
InnoDB MVCC實現原理及源碼解析
數據多版本(MVCC)是MySQL實現高性能的一個主要的一個主要方式,通過對普通的SELECT不加鎖,直接利用MVCC讀取指版本的值,避免了對數據重復加鎖的過程。InnoDB支持MVCC多版本,其中RC和RR隔離級別是利用consistent read view方式支持的,即在某個時刻對事物系統打快照記下所有活躍讀寫事務ID,之後讀操作根據事務ID與快照中的事務ID進行比較,判斷可見性。
2、InnoDB數據行結構
行結構中,除了用戶定義的列外還有3個系統列:DATA_ROW_ID、DATA_TRX_ID、DATA_ROLL_PTR,如果表沒有定義主鍵那麽DATA_ROW_ID作為主鍵列,否則行結構中沒有DATA_ROW_ID列。其中:
DATA_TRX_ID:修改該行數據的事務的ID
DATA_ROLL_PTR:指向該行回滾段的指針。整個MVCC實現,關鍵靠這2個字段來完成。
3、READ-VIEW原理流程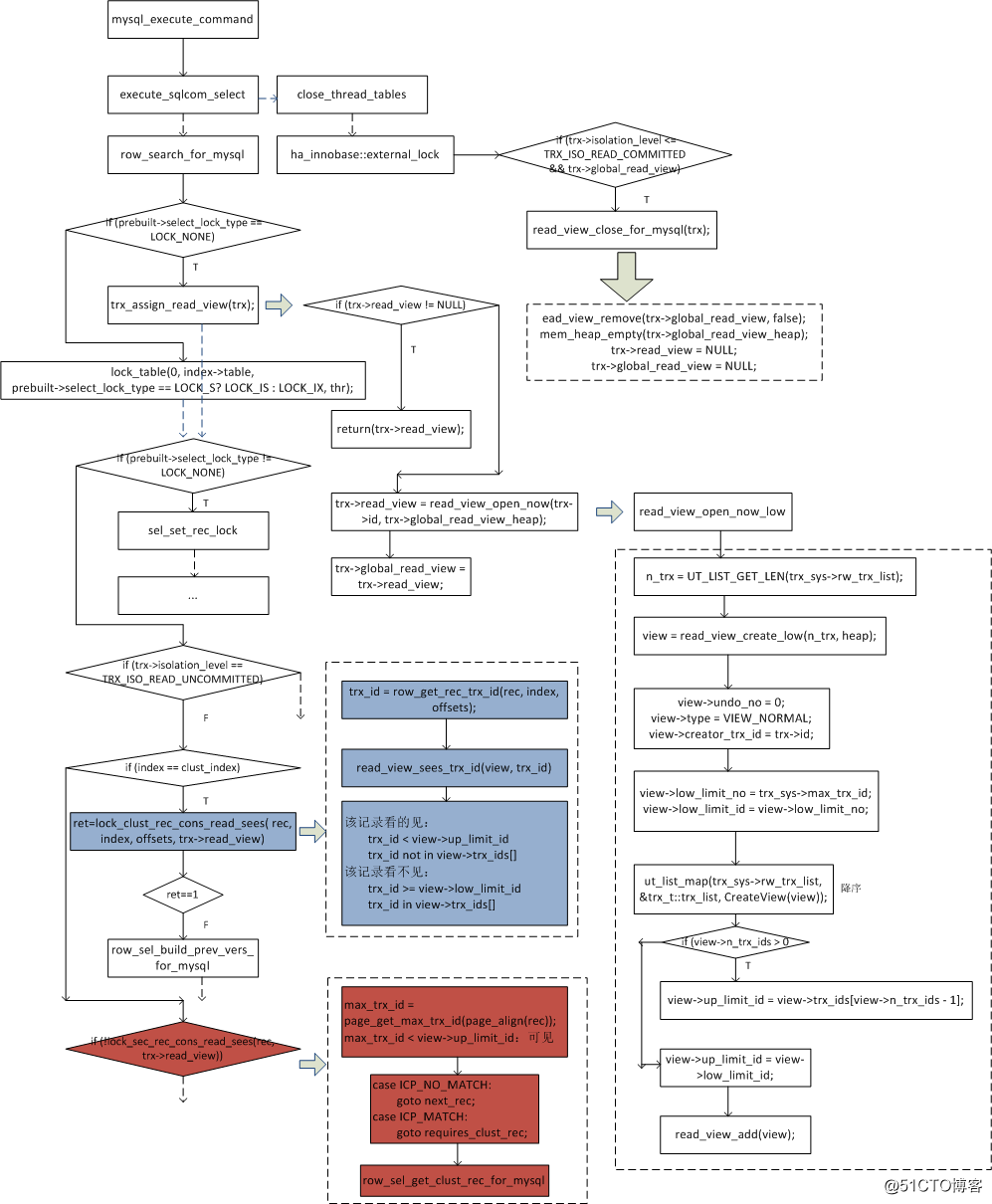
4、READ-VIEW解讀
1)read view是和SQL語句綁定的,在每個SQL語句執行前申請或獲取(RR隔離級別:事務第一個select申請,之後都用這個;RC隔離級別:每個select都會申請)
2)read view結構
struct read_view_t{ ulint type; /*!< VIEW_NORMAL, VIEW_HIGH_GRANULARITY */ undo_no_t undo_no;/*!< 0 or if type is VIEW_HIGH_GRANULARITY transaction undo_no when this high-granularity consistent read view was created */ trx_id_t low_limit_no; /*!< The view does not need to see the undo logs for transactions whose transaction number is strictly smaller (<) than this value: they can be removed in purge if not needed by other views */ trx_id_t low_limit_id; /*!< The read should not see any transaction with trx id >= this value. In other words, this is the "high water mark". */ trx_id_t up_limit_id; /*!< The read should see all trx ids which are strictly smaller (<) than this value. In other words, this is the "low water mark". */ ulint n_trx_ids; /*!< Number of cells in the trx_ids array */ trx_id_t* trx_ids;/*!< Additional trx ids which the read should not see: typically, these are the read-write active transactions at the time when the read is serialized, except the reading transaction itself; the trx ids in this array are in a descending order. These trx_ids should be between the "low" and "high" water marks, that is, up_limit_id and low_limit_id. */ trx_id_t creator_trx_id; /*!< trx id of creating transaction, or 0 used in purge */ UT_LIST_NODE_T(read_view_t) view_list; /*!< List of read views in trx_sys */ };
主要包括3個成員{low_limit_id,up_limit_id,trx_ids}。
low_limit_id:表示創建read view時,當前事務活躍讀寫鏈表最大的事務ID,即最近創建的除自身外最大的事務ID
up_limit_id:表示創建read view時,當前事務活躍讀寫鏈表最小的事務ID。
trx_ids:創建read view時,活躍事務鏈表裏所有事務ID3)對於小於等於RC的隔離級別,每次SQL語句結束後都會調用read_view_close_for_mysql將read view從事務中刪除,這樣在下一個SQL語句啟動時,會判斷trx->read_view為NULL,從而重新申請。對於RR隔離級別,則SQL語句結束後不會刪除read_view,從而下一個SQL語句時,使用上次申請的,這樣保證事務中的read view都一樣,從而實現可重復讀的隔離級別。
4)對於可見性判斷,分配聚集索引和二級索引。聚集索引:
記錄的DATA_TRX_ID < view->up_limit_id:在創建read view時,修改該記錄的事務已提交,該記錄可見DATA_TRX_ID >= view->low_limit_id:當前事務啟動後被修改,該記錄不可見
DATA_TRX_ID 位於(view->up_limit_id,view->low_limit_id):需要在活躍讀寫事務數組查找trx_id是否存在,如果存在,記錄對於當前read view是不可見的。
二級索引:
由於InnoDB的二級索引只保存page最後更新的trx_id,當利用二級索引進行查詢的時候,如果page的trx_id小於view->up_limit_id,可以直接判斷page的所有記錄對於當前view是可見的,否則需要回clustered索引進行判斷。5)如果記錄對於view不可見,需要通過記錄的DB_ROLL_PTR指針遍歷history list構造當前view可見版本數據
6)start transaction和begin語句執行後並沒有在innodb層分配事務ID、回滾段、read_view、將事務放到讀寫事務鏈表等,這個操作需要第一個SQL語句調用函數trx_start_low來完成,這個需要註意。
InnoDB MVCC實現原理及源碼解析