
hive 的數據案例 統計網站的數據信息
阿新 • • 發佈:2018-04-12
大數據 hadoop hive 數據清洗
- 根據hive的案例一增加需求
一: 增加案例需求:
統計 pv , uv , 登錄人數 , 遊客人數 , 平均訪問時長 , 二跳率 , 獨立IP
用一張表去處理1.1 查看track_log的分區
show partitions track_log ;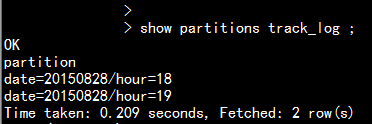
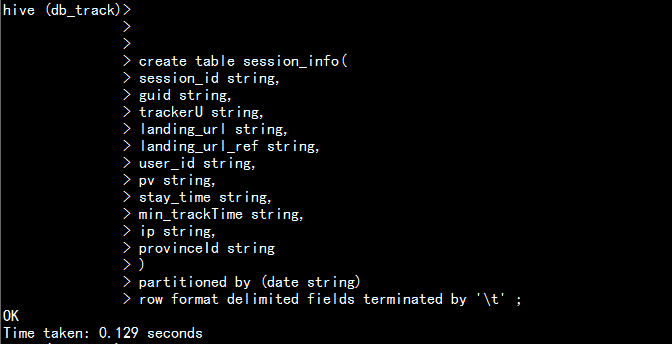
1.2 建立一張會話信息表(session):
create table session_info( session_id string, guid string, trackerU string, landing_url string, landing_url_ref string, user_id string, pv string, stay_time string, min_trackTime string, ip string, provinceId string ) partitioned by (date string) row format delimited fields terminated by ‘\t‘ ;
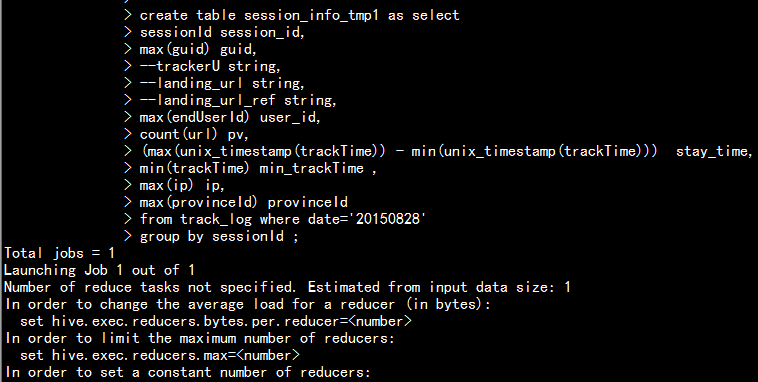
1.3 創建臨時表 session_info_tmp1
create table session_info_tmp1 as select sessionId session_id, max(guid) guid, --trackerU string, --landing_url string, --landing_url_ref string, max(endUserId) user_id, count(url) pv, (max(unix_timestamp(trackTime)) - min(unix_timestamp(trackTime))) stay_time, min(trackTime) min_trackTime , max(ip) ip, max(provinceId) provinceId from track_log where date=‘20150828‘ group by sessionId ;
1.4 創建臨時表session_info_tmp2
create table session_info_tmp2 as select
sessionId session_id,
trackTime trackTime,
trackeru trackerU,
url landing_url,
referer landing_url_ref
from track_log where date=‘20150828‘ ;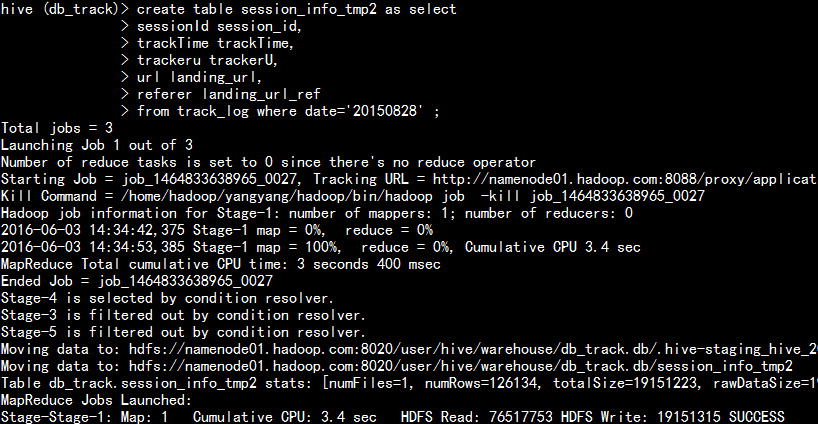
1.5 導入數據處理:
insert overwrite table session_info partition (date=‘20150828‘) select a.session_id, a.guid, b.trackerU, b.landing_url, b.landing_url_ref, a.user_id, a.pv, a.stay_time, a.min_trackTime, a.ip, a.provinceId from session_info_tmp1 a join session_info_tmp2 b on a.session_id=b.session_id and a.min_trackTime=b.trackTime ;
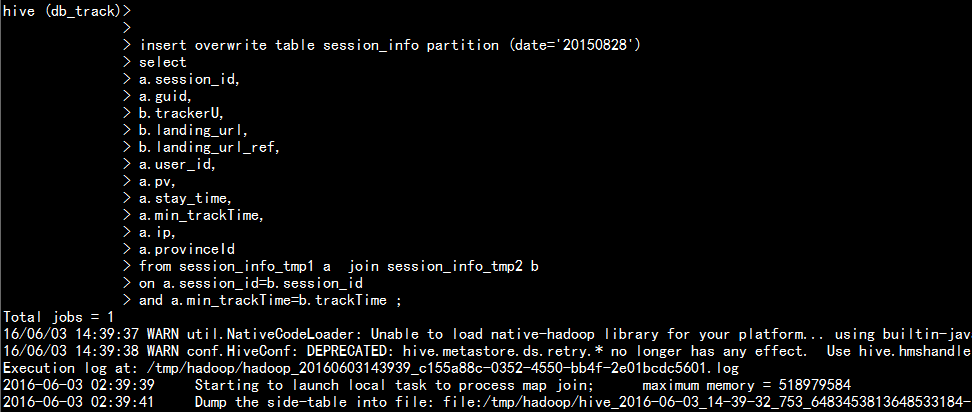
1.6 生成最後所需的表:
create table vistor_users_info as
select
date,
count(distinct guid) UV,
sum(pv) PV,
count(case when user_id != ‘‘ then user_id else null end) login_users,
count(case when user_id = ‘‘ then user_id else null end) vistor_users,
avg(stay_time) avg_stay_time,
count(case when pv>=2 then session_id else null end)/count(session_id) sec_ratio,
count(distinct ip) ip
from session_info where date=‘20150828‘
group by date ;
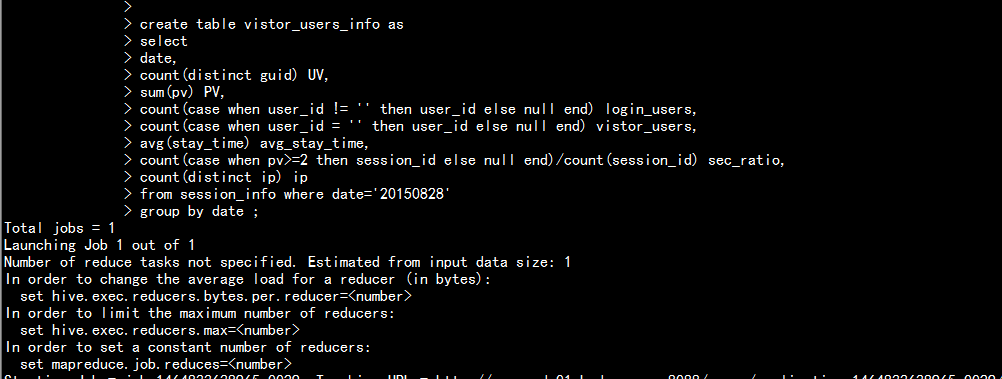
1.7 查詢結果:
select * from vistor_users_info;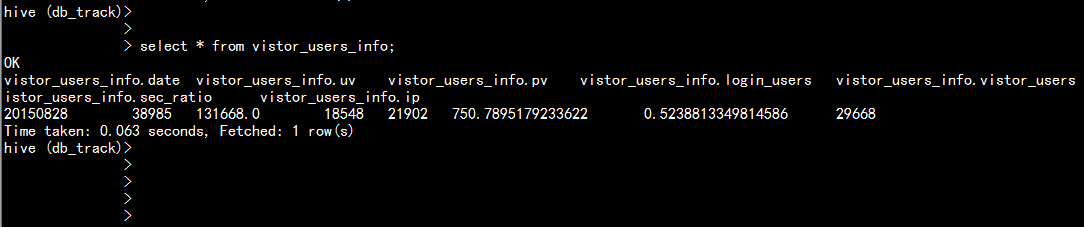
hive 的數據案例 統計網站的數據信息