
DT時代下[個推3.0]遵循的四個法則
1.數據是決策的基本依據
數億客戶端情況下,如何迅速定位?譬如:有的手機定位正常,有的不正常;有的區域定位正常,有的不正常;有的版本定位正常,有的不正常。
而個推的解決方案是,首先是進行意識培養,第二是數據抽樣收集以及集中分析。個推前端團隊做了一個叫Logful的開源產品,通過抽樣的方法,解決定位問題,同時能極大地降低成本。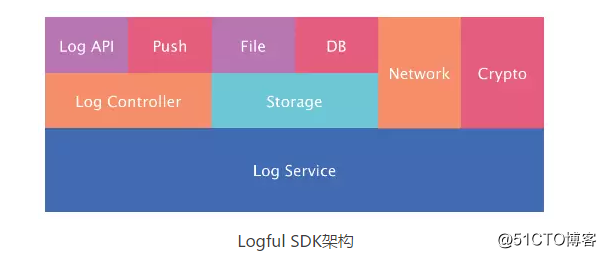
2.數據越熱越有價值
數據劃分為冷數據、溫數據、熱數據三種類別。冷數據是較長時間之前的狀態數據,即用戶畫像數據;溫數據則是非即時的狀態和行為數據;而熱數據是指即時的位置狀態、交易和瀏覽行為。
個推應景推送能夠精準捕捉場景,在合適的地點觸發消息,其本質是利用冷數據加上熱數據進行實時處理。且個推采用服務端處理的方案,在保證一定可接受的數據量的基礎上,很多業務在服務端處理,能把熱數據進行非常及時的加工,從而高效充分地把熱數據的價值利用起來。
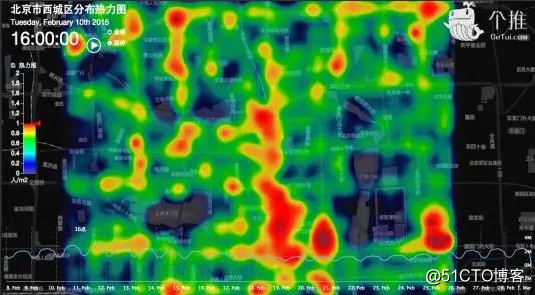
上圖是春節期間北京西城區的人口熱力圖,地圖上的色塊用於表現該地區的擁擠程度以及人群分布情況,顏色上,紅色代表人數密集,橙色次之,藍色則為稀疏,這是個推對熱數據的應用。
3.近似優於精確
考慮以下場景:你需要統計數據流中獨立元素的個數? 要求:實時,至少是準實時。但是你面臨幾個問題:1、數據流速度很快,意味著無法使用二級存儲。2、數據規模巨大意味著要麽使用超大內存的設備, 要麽多個設備分而治之運算,但多大算是個頭?
一般數據量大了以後會經常碰見這些問題。如果想得到精確解,代價是非常高昂的,所以能夠得到一個問題的近似解則是最優的解決方案。
4.永遠的墨菲定律
如果有兩種或者兩種以上的方法去做某件事情,其中一種選擇方式將導致災難,必定有人會做出這種選擇。通俗來說就是如果事情有變壞的可能,不管這種可能性有多小,它總會發生。
個推內部用了很多Redis的產品,特別是Redis 2.8 earlier 版本在網絡閃斷情況下會遇到很多問題。如果數據量小可能不會造成嚴重影響,但如果是幾十G甚至接近上百G的數據,而且復制過程中又有很多請求訪問Redis時,幾毫秒會變成幾百毫秒、幾秒。特別是需要實時處理的時候,流量並不一定會按照預期到來,還有攻擊、域名劫持、設備斷電等問題,這些都是非常棘手的。
一款APP剛上線,如果該APP很受歡迎,它的流量完全是不規則的,所以不能完全按照預期來設定流量大小。而需要做各個環節的流量控制。個推工程師在很多時候對於很多流量控制、異常的處理都會放在優先級的環境下,提前做這樣的需求,強制檢查。
產品設計階段,從技術角度來講,一定要有對異常情況的分析,所有代碼裏是否有異常的cache?有沒有考慮到斷網時長?出現這些問題怎麽解決?不要真的等問題出現的時候才想解決方案,而是需要事先進行模擬演練。可以梳理從最開始網絡流量進來到交換機、路由器,以及最終的系統等一系列過程,看看哪個環節可能存在異常。有很多問題,當應用規模不是很大的時候,影響也不會很大,但當應用規模大到一定程度,則會是特別嚴重的問題。所以異常情況分析 + 預案設定 + 沙盤推演 + 模擬操作是很有必要的。
以上內容來自個推CTO葉新江在ArchSummit全球架構師峰會北京站,基礎架構之技術演進專場的分享整理,希望能帶給廣大創業者一些啟發。
DT時代下[個推3.0]遵循的四個法則