
sqoop 的安裝與常用抽數操作
阿新 • • 發佈:2018-04-12
大數據 hadoop sqoop 抽取數據
- sqoop 簡介處理
- sqoop 環境配置處理
- sqoop 數據導入導出處理
一: sqoop 簡介處理
- 1. Sqoop是一個用來將Hadoop和關系型數據庫中的數據相互轉移的工具,可以將一個關系型數據庫(例如 : MySQL ,Oracle ,Postgres等)中的數據導進到Hadoop的HDFS中,也可以將HDFS的數據導進到關系型數據庫中。
- 2. Sqoop中一大亮點就是可以通過hadoop的mapreduce把數據從關系型數據庫中導入數據到HDFS,可以將hive 的數據,hdfs 上面的數據進行 提取的到關系型數據當中。 反之亦可操作。二:sqoop 安裝與配置處理:
環境需求: 安裝好的hadoop環境與hive 環境已經配置。2.1 配置單節點的zookeeper 環境
tar -zxvf zookeeper-3.4.5-cdh5.3.6.tar.gz
mv zookeeper-3.4.5-cdh5.3.6 yangyang/zookeeper
cd yangyang/zookeeper/conf
cp -p zoo_sample.cfg zoo.cfg2.2 給定zookeeper 的Datadir 目錄:
# the directory where the snapshot is stored. # do not use /tmp for storage, /tmp here is just # example sakes. #dataDir=/tmp/zookeeper <!--給定dataDir 目錄 --> dataDir=/home/hadoop/yangyang/zookeeper/data # the port at which the clients will connect
echo "1" > /home/hadoop/yangyang/zookeeper/myid2.3 啟動zookeeper服務
cd /home/hadoop/yangyang/zookeer/sbin/
./zkServer.sh start
tar -zxvf sqoop-1.4.5-cdh5.3.6.tar.gz mv sqoop-1.4.5-cdh5.3.6 yangyang/sqoop cp -p mysql-connector-java-5.1.27-bin.jar /home/hadoop/yangyang/sqoop/lib/ cd yangyang/sqoop/conf cp -p sqoop-env-template.sh sqoop-env.sh
2.4 配置sqoop環境
vim sqoop-env.sh
#Set path to where bin/hadoop is available
<!--配置hadoop目錄-->
export HADOOP_COMMON_HOME=/home/hadoop/yangyang/hadoop
#Set path to where hadoop-*-core.jar is available
<!--配置hadoop的mapreduce目錄-->
export HADOOP_MAPRED_HOME=/home/hadoop/yangyang/hadoop
<!--配置hbase 目錄>
#set the path to where bin/hbase is available
#export HBASE_HOME=
#Set the path to where bin/hive is available
<!--配置hive的目錄-->
export HIVE_HOME=/home/hadoop/yangyang/hive
<!--配置zookeeper 的目錄處理>
#Set the path for where zookeper config dir is
export ZOOCFGDIR=/home/hadoop/yangyang/zookeeper/conf二:sqoop 的環境測試處理
2.1 在mysql 的環境下創建數據庫,並創建表處理
mysql -uroot -p123456
create database yangyang;
use yangyang;
創建一個my_user表:
CREATE TABLE `my_user` (
`id` tinyint(4) NOT NULL AUTO_INCREMENT,
`account` varchar(255) DEFAULT NULL,
`passwd` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`)
);
插入數據:
INSERT INTO `my_user` VALUES (‘1‘, ‘admin‘, ‘admin‘);
INSERT INTO `my_user` VALUES (‘2‘, ‘pu‘, ‘12345‘);
INSERT INTO `my_user` VALUES (‘3‘, ‘system‘, ‘system‘);
INSERT INTO `my_user` VALUES (‘4‘, ‘zxh‘, ‘zxh‘);
INSERT INTO `my_user` VALUES (‘5‘, ‘test‘, ‘test‘);
INSERT INTO `my_user` VALUES (‘6‘, ‘pudong‘, ‘pudong‘);
INSERT INTO `my_user` VALUES (‘7‘, ‘qiqi‘, ‘qiqi‘);三: 將mysql的數據表導入到hdfs 上面:
3.1 sqoop 導入不指定目錄:
bin/sqoop import --connect jdbc:mysql://namenode01.hadoop.com:3306/yangyang --username root --password 123456 --table my_user
導出的路徑在hdfs 上面的目錄是
/usr/hadoop/my_user/
註意:
不指定導入目錄,默認情況是導入到hdfs上面用戶家目錄下面。
默認導入到HDFS裏面,分隔符是,3.2 導入帶目錄路徑:
bin/sqoop import --connect jdbc:mysql://namenode01.hadoop.com:3306/yangyang --username root --password 123456 --table my_user --target-dir /db_0521/ -m 1 --delete-target-dir --fields-terminated-by ‘\t‘ --direct 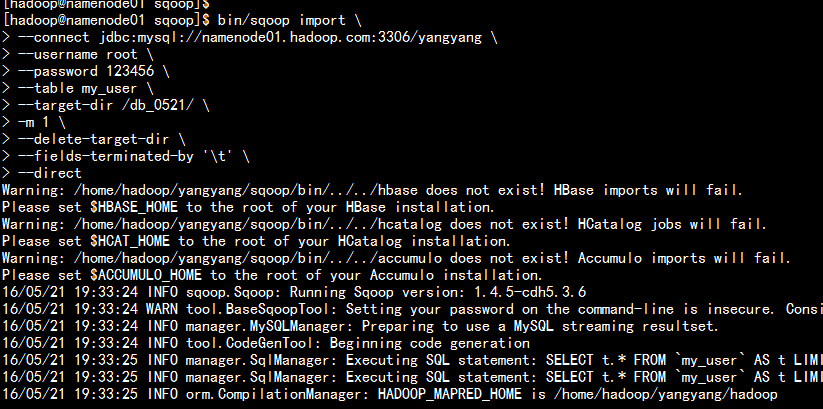
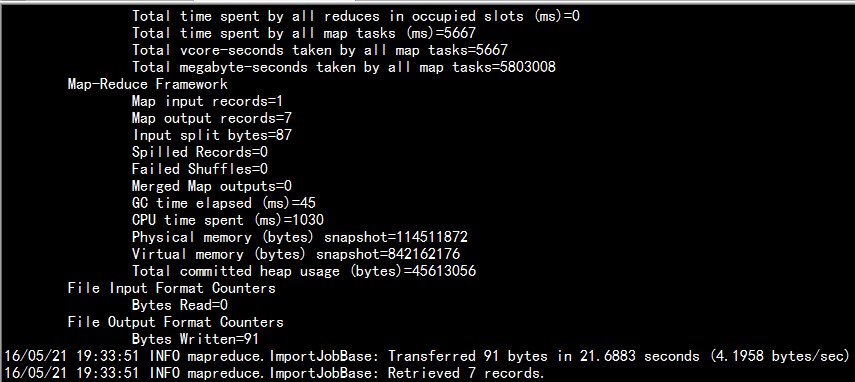
3.3 增量導入:
bin/sqoop import --connect jdbc:mysql://namenode01.hadoop.com:3306/yangyang --username root --password 123456 --table my_user --target-dir /db_0521/ -m 1 --fields-terminated-by ‘\t‘ --direct --check-column id --incremental append --last-value 4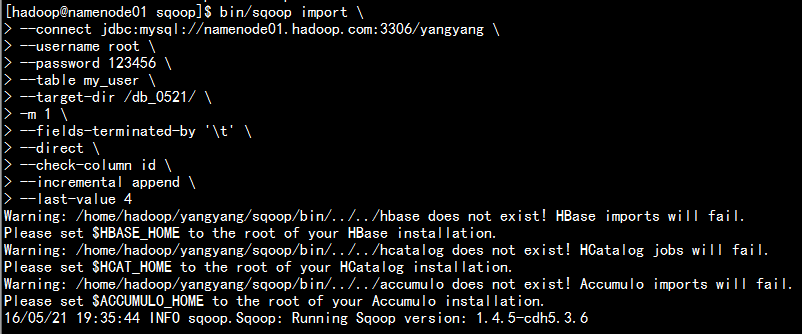

3.4 從mysql 導入hive 當中:
bin/sqoop import --connect jdbc:mysql://namenode01.hadoop.com:3306/yangyang --username root --password 123456 --table my_user --delete-target-dir --hive-import --hive-database yangyang --hive-table mysql2hive --fields-terminated-by ‘\t‘ 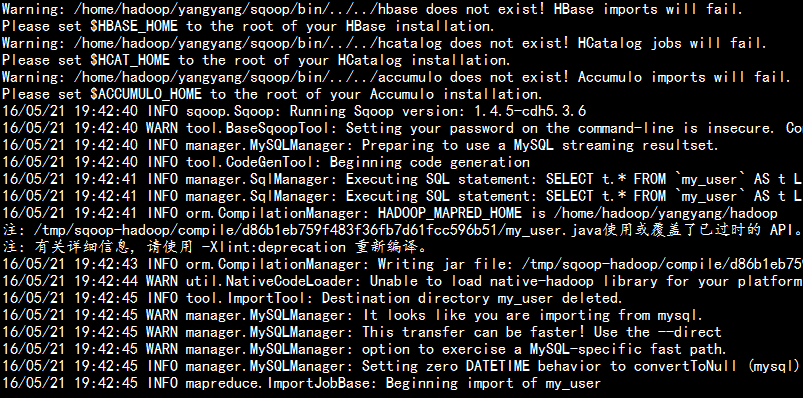
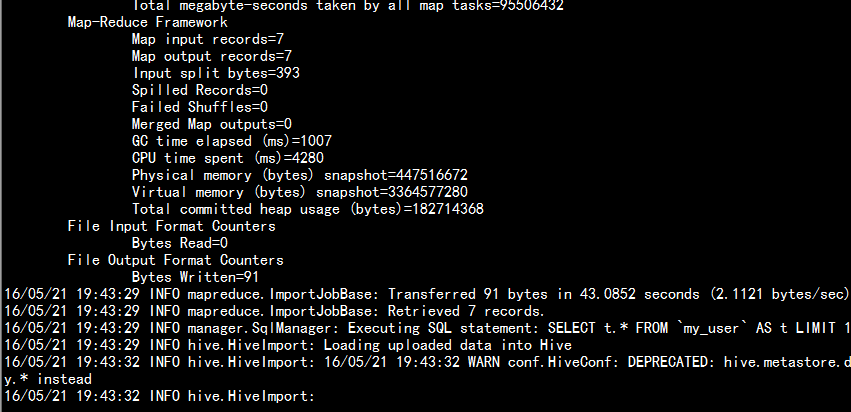
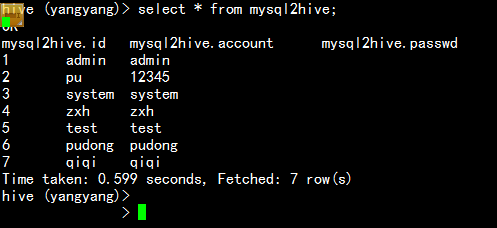
3.5 從hdfs 當中導出mysql 當中:
新建一張空表:
create table hdfs2mysql like my_user;
導出命令
bin/sqoop export --connect jdbc:mysql://namenode01.hadoop.com:3306/yangyang --username root --password 123456 --table hdfs2mysql --export-dir /user/hive/warehouse/yangyang.db/mysql2hive --input-fields-terminated-by ‘\t‘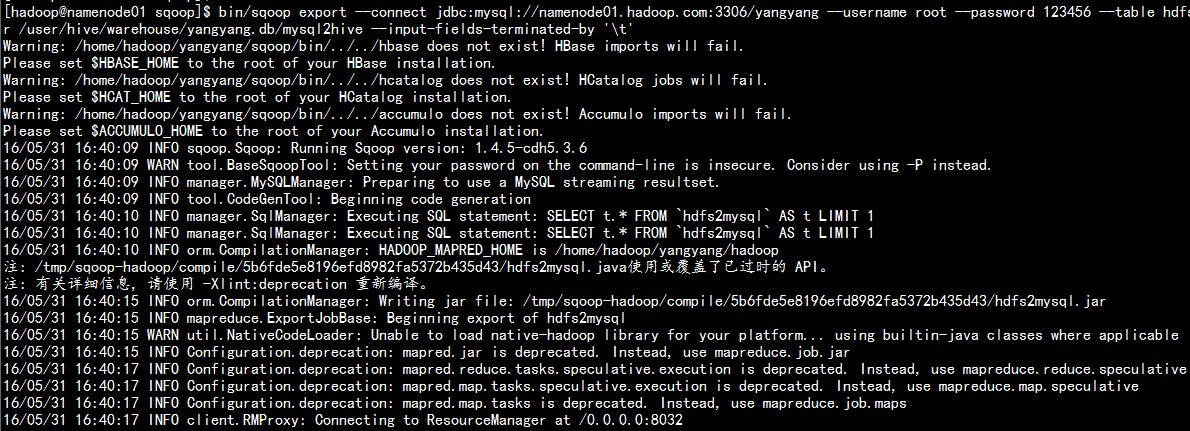
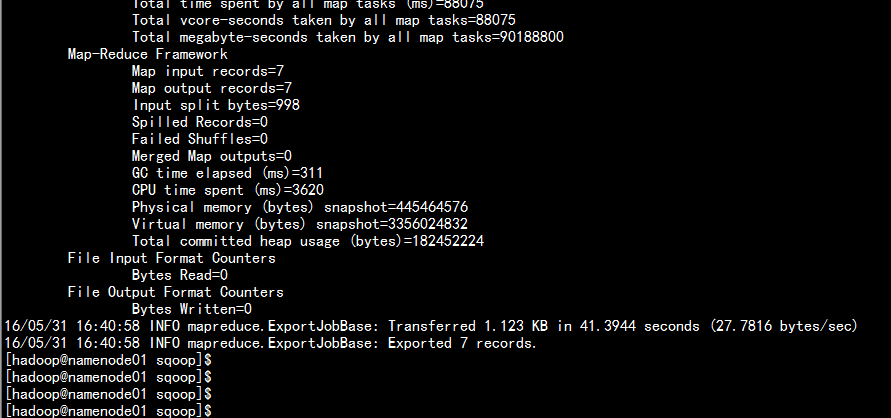
從hive 當中導出到mysql 當中:
註意:其實就是從HDFS導入到RDBMS新建一張空表:
create table hive2mysql like my_user;
導出命令:
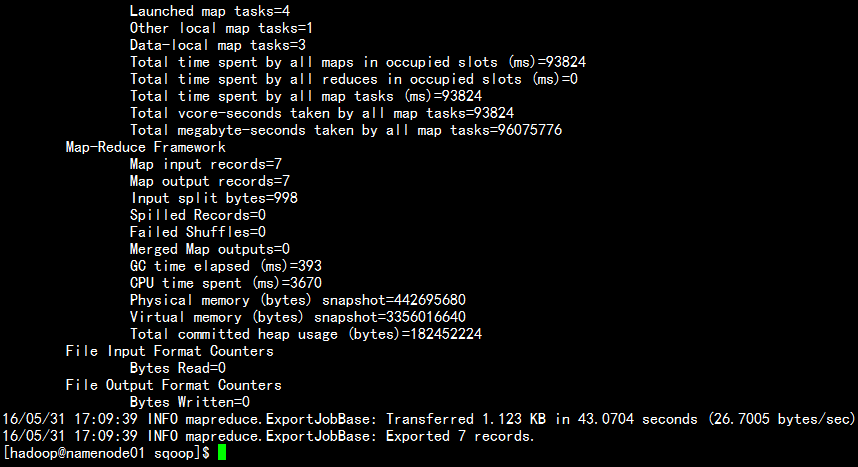
bin/sqoop export --connect jdbc:mysql://namenode01.hadoop.com:3306/yangyang --username root --password 123456 --table hive2mysql --export-dir /user/hive/warehouse/yangyang.db/mysql2hive --input-fields-terminated-by ‘\t‘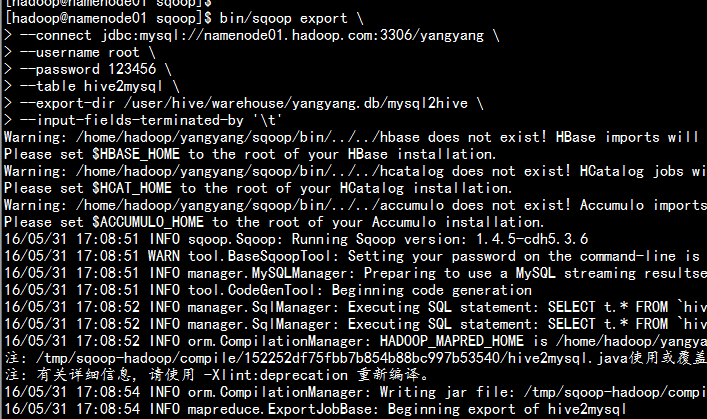
sqoop 的安裝與常用抽數操作