
那些年繞過的反爬手段
筆者第一份工作就是以java工程師的名義寫爬蟲,不得不說第一份工作很重要啊,現在除了爬蟲不會幹別的,到現在已經幹了近5年了,期間經歷了不少與反爬策略的鬥爭。最近又耗時兩周成功搞定了某網站的反爬策略後,心裏有點莫名的惆悵。今日無心工作,就總結下這些年與網站互懟的經驗吧。
無反爬裸站
現在一個網站或多或少都會配置一定的反爬措施,畢竟現在一臺筆記本的性能比某些小站的服務器都強,如果不加以限制,分分鐘就能把你的資源耗盡。前兩年的工商網站有個省份沒有限制,沒多久就把服務器抓癱了(只能說服務器配置太太太次了);如果你服務器能抗那就更好了,用不了多久就能把你全站數據抓下來。記得兩年前收集企業名錄,一個網站幾百萬條用了不到兩個小時就抓完了。但現在心態變了,如果遇到一個沒有驗證碼的網站,我都會盡量抓得慢一點。畢竟都是搞編程的,你如果把人家抓急了,逼得他改網站,改完後自己還得跟著改,冤冤相報何時了?在此也希望大家能手下留情,不要遇見個好欺負的就往死裏整,畢竟咱們要的是數據,又不是來尋仇的。
驗證碼
驗證碼可以說是最基本最常見的反爬策略了,但在某種程度上也是最容易破解的。
弱驗證碼
這裏說的弱驗證碼就是那種直接扔給tesseract就能識別出來的,或者經過簡單處理。比如
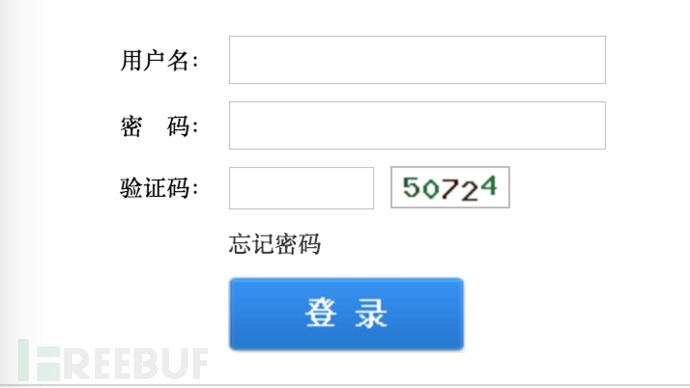
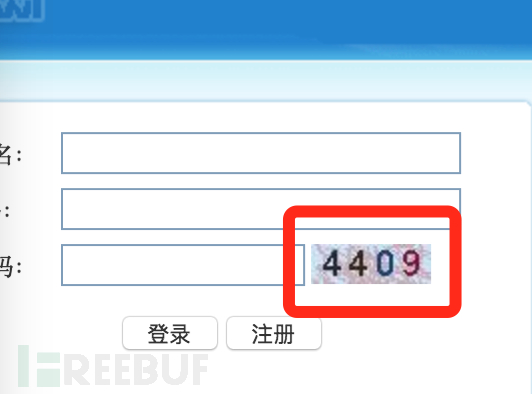
上面兩種驗證碼,第一種不用任何處理直接用pytesseract就可以識別。第二種經過簡單的灰度變換->二值化後能得到比較幹凈清晰的圖像,再用tesseract就可以識別了。如下圖
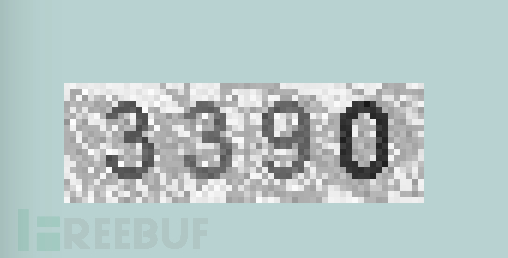

假驗證碼
假驗證碼就是那種用來嚇唬人的驗證碼。比如之前某汽活動頁上面的驗證碼會隱藏在頁面中,點擊提交時會用js判斷驗證碼是否正確。還有的網站驗證碼就是擺設,提交的表單中根本就沒有驗證碼參數。
強驗證碼
像下面這種驗證碼可以算是正常的驗證碼了,由於有變形與粘連,簡單的處理已經無法識別了。

對於這種驗證碼用神經網絡可以達到很高的識別率,但訓練耗時較長(如果有gpu會快很多),而且需要大量標註的樣本。筆者用了2萬個樣本做訓練,識別率能達到86%左右。
神經網絡有個缺陷是只能識別“學習”過的樣本,對於英文加數字來說除去大小寫只有36種可能,所以識別率會很高。但識別難度與訓練強度會隨著分類數量成指數級提高。所以筆者認為,使用中文做驗證碼並對圖像做混淆粘連處理後就可以算是強驗證碼了(話不能說太滿,畢竟我只是個數學很差的專科生)。
請求限制
即對請求速度有限制,或封禁的手段
偽封ip
為什麽要加個“偽”字呢?因為對於某些網站,它們會將某些請求頭中的ip看作用戶的真實ip,比如X-Forwarded-For
X-Real-IP, Via。對於這種網站該怎麽做不用我多說了吧。之前某些省份的工商網站就用了這種手段。
ua限制
即User-Agent,有些網站用User-Agent當作用戶的惟一標識,這種手段會有很大的誤傷,所以很少見,一般只出現在小網站上。
cookie
某些網站會通過set-cookie將請求次數寫在用戶的cookie裏,寫代碼時只要禁用cookie就行了。
加密
常用的加密算法也就那幾種:對稱加密的AES, DES;消息摘要的md5, sha1;此外還有使用定制的base64編碼;筆者在網頁中還沒見過到使用非對稱加密的,在app中也很少見到。
對於對稱加密只要找到密鑰就沒事了,如果AES使用的CBC模式,還需要找出iv。關於AES的ECB, CBC工作模式大家可以百度下。
消息摘要一般用來作簽名,服務端會用它判斷請求參數是否被非法篡改。這也不難,一般是把參數值(有時也包含參數名)按一定順序再加上某些計算就能得到。
對於定制的base64,只要找出未公開的碼表就行了,這個之前有人分享過。好像新版的極驗裏就有用到。
非對稱加密一般很少見,但現在的app更多的會用到SSL Certificate Pinning技術。不知大家有沒有遇到過某些app,一使用burp suite或fiddler抓包就無法聯網,關上代理後就正常了,這就是ssl證書綁定,簡單來說就是app使用自簽名的證書與服務端建立ssl。https協議在建立連接之前客戶端會將預置的公鑰和服務端返回的證書做比較。如果一致,就建立連接,否則就拒絕連接,從而導致程序無法聯網。關於SSL pinning的詳情與破解可以參考這篇文章突破https——https抓包
其他渠道
有時網站的反爬做得比較厲害,繼續懟的話要麽太費時要麽太費力,這時不妨換個路子。比如去年有段時間裁判文書網用了某數的waf,分析了將近一個月沒有成果,但發現該網站還有個app,做得特別low,經過簡單抓包逆向後成功拿到數據,而且數據還是json格式化後的,連解析都省了。還有的網站pc端是www.xxx.com,如果換成移動端的ua會變成m.xxx.com,而一般移動端的頁面比較簡潔,反爬策略可能與主站不一樣。通過查找子域名可能會有收獲。
以上是暫時想到的一些經驗,希望能有所幫助,同時也希望大家在抓數據的時候能夠手留情別抓得太狠,如果把一個數據源抓廢了對大家都不好,正好那句話說的,IT人何苦為難IT人。
那些年繞過的反爬手段