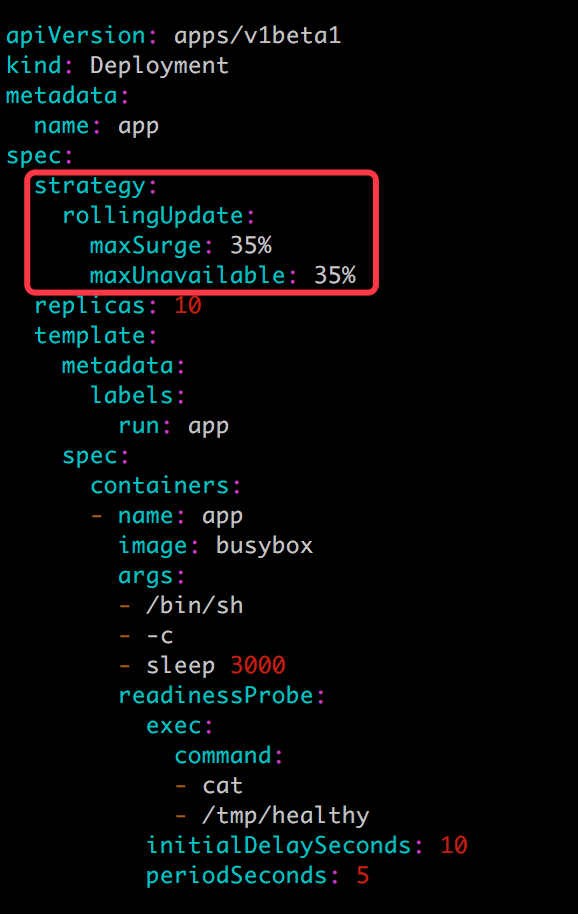
原因是:滾動更新通過參數 maxSurge 和 maxUnavailable 來控制副本替換的數量。
maxSurge
此參數控制滾動更新過程中副本總數的超過 DESIRED 的上限。maxSurge 可以是具體的整數(比如 3),也可以是百分百,向上取整。maxSurge 默認值為 25%。
在上面的例子中,DESIRED 為 10,那麽副本總數的最大值為:
roundUp(10 + 10 * 25%) = 13
所以我們看到 CURRENT 就是 13。
maxUnavailable
此參數控制滾動更新過程中,不可用的副本相占 DESIRED 的最大比例。 maxUnavailable 可以是具體的整數(比如 3),也可以是百分百,向下取整。maxUnavailable 默認值為 25%。
在上面的例子中,DESIRED 為 10,那麽可用的副本數至少要為:
10 - roundDown(10 * 25%) = 8
所以我們看到 AVAILABLE 就是 8。
maxSurge 值越大,初始創建的新副本數量就越多;maxUnavailable 值越大,初始銷毀的舊副本數量就越多。
理想情況下,我們這個案例滾動更新的過程應該是這樣的:
首先創建 3 個新副本使副本總數達到 13 個。
然後銷毀 2 個舊副本使可用的副本數降到 8 個。
當這 2 個舊副本成功銷毀後,可再創建 2 個新副本,使副本總數保持為 13 個。
當新副本通過 Readiness 探測後,會使可用副本數增加,超過 8。
進而可以繼續銷毀更多的舊副本,使可用副本數回到 8。
舊副本的銷毀使副本總數低於 13,這樣就允許創建更多的新副本。
這個過程會持續進行,最終所有的舊副本都會被新副本替換,滾動更新完成。
而我們的實際情況是在第 4 步就卡住了,新副本無法通過 Readiness 探測。這個過程可以在 kubectl describe deployment app 的日誌部分查看。

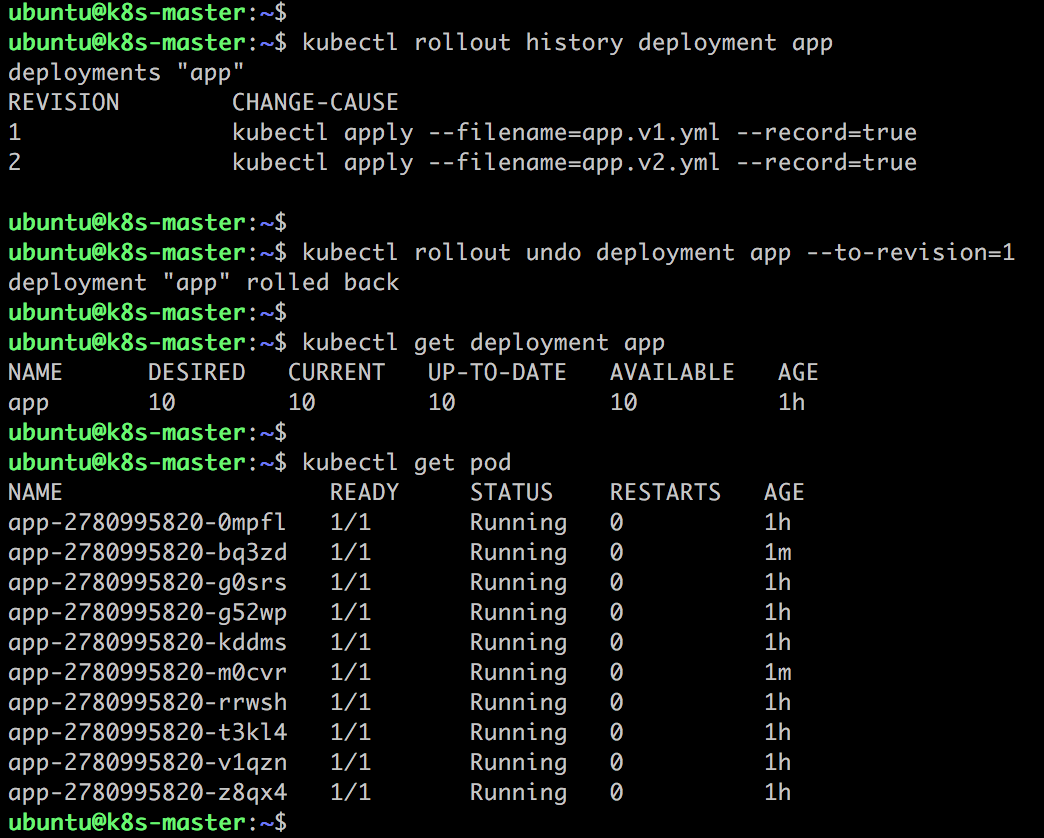
如果滾動更新失敗,可以通過 kubectl rollout undo 回滾到上一個版本。
如果要定制 maxSurge 和 maxUnavailable,可以如下配置:
小結
本章我們討論了 Kubernetes 健康檢查的兩種機制:Liveness 探測和 Readiness 探測,並實踐了健康檢查在 Scale Up 和 Rolling Update 場景中的應用。
下節我們開始討論 Kubernetes 如何管理數據。
書籍:
1.《每天5分鐘玩轉Kubernetes》
https://item.jd.com/26225745440.html
2.《每天5分鐘玩轉Docker容器技術》
https://item.jd.com/16936307278.html
3.《每天5分鐘玩轉OpenStack》
https://item.jd.com/12086376.html

在 Rolling Update 中使用 Health Check - 每天5分鐘玩轉 Docker