
Scala筆記整理(一):scala基本知識
Scala簡介
Scala是一門多範式(multi-paradigm)的編程語言,設計初衷是要集成面向對象編程和函數式編程的各種特性。
Scala運行在Java虛擬機上,並兼容現有的Java程序。
Scala源代碼被編譯成Java字節碼,所以它可以運行於JVM之上,並可以調用現有的Java類庫。
函數編程範式更適合用於Map/Reduce和大數據模型,它摒棄了數據與狀態的計算模型,著眼於函數本身,而非執行的過程的數據和狀態的處理。函數範式邏輯清晰、簡單,非常適合用於處理基於不變數據的批量處理工作,這些工作基本都是通過map和reduce操作轉換數據後,生成新的數據副本,然後再進行處理。
像Spark,Flink等都是采用Scala開發的,所以學習好大數據,掌握scala是必要的。
官網:http://scala-lang.org/
Scala安裝驗證
1、安裝JDK 2、JAVA_HOME, PATH 3、Maven 4、SCALA SDK 下載地址:http://scala-lang.org/download/all.html 這裏選擇的版本為Scala 2.10.5,分為windows和linux版本 5、配置SCALA_HOME 在windows環境變量中添加SCALA_HOME 6、驗證 scala -version Scala code runner version 2.10.5 -- Copyright 2002-2013, LAMP/EPFL
入門程序
object HelloWorld {
def main(args:Array[String]):Unit = {
println("Hello World!")
}
}保存為HelloWorld.scala,然後再執行下面兩步即可:
scalac HelloWorld.scala
scala HelloWorldScala基礎知識和語法
語言特點
1.可拓展 面向對象 函數式編程 2.兼容JAVA 類庫調用 互操作 3.語法簡潔 代碼行短 類型推斷 抽象控制 4.靜態類型化 可檢驗 安全重構 5.支持並發控制 強計算能力 自定義其他控制結構
Scala與Java的關系
-
1、都是基於JVM虛擬機運行的
Scala編譯之後的文件也是.class,都要轉換為字節碼,然後運行在JVM虛擬機之上。
-
2、Scala和Java相互調用
在Scala中可以直接調用Java的代碼,同時在Java中也可以直接調用Scala的代碼
-
3、Java8 VS Scala
1)Java8(lambda)沒有出來之前,Java只是面向對象的一門語言,但是Java8出來以後,Java就是一個面向對象和面向函數的混合語言了。
2)首先我們要對Scala進行精確定位,從某種程度上講,Scala並不是一個純粹的面向函數的編程語言,有人認為Scala是一個帶有閉包的靜態面向對象語言),更準確地說,Scala是面向函數與面向對象的混合。
3)Scala設計的初衷是面向函數FP,而Java起家是面向對象OO,現在兩者都是OO和FP的混合語言,是否可以這麽認為:Scala= FP + OO,而Java =OO + FP?
由於面向對象OO和面向函數FP兩種範式是類似橫坐標和縱坐標的兩者不同坐標方向的思考方式,類似數據庫和對象之間的不匹配阻抗關系,兩者如果結合得不好恐怕就不會產生1+1>2的效果。
面向對象是最接近人類思維的方式,而面向函數是最接近計算機的思維方式。如果你想讓計算機為人的業務建模服務,那麽以OO為主;如果你希望讓計算機能自己通過算法從大數據中自動建模,那麽以FP為主。所以,Java可能還會在企業工程類軟件中占主要市場,而Scala則會在科學計算大數據分析等領域搶占Java市場,比如Scala的Spark大有替代Java的Hadoop之趨勢。
Scala解釋器和IDEA
1、Scala解釋器讀到一個表達式,對它進行求值,將它打印出來,接著再繼續讀下一個表達式。這個過程被稱做讀取--求值--打印--循環,即:REPL。
從技術上講,scala程序並不是一個解釋器。實際發生的是,你輸入的內容被快速地編譯成字節碼,然後這段字節碼交由Java虛擬機執行。正因為如此,大多數scala程序員更傾向於將它稱做“REPL”
2、scala
scala>"Hello"
res1: String = Hello
scala> 1+2
res5: Int = 3
scala>"Hello".filter(line=>(line!=‘l‘))
res2: String = Heo你應該註意到了在我們輸入解釋器的每個語句後,它會輸出一行信息,類似res0:
java.lang.String
= Hello。輸出的第一部分是REPL給表達式起的變量名。在這幾個例子裏,REPL為每個表達式定義了一個新變量(res0到res3)。輸出的第二部分(:後面的部分)是表達式的靜態類型。第一個例子的類型是java.lang.String,最後一個例子的類型則是scala.util.matching.Regex。輸出的最後一部分是表達式求值後的結果的字符串化顯示。一般是對結果調用toString方法得到的輸出,JVM給所有的類都定義了toString方法。

var和val定義變量
1、Scala中沒有static的類,但是他有一種類似的伴生對象
2、字段:
字段/變量的定義Scala中使用 var/val 變量/不變量名稱 : 類型的方式進行定義,例如:
var index1 : Int = 1
val index2 : Int = 1 其中var與val的區別在於,var是變量,以後的值還可以改變,val的值只能在聲明的時候賦值,但是val不是常量,只能說是不變量或只讀變量。
3、大家肯定會覺得這種var/val名稱 : 類型的聲明方式太過於繁瑣了,有另外一種方式
所以你在聲明字段的時候,可以使用編譯器自動推斷類型,即不用寫: 類型,例如:
var index1 = 1 (類型推斷)
val index2 = 1 這個例子演示了被稱為類型推斷(type inference)的能力,它能讓scala自動理解你省略了的類型。這裏,你用int字面量初始化index1,因此scala推斷index2的類型是Int。對於可以由Scala解釋器(或編譯器)自動推斷類型的情況,就沒有必要非得寫出類型標註不可。
4、a.方法(b)
這裏的方法是一個帶有2個參數的方法(一個顯示的和一個隱式的)
1.to(10), 1 to 10, 1 until 10
scala> 1.to(10)
res19: scala.collection.immutable.Range.Inclusive = Range(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
scala> 1 to 10
res20: scala.collection.immutable.Range.Inclusive = Range(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
scala> 1 until 10
res21: scala.collection.immutable.Range = Range(1, 2, 3, 4, 5, 6, 7, 8, 9)5、其實根據函數式編程思想中,var變量是個不好的存在,Scala中推薦大家盡可能的采用val的不變量,主要原因是
- 1)、val的不可變有助於理清頭緒,但是相對的會付出一部分的性能代價。
- 2)、另外一點就是如果使用var,可能會擔心值被錯誤的更改。
- 3)、使用val而不是var的第二點好處是他能更好地支持等效推論(a=b,b=c —> a=c)
數據類型和操作符
? scala擁有和java一樣的數據類型,和java的數據類型的內存布局完全一致,精度也完全一致。
下面表格中是scala支持的數據類型:
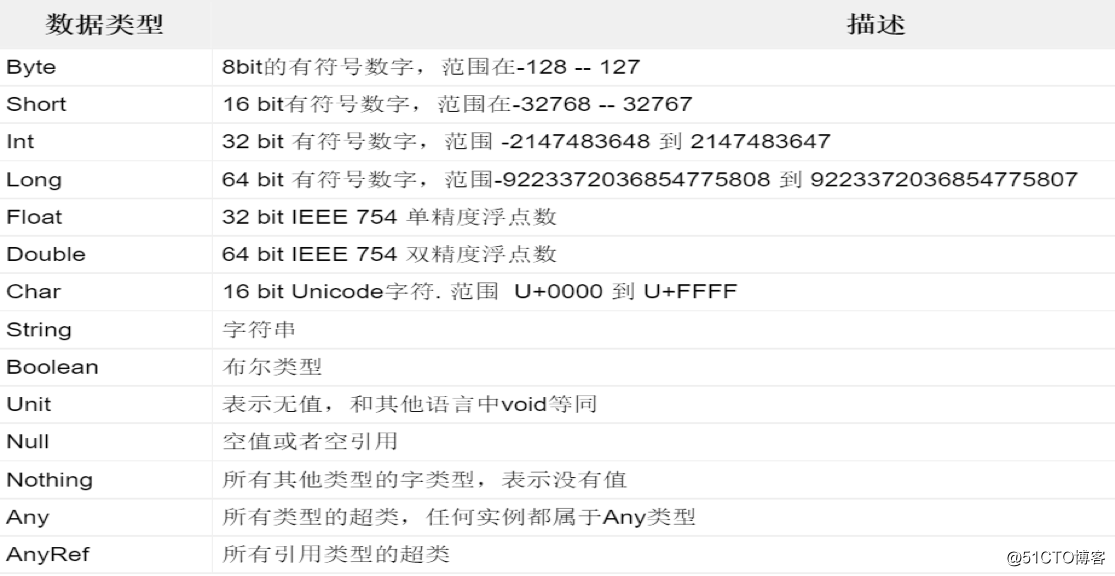
上表中列出的數據類型都是對象,也就是說scala沒有java中的原生類型。也就是說scala沒有基本數據類型與包裝類型的概念。
Scala裏,你可以舍棄方法調用的空括號。例外就是如果方法帶有副作用就加上括號,如println(),不過如果方法沒有副作用就可以去掉括號,如String上調用的toLowerCase:
scala> "Hello".toLowerCase
res22: String = hello
scala> "Hello".toLowerCase()
res23: String = hello數學運算
Scala裏,你可以舍棄方法調用的空括號。例外就是如果方法帶有副作用就加上括號,如println(),不過如果方法沒有副作用就可以去掉括號,如String上調用的toLowerCase:
你可以通過中綴操作符,加號(+),減號(-),乘號(*),除號(/)和余數(%),在任何數類型上調用數學方法, scala中的基礎運算與java一致
scala> 1.2 + 2.3?
res6: Double = 3.5?
scala> 3 - 1?
res7: Int = 2?
scala> ‘b‘ - ‘a‘?
res8: Int = 1?
scala> 2L * 3L?
res9: Long = 6?
scala> 11 / 4?
res10: Int = 2?
scala> 11 % 4?
res11: Int = 3?
scala> 11.0f / 4.0f?
res12: Float = 2.75?
scala> 11.0 % 4.0?
res13: Double = 3.0關系和邏輯操作
你可以用關系方法:大於(>),小於(<),大於等於(>=)和小於等於(<=)比較數類型,像等號操作符那樣,產生一個Boolean結果。另外,你可以使用一元操作符!(unary_!方法)改變Boolean值
scala> 1 > 2
res16: Boolean = false
scala> 1 < 2
res17: Boolean = true
scala> 1.0 <= 1.0
res18: Boolean = true
scala> 3.5f >= 3.6f
res19: Boolean = false
scala> ‘a‘ >= ‘A‘
res20: Boolean = true
scala> val thisIsBoring = !true
thisIsBoring: Boolean = false
scala> !thisIsBoring
res21: Boolean = true對象相等性
scala> ("he" + "llo") == "hello"
res33: Boolean = true
=== 比較2個不同的對象
scala> 1 == 1.0
res34: Boolean = true 其比較的是值,而不是Java概念中的地址值。另外第二個例子,1 == 1.0,會為true,是因為1會做類型的提升變為1.0
Scala控制結構
If表達式有值
1、Scala的if/else語法結構和Java或者C++一樣,不過,在Scala中if/else表達式有值,這個值就是跟在if或else之後的表達式的值
val x = 3
if(x > 0) 1 else -1上述表達式的值是1或-1,具體是哪一個取決於x的值,同時你也可以將if/else表達式的值復制給變量
val s = if(x>0) 1 else -1 // 這與如下語句的效果是一樣的
if(x >0) s = 1 else s =-1不過,第一種寫法更好,因為它可以用來初始化一個val,而在第二種寫法當中,s必須是var
2、val result = if(personAge > 18) "Adult" else 0
其中一個分支是java.lang.string,另外一個類型是Int, 所以他們的公共超類是Any
3、如果else丟失了
if(x>0) 1那麽有可能if語句沒有輸出值,但是在Scala中,每個表達式都有值,這個問題的解決方案是引入一個Unit類,寫作(),不帶else語句的if語句等同於if(x>0) 1else ()
語句終止
1、在Java和C++中,每個語句都已分號結束。但是在Scala中—與JavaScript和其它語言類似—行尾的位置不需要分號。同樣,在}、else以及類似的位置也不需要寫分號。
不過,如果你想在單行中寫下多個語句,就需要將他們以分號隔開
If(n>0){r = r *n ; n-=1}我們需要用分號將r = r *n 和n -=1隔開,由於有},在第二個語句之後並不需要寫分號。
2、分行顯示
If(n>0){
r = r *n
n-=1
}快表達式和賦值
- 在Java或C++中,快語句是一個包含於}中的語句序列。每當需要在邏輯分支或喜歡執行多個動作時,你都可以使用快語句。
- 在Scala中,{}快包含一些列表達式,其結果也是一個表達式。塊中最後一個表達式式的值就是快的值。
scala> val n = 9
n: Int = 9
scala> var f = 0
f: Int = 0
scala> var m = 5
m: Int = 5
scala> val d = if(n < 18){f = f + n ; m = m + n ; f + m}
d: AnyVal = 23輸入和輸出
如果要打印一個值,我們用print或println函數。後者在打印完內容後會追加一個換行符。舉例來說,
print("Answer:")
println(42)與下面的代碼輸出的內容相同:
println("Answer:" + 42)另外,還有一個帶有C風格格式化字符串的printf函數:system.in
printf("Hello,%s! You are %d years old.\n", "Fred", 42)你可以用readLine函數從控制臺讀取一行輸入。如果要讀取數字、Boolean或者是字符,可以用readInt、readDouble、readByte、readShort、readLong、readFloat、readBoolean或者readChar。與其他方法不同,readLine帶一個參數作為提示字符串:
scala> val name = readLine("Please input your name:")
Please input your name:name: String = xpleaf一個簡單的輸入輸出案例如下:
val name = readLine("What‘s Your name: ")
print("Your age: ")
val age = readInt()
if(age > 18) {
printf("Hello, %s! Next year, your will be %d.\n", name, age + 1)
}else{
printf("Hello, %s! You are still a children your will be %d.\n", name, age + 1 +" Come up!!!")
}
}循環之while
Scala擁有與Java和C++相同的while和do循環。例如:
object _04LoopDemo {
def main(args: Array[String]):Unit = {
var sum = 0
var i = 1
while(i < 11) {
sum += i
i += 1
}
}
}循環之do while
Scala 也有do-while循環,它和while循環類似,只是檢查條件是否滿足在循環體執行之後檢查。例如:
object _04LoopDemo {
def main(args: Array[String]):Unit = {
var sum = 0
var i = 1
do {
sum += i
i += 1
} while(i <= 10)
println("1+...+10=" + sum)
}
}登錄用戶名密碼的遊戲:三次機會,從控制臺輸入輸入用戶名密碼,如果成功登錄,返回登錄成功,失敗,則反饋錯誤信息!如下:
object _05LoopTest {
def main(args: Array[String]):Unit = {
val dbUser = "zhangyl"
val dbPassword = "uplooking"
var count = 3
while(count > 0) {
val name = readLine("親,請輸入用戶名:")
val pwd = readLine("請輸入密碼:")
if(name == dbUser && pwd == dbPassword) {
println("登陸成功,正在為您跳轉到主頁吶," + name + "^_^")
// count = 0
return
} else {
count -= 1
println("連用戶名和密碼都記不住,你一天到底在弄啥嘞!您還有<" + count + ">次機會")
}
}
}
}循環之for
Scala沒有與for(初始化變量;檢查變量是否滿足某條件;更新變量)循環直接對應的結構。如果你需要這樣的循環,有兩個選擇:一是使用while循環,二是使用如下for語句:
for (i <- 表達式)讓變量i遍歷< -右邊的表達式的所有值。至於這個遍歷具體如何執行,則取決於表達式的類型。對於Scala集合比如Range而言,這個循環會讓i依次取得區間中的每個值。
遍歷字符串或數組時,你通常需要使用從0到n-1的區間。這個時候你可以用until方法而不是to方法。util方法返回一個並不包含上限的區間。
val s = "Hello"
var sum = 0
for (i <- 0 until s.length) { // i的最後一個取值是s.length - 1
sum += s(i) // 註意此時為對應的ASCII值相加
} 在本例中,事實上我們並不需要使用下標。你可以直接遍歷對應的字符序列:
var sum = 0
for (ch <- "Hello") sum += ch循環之跳出循環
說明:Scala並沒有提供break或continue語句來退出循環。那麽如果需要break時我們該怎麽做呢?有如下幾個選項:
-
- 使用Boolean型的控制變量。
-
- 使用嵌套函數——你可以從函數當中return。
-
- 使用Breaks對象中的break方法:
object _06LoopBreakTest {
def main(args: Array[String]):Unit = {
import scala.util.control.Breaks._
var n = 15
breakable {
for(c <- "Spark Scala Storm") {
if(n == 10) {
println()
break
} else {
print(c)
}
n -= 1
}
}
}
}循環之for高級特性
1、除了for循環的基本形態之外,Scala也提供了其它豐富的高級特性。比如可以在for循環括號裏同時包含多組變量 <- 表達式 結構,組之間用分號分隔
for (i <- 1 to 3;j <- 1 to 3) print ((10 * i +j) + " ")for循環的這種結構類似Java中的嵌套循環結構。
例如要實現一個九九乘法表,使用基本的for循環形態時,代碼如下:
object _07LoopForTest {
def main(args: Array[String]):Unit = {
for(i <- 1 to 9) {
for(j <- 1 to i){
var ret = i * j
print(s"$i*$j=$ret\t")
}
// println()
System.out.println()
}
}
}而使用高級for循環時,如下:
object _07LoopForTest {
def main(args: Array[String]):Unit = {
// for(i <- 1 to 9; j <- 1 to 9 if j <= i) {
for(i <- 1 to 9; j <- 1 to i) {
var ret = i * j
print(s"$i*$j=$ret\t")
if(i == j) {
println
}
}
}
}2、if循環守衛
可以為嵌套循環通過if表達式添加條件:
for (i <- 1 to 3; j <- 1 to 3 if i != j) print ((10 * i + j) + " ")if表達式是否添加括號,結果無變化:
for (i <- 1 to 3; j <- 1 to 3 if (i != j)) print ((10 * i + j) + " ")註意:註意在if之前並沒有分號。
3、For推導式
Scala中的yield不像Ruby裏的yield,Ruby裏的yield象是個占位符。Scala中的yield的主要作用是記住每次叠代中的有關值,並逐一存入到一個數組中。用法如下:
for {子句} yield {變量或表達式}1)如果for循環的循環體以yield開始,則該循環會構造出一個集合,每次叠代生成集中的一個值:
scala> for(i <- 1 to 10) yield println(i % 3)
1
2
0
1
2
0
1
2
0
1
res47: scala.collection.immutable.IndexedSeq[Unit] = Vector((), (), (), (), (), (), (), (), (), ())
scala> val ret1 = for(i <- 1 to 10) yield(i)
ret1: scala.collection.immutable.IndexedSeq[Int] = Vector(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
scala> for(i <- ret1) println(i)
1
2
3
4
5
6
7
8
9
102) for 循環中的 yield 會把當前的元素記下來,保存在集合中,循環結束後將返回該集合
Scala中for循環是有返回值的。如果被循環的是Map,返回的就是Map,被循環的是List,返回的就是List,以此類推。
yield關鍵字的簡短總結:
1.針對每一次for循環的叠代, yield會產生一個值,被循環記錄下來(內部實現上,像是一個緩沖區)
2.當循環結束後, 會返回所有yield的值組成的集合
3.返回集合的類型與被遍歷的集合類型是一致的異常處理
Scala的異常處理和其它語言比如Java類似,一個方法可以通過拋出異常的方法而不返回值的方式終止相關代碼的運行。調用函數可以捕獲這個異常作出相應的處理或者直接退出,在這種情況下,異常會傳遞給調用函數的調用者,依次向上傳遞,直到有方法處理這個異常。
object _01ExceptionDemo {
def main(args:Array[String]):Unit = {
import scala.io.Source
import java.io.FileNotFoundException
try {
val line = Source.fromFile("./wordcount.txt").mkString
val ret = 1 / 0
println(line)
} catch {
case fNFE:FileNotFoundException => {
println("FileNotFoundException:文件找不到了,傳的路徑有誤。。。")
}
case e:Exception => {
println("Exception: " + e.getMessage)
}
case _ => println("default處理方式")
} finally {
println("this is 必須要執行的語句")
}
}
}Scala函數
函數的定義與調用(類成員函數)
Scala除了方法外還支持函數。方法對對象進行操作,函數不是。要定義函數,你需要給出函數的名稱、參數和函數體,就像這樣:
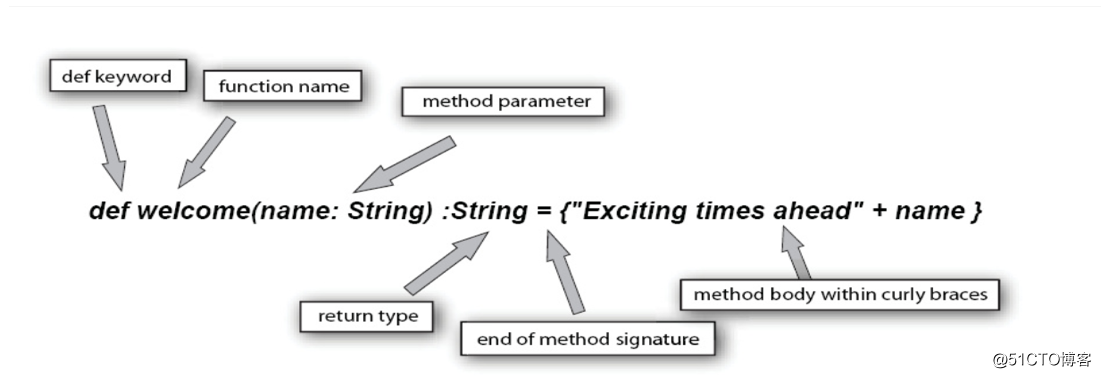
下面是需要註意的問題:
- 1、你必須給出所有參數的類型。不過,只要函數不是遞歸的,你就不需要指定返回類型。Scala編譯器可以通過=符號右側的表達式的類型推斷出返回類型。
- 2、“=”並不只是用來分割函數簽名和函數體的,它的另一個作用是告訴編譯器是否對函數的返回值進行類型推斷!如果省去=,則認為函數是沒有返回值的!
def myFirstFunction(name:String, age:Int) : String ={
println("name=> " + name +"\t age=> " + age)
"Welcome " + name + " to our world, your age is => " + age
}在本例中我們並不需要用到return。我們也可以像Java或C++那樣使用return,來立即從某個函數中退出,不過在Scala中這種做法並不常見。
提示:雖然在帶名函數中使用return並沒有什麽不對(除了浪費7次按鍵動作外),我們最好適應沒有return的日子。很快,你就會使用大量匿名函數,這些函數中return並不返回值給調用者。它跳出到包含它的帶名函數中。我們可以把return當做是函數版的break語句,僅在需要時使用。
無返回值的函數
def myFirstFunctionWithoutFeedBackValues: Unit ={
println("This is our first function without feedback values")
}單行函數
def printMsg(name:String) = println("Hello, " + name +", welcome happy day!!!")上面所對應函數的案例如下:
/**
註意:
1.scala中如果要給一個函數做返回值,可以不用return語句,
使用也是可以的,但是scala語言強烈建議大家不要用
因為scala崇尚的是簡約而不簡單
一般也就是將這個return當做break來使用
2.在scala中在同一條語句中,變量名不能和引用函數名重復
3.使用遞歸時,需要指定返回值類型
*/
object _02FunctionDemo {
def main(args:Array[String]):Unit = {
// val ret = myFirstFunc("xpleaf", 23)
// println(ret)
// show("xpleaf", 23)
// val ret = singleLineFunc("xpleaf")
// println(ret)
val ret = factorial(5)
println(ret)
}
def testFunc(num:Int) = {
if(num == 1) {
1
}
10
}
// 使用遞歸來求解5的階乘
def factorial(num:Int):Int = {
if(num == 1) {
1
} else {
num * factorial(num - 1)
}
// 如果num * factorial(num - 1)不寫在else裏面,則需要return,否則會有異常,
// testFunc中則不會這樣,所以猜測遞歸函數才會有此問題
}
// 單行函數
def singleLineFunc(name:String) = "hello, " + name // 有"="號,有返回值,自動判斷返回值類型
// def singleLineFunc(name:String) {"hello, " + name} // 沒有“=”號,沒有返回值
// def singleLineFunc(name:String):Unit = "hello, " + name // 有"="號,但指定返回值為空,相當於沒有返回值
// def singleLineFunc(name:String) = println("hello, " + name) // 沒有返回值,println並不是一個表達式
// 沒有返回值的函數
def show(name:String, age:Int):Unit = {
println(s"My name is $name, and I‘m $age years old.")
}
// 有返回值的函數
def myFirstFunc(name:String, age:Int):String = {
println(s"My name is $name, and I‘m $age years old.")
// return "Welcome you " + name + ", make yourself..."
"Welcome you " + name + ", make yourself..."
}
}默認參數和帶名參數
1、我們在調用某些函數時並不顯式地給出所有參數值,對於這些函數我們可以使用默認參數。
def sayDefaultFunc(name: String, address: String = "Beijing", tellphone: String ="139****") ={
println(name +"address=> " + address +"\t tellphone=> " + tellphone)
}2、不指定具體參數時:給出默認值
sayDefaultFunc("Garry")3、如果相對參數的數量,你給出的值不夠,默認參數會從後往前逐個應用進來。
sayDefaultFunc("Garry","Shanhai")4、給出全部的參數值
sayDefaultFunc("Garry","Shanhai","13709872335")5、帶名參數可以讓函數更加可讀。它們對於那些有很多默認參數的函數來說也很有用。
sayDefaultFunc(address ="上海", tellphone="12109876543",name="Tom")6、你可以混用未命名參數和帶名參數,只要那些未命名的參數是排在前面的即可:
sayDefaultFunc("Tom",tellphone="12109876543",address= "上海")可變參數(一)
前面我們介紹的函數的參數是固定的,本篇介紹Scala函數支持的可變參數列表,命名參數和參數缺省值定義。
重復參數
Scala在定義函數時允許指定最後一個參數可以重復(變長參數),從而允許函數調用者使用變長參數列表來調用該函數,Scala中使用“*”來指明該參數為重復參數。例如
Scala:
def echo(args: String*) = {
for (arg <- args) println(arg)
}Java:
public staticvoid echo(String ...args){
for(String str: args){
System.out.println(str)
}
}可變參數(二)
1、在函數內部,變長參數的類型,實際為一數組,比如上例的String* 類型實際為 Array[String]。
然而,如今你試圖直接傳入一個數組類型的參數給這個參數,編譯器會報錯:
val arr= Array("Spark","Scala","AKKA")
Error message as bellows:
error: type mismatch;2、為了避免這種情況,你可以通過在變量後面添加_*來解決,這個符號告訴Scala編譯器在傳遞參數時逐個傳入數組的每個元素,而不是數組整體
val arr= Array("Spark","Scala","AKKA")
echo(arr:_*)一個例子如下:
object _04FunctionDemo {
def main(args:Array[String]):Unit = {
show("Spark", "Strom", "Hadoop")
var arr = Array("Spark", "Strom", "Hadoop")
show(arr:_*)
}
def show(strs:String*) {
for(str <- strs) {
println(str)
}
}
}過程
1、Scala對於不返回值的函數有特殊的表示法。如果函數體包含在花括號當中但沒有前面的=號,那麽返回類型就是Unit。這樣的函數被稱做過程(procedure)。過程不返回值,我們調用它僅僅是為了它的副作用。
案例:
如:我們需要打印一些圖案,那麽可以定義一個過程:
def draw(str:String) {
println("-------")
println("|"+" "+"|")
println("|"+ str +"|")
println("|"+" "+"|")
println("-------")
}2、我們也可以顯示指定的函數的返回值:Unit
Scala Lazy特性
1、當val被聲明為lazy時,它的初始化將被推遲,直到我們首次對它取值。例如,
lazy val lines= scala.io.Source.fromFile("D:/test/scala/wordcount.txt").mkString2、如果程序從不訪問lines ,那麽文件也不會被打開。但故意拼錯文件名。在初始化語句被執行的時候並不會報錯。不過,一旦你訪問words,就將會得到一個錯誤提示:文件未找到。
3、懶值對於開銷較大的初始化語句而言十分有用。它們還可以應對其他初始化問題,比如循環依賴。更重要的是,它們是開發懶數據結構的基礎。(spark 底層嚴重依賴這些lazy)
4、加載(使用它的時候才會被加載)
println(lines)一個例子如下:
object _05LazyDemo {
def main(args:Array[String]):Unit = {
import scala.io.Source
import java.io.FileNotFoundException
try {
lazy val line = Source.fromFile("./wordcountq.txt").mkString // wordcountq.txt這個文件並不存在
// println(line)
} catch {
case fNFE:FileNotFoundException => {
println("FileNotFoundException:文件找不到了,傳的路徑有誤。。。")
}
case e:Exception => {
println("Exception: " + e.getMessage)
}
} finally {
println("this is 必須要執行的語句")
}
}
}Scala筆記整理(一):scala基本知識