
並發-尊貴鉑金
一,鎖原理的前生今世
synchronized的出現
眾所周知,JAVA中最簡單的加鎖方法是用關鍵字synchronized,我們可以使用這個關鍵字將一個方法變成線程安全的,也可以將一個代碼塊變成線程安全的,這樣子我們不需要再擔心多線程同時執行到這段代碼會引發的並發問題。同時配合方法wait,notify和notifyall可以很好的實現多線程之間的協作,比如某個線程因為需要等待一些資源,於是調用wait方法將自己設置為waiting狀態,其他線程釋放或生產這個線程需要的資源的時候需要通知這個線程(notify)將其喚醒,或者通知所有等待當前資源的線程(notifyall)。
然而當功能完成之後我們似乎並不滿足於此,於是我們開始考慮這麽做的代價是什麽,是否可以做的更好。
先說說這麽做(使用synchronized)的代價是什麽,當多個線程請求臨界資源的時候只能有一個線程得到滿足,那麽其他的線程會做什麽呢,他們會被阻塞,直到被通知(notify/notifyall)又有資源的時候才被喚醒進行再一次的鎖爭用,而後往復的是又只有一個線程能被得到滿足,其他的線程繼續進入阻塞狀態,而這個時候可能會有不斷的增加爭用線程。性能損耗的關鍵點在於線程的阻塞操作是由操作系統來完成的,在Linux系統下是由pthread_mutex_lock函數來完成。線程被阻塞之後便進入了內核調度態,這個過程發生了操作系統將保存用戶態的上下文進入內核態,這也就是常說的上下文切換,上下文切換代價大,在於操作系統需要將當前線程執行上下文內容(包括堆棧、寄存器等存儲的內容)的保存以便之後線程切換回來時候再進行現場恢復。
上面可以看出使用synchronized的代價是什麽了吧,當競爭激烈的時候會引起頻繁的操作系統上下文切換,從而影響系統的性能。
自旋鎖對synchronized的初步優化
自旋鎖是對線程阻塞的一種優化,他的原理簡單的說就是當線程爭用鎖失敗的時候不立即進入阻塞狀態,而是再等一會,因為對於執行時間短的代碼這一會可能就會釋放鎖,而線程就不需要進行一次阻塞與喚醒。等待操作就是讓線程多執行幾個空指令,至於等待多久這跟具體的處理器實現有關,也有可能處理器根本不支持自旋鎖,具體實現的時候我們可以設置一個臨界值,當超過了這個臨界值之後我們就不自旋了,就乖乖進入阻塞狀態吧。這種優化對於執行時間短的代碼是很有效的。synchronized使用自旋鎖的時機是線程進入等待隊列即阻塞的前一步。
輕量級鎖原理
輕量級鎖能提升程序同步性能的依據是“對於絕大部分的鎖,在整個同步周期內都是不存在競爭的”,這是一個經驗數據。如果沒有競爭,輕量級鎖使用CAS操作避免了使用互斥量的開銷,但如果存在鎖競爭,除了互斥量的開銷外,還額外發生了CAS操作,因此在有競爭的情況下,輕量級鎖會比傳統的重量級鎖更慢。
偏向鎖有什麽X用
偏向鎖是java6提供的一種功能,主要是對無競爭條件下的對加鎖代碼執行的優化。目的是消除數據在無競爭情況下的同步原語,進一步提高程序的運行性能。如果說輕量級鎖是在無競爭的情況下使用CAS操作去消除同步使用的互斥量,那偏向鎖就是在無競爭的情況下把整個同步都消除掉,連CAS操作都不做了。偏向鎖會偏向於第一個獲得它的線程(Mark Word中的偏向線程ID信息),如果在接下來的執行過程中,該鎖沒有被其他的線程獲取,則持有偏向鎖的線程將永遠不需要再進行同步。假設當前虛擬機啟用了偏向鎖(啟用參數-XX:+UseBiasedLocking,JDK 1.6的默認值),當鎖對象第一次被線程獲取的時候,虛擬機將會把對象頭中的標誌位設為“01”,即偏向模式。同時使用CAS操作把獲取到這個鎖的線程的ID記錄在對象的Mark Word之中,如果CAS操作成功,持有偏向鎖的線程以後每次進入這個鎖相關的同步塊時,虛擬機都可以不再進行任何同步操作(例如Locking、Unlocking及對Mark Word的Update等)。當有另外一個線程去嘗試獲取這個鎖時,偏向模式就宣告結束。根據鎖對象目前是否處於被鎖定的狀態,撤銷偏向(Revoke Bias)後恢復到未鎖定(標誌位為“01”)或輕量級鎖定(標誌位為“00”)的狀態,後續的同步操作就如上面介紹的輕量級鎖那樣執行。偏向鎖可以提高帶有同步但無競爭的程序性能。它同樣是一個帶有效益權衡(Trade Off)性質的優化,也就是說它並不一定總是對程序運行有利,如果程序中大多數的鎖都總是被多個不同的線程訪問,那偏向模式就是多余的。
JUC的Lock(可重入鎖和讀寫鎖)
Lock是JAVA5增加的內容,在JUC(java.util.concurrent.locks)包下面,作者是並發大師Doug Lea。JUC包提供了很多封裝的鎖,包括常用的ReentrantLock和ReadWriteLock。這些所其實都是依賴java.util.concurrent.AbstractQueuedSynchronizer(AQS)這個類來實現的,這個類有個簡寫的名字叫AQS,對這就是著名的AQS。
關於Lock,先說說線程獲取Lock鎖的時候會引起哪些事件呢。首先AQS是依賴一個被volatile修飾的int變量來標識當前鎖的狀態的,為0的時候代表當前鎖不被任何線程擁有,當線程拿到這個鎖的時候會通過CAS操作修改state的狀態,那麽對於爭用失敗的線程AQS會怎麽辦呢,AQS內部維護了一個等待隊列,這個隊列是純JAVA實現的,其實現也是非常巧妙的,多線程在通過CAS來獲取自己在隊列中的位置,同時隊列中的線程狀態也是阻塞狀態,遇到阻塞就頭疼了,上面已經介紹過阻塞會帶來的性能問題。在源碼中我們可以看到的是AQS通過LockSupport(LockSupport底層依賴Unsafe)將線程阻塞,關於LockSupport其功能是用來代替wait和notity/notifyall的,更好的地方是LockSupport對park方法和unpark方法的調用沒有先後的限制,而notify/notifyall必須在wait調用之後調用。盡管如此,這一切並沒有阻止線程進入阻塞狀態。
可重入鎖原理
可重入鎖就是當前持有該鎖的線程能夠多次獲取該鎖,無需等待。基於AQS實現,AQS是JDK1.5提供的一個基於FIFO等待隊列實現的一個用於實現同步器的基礎框架,這個基礎框架的重要性可以這麽說,JUC包裏面幾乎所有的有關鎖、多線程並發以及線程同步器等重要組件的實現都是基於AQS這個框架。AQS的核心思想是基於volatile int state這樣的一個屬性同時配合Unsafe工具對其原子性的操作來實現對當前鎖的狀態進行修改。當state的值為0的時候,標識改Lock不被任何線程所占有。
作為AQS的核心實現的一部分,舉個例子,我們假設目前有三個線程Thread1、Thread2、Thread3同時去競爭鎖,如果結果是Thread1獲取了鎖,Thread2和Thread3進入了等待隊列,AQS的等待隊列基於一個雙向鏈表實現的,HEAD節點不關聯線程,後面兩個節點分別關聯Thread2和Thread3,他們將會按照先後順序被串聯在這個隊列上。這個時候如果後面再有線程進來的話將會被當做隊列的TAIL。當三個線程同時進來,他們會首先會通過CAS去修改state的狀態,如果修改成功,那麽競爭成功,因此這個時候三個線程只有一個CAS成功,其他兩個線程失敗,也就是tryAcquire返回false。接下來,addWaiter會把將當前線程關聯的EXCLUSIVE類型的節點入隊列如果隊尾節點不為null,則說明隊列中已經有線程在等待了,那麽直接入隊尾。如果Thread2和Thread3同時進入了enq,同時t==null,則進行CAS操作對隊列進行初始化,這個時候只有一個線程能夠成功,然後他們繼續進入循環,第二次都進入了else代碼塊,這個時候又要進行CAS操作,將自己放在隊尾,因此這個時候又是只有一個線程成功,我們假設是Thread2成功,哈哈,Thread2開心的返回了,Thread3失落的再進行下一次的循環,最終入隊列成功,返回自己。當有多個線程,或者說很多很多的線程同時執行的時候,怎麽能保證最終他們都能夠乖乖的入隊列而不會出現並發問題的呢?這也是這部分代碼的經典之處,多線程競爭,熱點、單點在隊列尾部,多個線程都通過【CAS+死循環】這個free-lock黃金搭檔來對隊列進行修改,每次能夠保證只有一個成功,如果失敗下次重試,如果是N個線程,那麽每個線程最多loop N次,最終都能夠成功。上面只是addWaiter的實現部分,那麽節點入隊列之後會繼續發生什麽呢,如果Thread1死死的握住鎖不放,那麽Thread2和Thread3現在的狀態就是掛起狀態啦,而且HEAD,以及Thread的waitStatus都是SIGNAL,盡管他們在整個過程中曾經數次去嘗試獲取鎖,但是都失敗了,失敗了不能死循環呀,所以就被掛起了。
鎖釋放-等待線程喚起首先,Thread1會修改AQS的state狀態,加入之前是1,則變為0,註意這個時候對於非公平鎖來說是個很好的插入機會,舉個例子,如果鎖是公平鎖,這個時候來了Thread4,那麽這個鎖將會被Thread4搶去。
我們繼續走常規路線來分析,當Thread1修改完狀態了,判斷隊列是否為null,以及隊頭的waitStatus是否為0,如果waitStatus為0,說明隊列無等待線程,按照我們的例子來說,隊頭的waitStatus為SIGNAL=-1,因此這個時候要通知隊列的等待線程,可以來拿鎖啦,這也是unparkSuccessor做的事情,unparkSuccessor主要做三件事情:
-
將隊頭的waitStatus設置為0.
-
通過從隊列尾部向隊列頭部移動,找到最後一個waitStatus<=0的那個節點,也就是離隊頭最近的沒有被cancelled的那個節點,隊頭這個時候指向這個節點。
-
將這個節點喚醒,其實這個時候Thread1已經出隊列了。
還記得線程在哪裏掛起的麽,上面說過了,在acquireQueued裏面,我沒有貼代碼,自己去看哦。這裏我們也大概能理解AQS的這個隊列為什麽叫FIFO隊列了,因此每次喚醒僅僅喚醒隊頭等待線程,讓隊頭等待線程先出。當有多個線程去競爭同一個鎖的時候,假設鎖被某個線程占用,那麽如果有成千上萬個線程在等待鎖,有一種做法是同時喚醒這成千上萬個線程去去競爭鎖,這個時候就發生了羊群效應,海量的競爭必然造成資源的劇增和浪費,因此終究只能有一個線程競爭成功,其他線程還是要老老實實的回去等待。AQS的FIFO的等待隊列給解決在鎖競爭方面的羊群效應問題提供了一個思路:保持一個FIFO隊列,隊列每個節點只關心其前一個節點的狀態,線程喚醒也只喚醒隊頭等待線程。
無鎖才是大BOSS
講到無鎖,必然是Disruptor並發框架,Disruptor底層依賴一個RingBuffer來進行線程之間的數據交換,無鎖在於在並發條件下,多線程對RingBuffer的讀和寫不會涉及到鎖,然而因為RingBuffer滿或者RingBuffer中沒有可消費內容引發的線程等待,那就要另當別論了。簡單幾句介紹下無鎖原理,RingBuffer維護者可讀和可寫的指針,也叫遊標,它指向生產者或消費者需要寫或讀的位置,而對於指針的更新是由CAS來完成的,這個過程中我們不需要加鎖/解鎖的過程。
Disruptor(無鎖並發框架)
1.ring buffer是由一個大數組組成的。
2.所有ring buffer的“指針”(也稱為序列或遊標)是java long類型的(64位有符號數),指針采用往上計數自增的方式。(不用擔心越界,即使每秒1,000,000條消息,也要消耗300,000年才可以用完)。
3.對ring buffer中的指針進行按ring buffer的size取模找出數組的下標來定位入口(類似於HashMap的entry)。為了提高性能,我們通常將ring buffer的size大小設置成實際使用的2倍。
這樣我們可以通過位運算(bit-mask )的方式計算出數組的下標。
Ring buffer的基礎結構
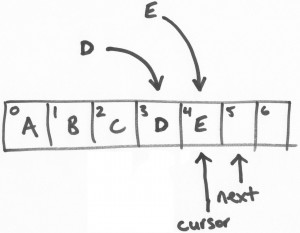
ring buffer維護兩個指針,“next”和“cursor”。
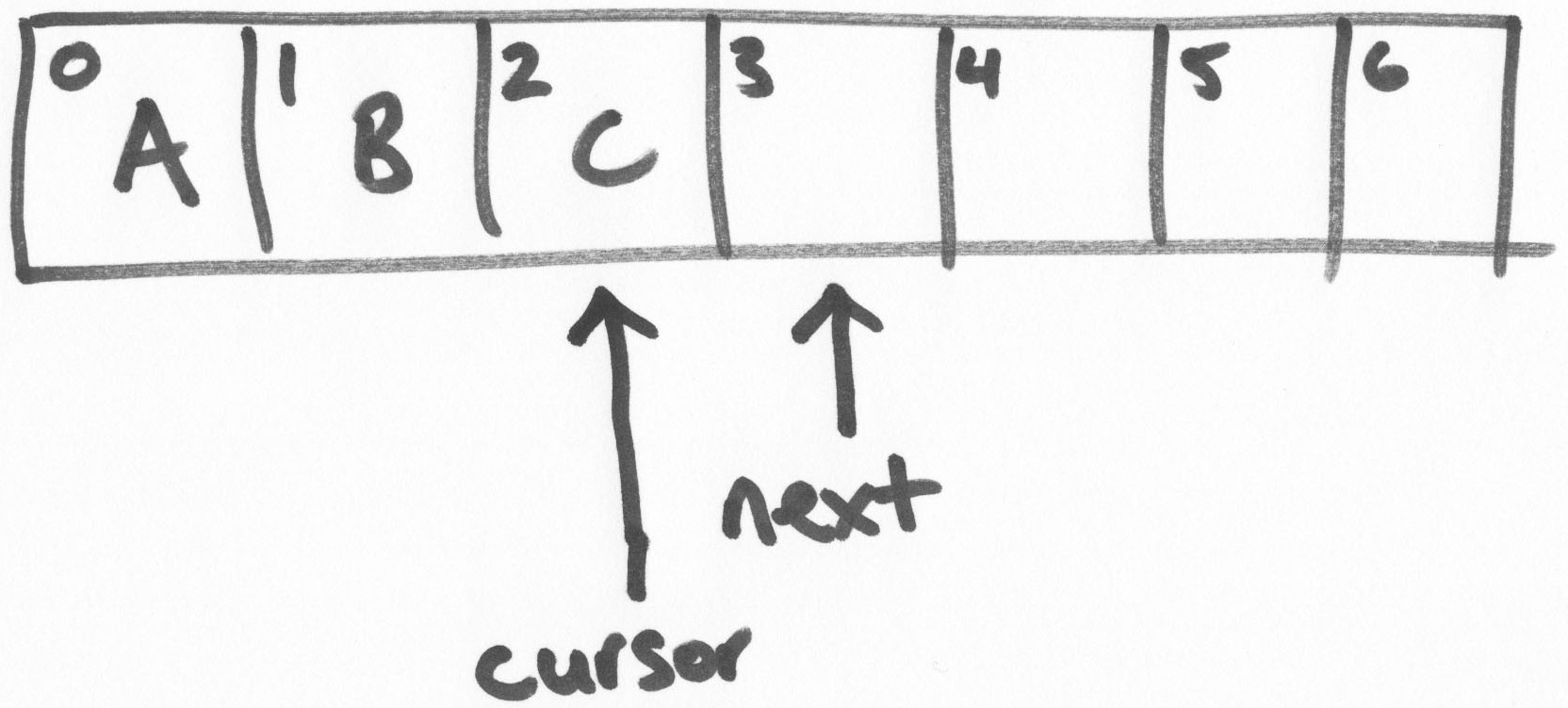
在上面的圖示裏,是一個size為7的ring buffer,從0-2的坐標位置是填充了數據的。
“next”指針指向第一個未填充數據的區塊。“cursor”指針指向最後一個填充了數據的區塊。在一個空閑的ring bufer中,它們是彼此緊鄰的,如上圖所示。
填充數據(Claiming a slot,獲取區塊)
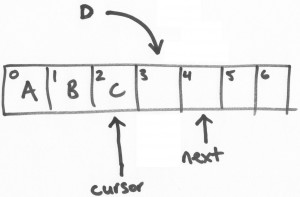
Disruptor API 提供了事務操作的支持。當從ring buffer獲取到區塊,先是往區塊中寫入數據,然後再進行提交的操作。
假設有一個線程負責將字母“D”寫進ring buffer中。將會從ring buffer中獲取一個區塊(slot),這個操作是一個基於CAS的“get-and-increment”操作,將“next”指針進行自增。這樣,當前線程(我們可以叫做線程D)進行了get-and-increment操作後,
指向了位置4,然後返回3。這樣,線程D就獲得了位置3的操作權限。
接著,另一個線程E做類似以上的操作。
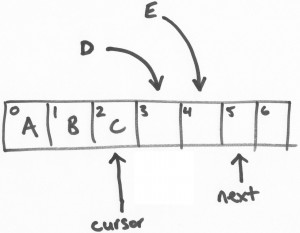
提交寫入
以上,線程D和線程E都可以同時線程安全的往各自負責的區塊(或位置,slots)寫入數據。但是,我們可以討論一下線程E先完成任務的場景…
線程E嘗試提交寫入數據。在一個繁忙的循環中有若幹的CAS提交操作。線程E持有位置4,它將會做一個CAS的waiting操作,直到 “cursor”變成3,然後將“cursor”變成4。
再次強調,這是一個原子性的操作。因此,現在的ring buffer中,“cursor”現在是2,線程E將會進入長期等待並重試操作,直到 “cursor”變成3。
然後,線程D開始提交。線程E用CAS操作將“cursor”設置為3(線程E持有的區塊位置)當且僅當“cursor”位置是2.“cursor”當前是2,所以CAS操作成功和提交也成功了。
這時候,“cursor”已經更新成3,然後所有和3相關的數據變成可讀。
這是一個關鍵點。知道ring buffer填充了多少 – 即寫了多少數據,那一個序列數寫入最高等等,是遊標的一些簡單的功能。“next”指針是為了保證寫入的事務特性。
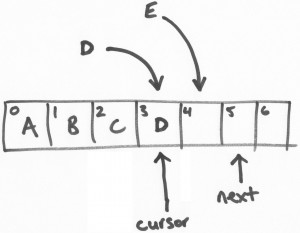
最後的疑惑是線程E的寫入可見,線程E一直重試,嘗試將“cursor”從3更新成4,經過線程D操作後已經更新成3,那麽下一次重試就可以成功了。
寫入數據可見的先後順序是由線程所搶占的位置的先後順序決定的,而不是由它的提交先後決定的。但你可以想象這些線程從網絡層中獲取消息,這是和消息按照時間到達的先後順序是沒什麽不同的,而兩個線程競爭獲取一個不同循序的位置。
總結:
在Synchronized優化以前,synchronized的性能是比ReenTrantLock差很多的,但是自從Synchronized引入了偏向鎖,輕量級鎖(自旋鎖)後,兩者的性能就差不多了,在兩種方法都可用的情況下,官方甚至建議使用synchronized,其實synchronized的優化我感覺就借鑒了ReenTrantLock中的CAS技術。都是試圖在用戶態就把加鎖問題解決,避免進入內核態的線程阻塞。很明顯Synchronized的使用比較方便簡潔,並且由編譯器去保證鎖的加鎖和釋放,而ReenTrantLock需要手工聲明來加鎖和釋放鎖,為了避免忘記手工釋放鎖造成死鎖,所以最好在finally中聲明釋放鎖。
ReenTrantLock獨有的能力:
1. ReenTrantLock可以指定是公平鎖還是非公平鎖。而synchronized只能是非公平鎖。所謂的公平鎖就是先等待的線程先獲得鎖。
2. ReenTrantLock提供了一個Condition(條件)類,用來實現分組喚醒需要喚醒的線程們,而不是像synchronized要麽隨機喚醒一個線程要麽喚醒全部線程。
3. ReenTrantLock提供了一種能夠中斷等待鎖的線程的機制,通過lock.lockInterruptibly()來實現這個機制。
並發-尊貴鉑金