
hive 表的創建的操作與測試
阿新 • • 發佈:2018-04-11
大數據 hadoop hive
- Hive 中創建表的三種方式,應用場景說明及練習截圖
- 內部表和外部表的區別,練習截圖
- 分區表的功能、創建,如何向分區表中加載數據、如何檢索分區表中的數據,練習截圖
一:hive HQL 的表操作:
1.1.1創建數據庫:
hive> create database yangyang;
hive> desc database yangyang;
刪除數據庫:
hive> drop database yangyang casecad; ----> casecad 表示有表也刪除1.1.2創建測試表:
emp表:
create table emp( empno int, ename string, job string, mgr int, hiredate string, sal double, comm double, deptno int ) row format delimited fields terminated by ‘\t‘;
dept表:
create table dept(
deptno int,
dname string,
loc string
)
row format delimited fields terminated by ‘\t‘;
1.1.3 導入測試數據:
load data local inpath "/home/hadoop/emp.txt" into table emp; load data local inpath "/home/hadoop/dept.txt" into table dept; 註釋: --local表示本地 --overwrite表示覆蓋(默認情況使用的是append) 一般要加上overwrite 表示覆蓋

1.1.4 查看數據信息:
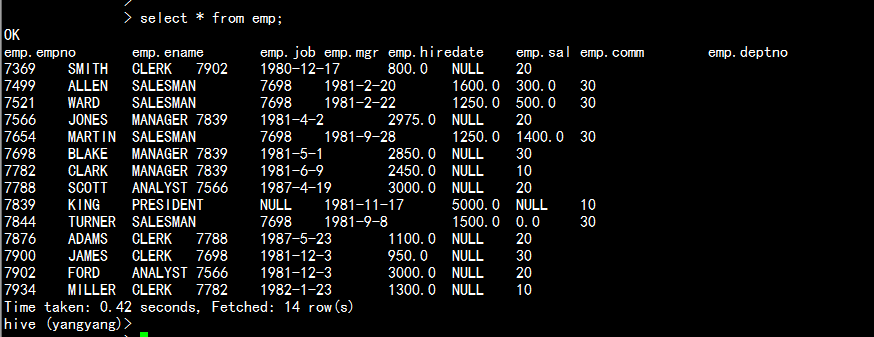
查看emp 表的信息
select * from emp;
desc fromatted emp;
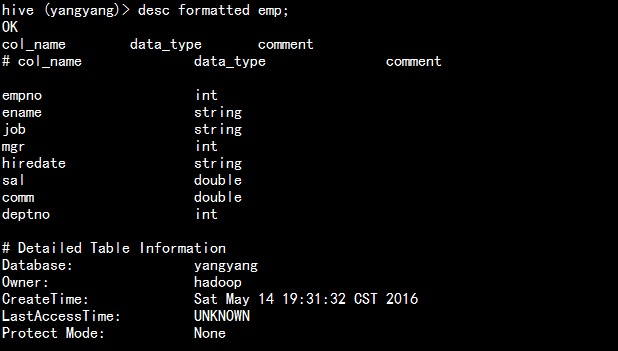

查看dept表:
select * from dept;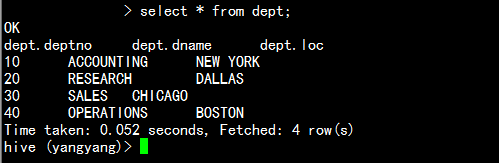


清空一個表:
truncate table emp;
重新命名一個表:
alter table emp rename to emp_bak;
補充hive 的操作:
hive 交互式登錄:
bin/hive -e "select * from test01.dept;"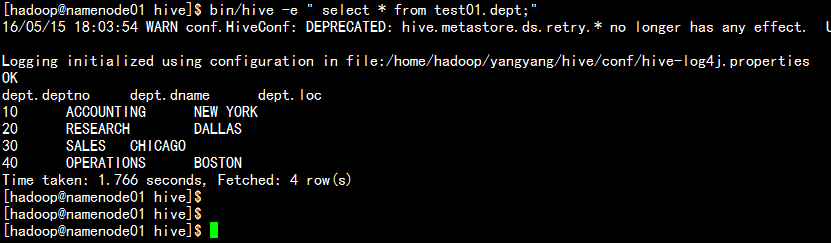
hive 執行sql 語句
bin/hive -f 可以執行編寫的好的SQL 語句。
bin/hive -f 1.sql 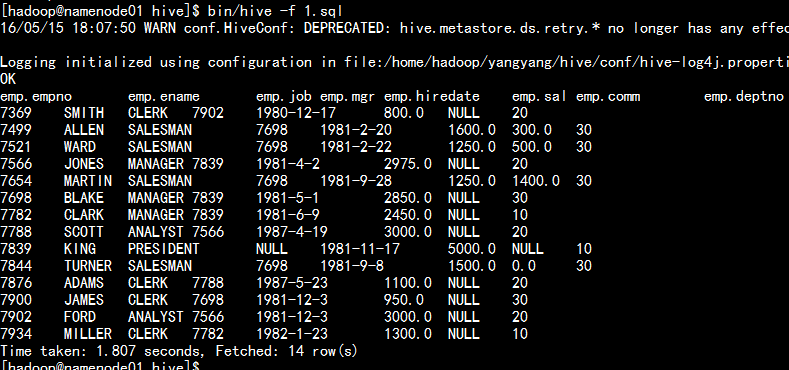
二:hive的數據表的類型:
hive 有三種表的類型:
hive 的管理表也可以稱為內部表: 默認表類型。
1.數據存放的MANAGED_TABLE 內部
2.默認數據存儲在倉庫位置目錄/user/hive/warehouse/下面,每創建一個庫,就是一個目錄,建表就會生成文件。
3.刪除表的時候,也會刪除HDFS上面的文件。create table dept1(
deptno int,
dname string,
loc string
)
row format delimited fields terminated by ‘\t‘;
導入數據處理:
load data local inpath "/home/hadoop/dept.txt" into table dept1;2.1 hive 的外部表
應用場景面對不同的業務,提取數據處理。
業務1 業務2 業務3
drop select
2.1.1 數據存放的MANAGED_TABLE 內部
2.1.2 一般我們會使用location去指定存放到其他位置
2.1.3 刪除表的時候,不會去刪除HDFS上面的文體,只刪除元數據create table dept2(
deptno int,
dname string,
loc string
)
row format delimited fields terminated by ‘\t‘ location ‘/hive/dept2‘;
導入數據處理
load data local inpath "/home/hadoop/dept.txt" into table dept2;2.2:hive的分區表
使用業務場景:
2.2.1 時間增量數據
2.2.2 提高查詢速度(核心)
2.2.3 一級分區、二級分區 partitioned by (date string,time string)
2.2.4 創建表時需要給定partitioned 處理 一般是 指定日期為string 類型。create table emp3(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal double,
comm double,
deptno int
)
partitioned by (data string)
row format delimited fields terminated by ‘\t‘;
導入數據的時候要加上partitioned處理。
load data local inpath "/home/hadoop/emp.txt" into table emp3 partition (date=‘20150515‘);
查找可以用按 分區去查找
select * from emp3 where date=‘20150515‘;hive 中 創建桶表:
create table emp4(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal double,
comm double,
deptno int
)
clustered by(empno) into 3 buckets
row format delimited fields terminated by ‘\t‘;
默認情況下load 加載時不分桶表:
強制設置分區:set hive.enforce.bucketing = true;
可以使用查詢其它表加載到桶表,
插入數據: insert into emp4 select * from emp4;
hive> dfs -lsr /
hive 中的桶表數量如何去設置
評估數據量,保證每個桶的數據量block 的2倍大小

上傳 文件到 分區表當中 沒有帶分區等相關信息 就需要修復分區表:
msck repair table emp3 ;
或者:
alter table emp3 add partition(date=‘20150515‘);hive 表的創建的操作與測試