
Python第六周 學習筆記(1)
打開操作
- io.open(file, mode=‘r‘, buffering=-1, encoding=None,errors=None, newline=None, closefd=True, opener=None)
-
返回一個文件對象(流對象)和文件描述符。打開文件失敗,則返回異常
- 基本使用:
f = open("test") print(f.read()) f.close() -
使用完一定要關閉
- 文件訪問模式分兩種:
文本模式和二進制模式
open的參數
file
- 打開或者要創建的文件名。如果不指定路徑,默認是當前路徑
mode模式
| 參數 | 描述 |
|---|---|
| r | 缺省的,表示只讀打開,如果調用write,會拋異常。如果文件不存在,拋出FileNotFoundError異常 |
| w | 只寫打開,如果文件不存在,則直接創建文件,如果文件存在,則清空文件內容 |
| x | 創建並寫入一個新文件,如果文件存在,拋出FileExistsError異常 |
| a | 寫入打開,如果文件存在,則追加 |
| b | 二進制模式,與字符編碼無關,字節操作使用bytes類型 |
| t | 缺省的,文本模式,將文件的字節按照某種字符編碼理解,按照字符操作 |
| + | 讀寫打開一個文件。給原來只讀、只寫方式打開提供缺失的讀或者寫能力,不能單獨使用。獲取文件對象依舊按照r、w、a、x的特征 |
r只讀,wxa只寫
wxa都可以產生新文件
文件指針
- 指向當前字節位置
- mode=r 指針起始為0
- mode=a 指針起始在EOF
tell()
- 顯示指針當前位置
seek(offset[, whence])
- 移動指針位置,offset 移動字節數,
- whence 文本模式與二進制模式下操作的表現形式可能有不同
-
文本模式下
- whence 0 缺省值,表示從頭開始,offset只能正整數
- whence 1 表示從當前位置,offset只接受0
- whence 3 表示從EOF開始,offset只接受0
- 二進制模式下
- whence 0 缺省值,表示從頭開始,offset只能正整數
- whence 1 表示從當前位置,offset可正可負
- whence 2 表示從EOF開始,offset可正可負
二進制模式支持任意起點的偏移,從頭、從尾、從中間位置開始。
向後seek可以超界,但是向前seek的時候,不能超界,否則拋異常
buffering:緩沖區
- -1表示缺省buffer大小
- 二進制模式: 使用io.DEFAULT_BUFFER_SIZE值控制
- 文本模式: 如果是終端設備,使用行緩存,否則與二進制模式相同
- 0 只在二進制模式使用,表示關buffer
- 1 只在文本模式使用,表示行緩沖 (見到換行符就flush)
- 大於1 指定buffer大小
buffer緩沖區
- 一個內存空間,FIFO隊列,緩沖區滿或者達到閾值,就會flush到磁盤
-
flush()
- 將緩沖區數據寫入磁盤
- 調用close()時會先調用flush()
-
encoding:
- 僅文本模式使用
- 默認值None使用默認編碼(windows GBK,Linux UTF8)
-
errors
- None和strict 有錯誤將拋異常,ignore 忽略
-
newline
- 默認None ‘\n‘, ‘\r‘, ‘\r\n‘皆視為換行(都被轉換為/n)
- “表示不會自動轉換通用換行符
- 其他合法字符表示指定字符為換行符
- closefd
- 關閉文件描述符,True 關閉,False 文件關閉後保持描述符
read
- read(size=-1)
- size 讀取多少個字符或字節 負數或None 讀取到EOF
行讀取
-
readline(size=-1)
- 每次讀取一行,size 控制每次讀取一行的幾個字符或字節
- readlines(hint=-1)
- 讀取所有行的列表
write
- write(s) 返回寫入字符個數
- writelines(lines) 寫入字符串列表
其他
- seekable()
- readable()
- writable()
- closed
上下文管理
-
由解釋器釋放對象
- 語法:with ... as
- 上下文管理的語句塊不會開啟新的作用域
- 語句塊執行完自動關閉文件對象
內存IO
StringIO
from io import StringIO- 內存中開辟一個文本模式的buffer,可以像文件對象一樣操作
-
當調用close後,buffer會被釋放
- 方法與文件IO類似
-
getvalue()
- 獲取全部內容
- 優點
- 減少數據落地,提高運行效率
BytesIO
from io import BytesIO- 與StringIO類似
file-like對象
- 類文件對象:
- socket、stdin、stdout都是類文件對象
路徑操作
- 建議使用pathlib模塊,使用Path對象來操作
from pathlib import Path
路徑拼接與分解
操作符 /
- 操作符重載
- Path對象 / Path對象
- Path對象 / 字符串 或 字符串 / Path對象
parts
- 將路徑分解,返回一個元組
from pathlib import Path p3 = Path.cwd() p3.parts
output: (‘/‘, ‘data‘, ‘MyPythonObject‘)
joinpath
- 連接多個字符到Path對象中
獲取路徑
- str 獲取路徑字符串
- bytes 獲取路徑字節
父目錄
- parent 返回父目錄Path類對象
- parents 返回父目錄可叠代對象,索引0是當前直接的父目錄
其他
- name 目錄的最後一個部分
- suffix 目錄中最後一個部分的擴展名
- stem 目錄最後一個部分,沒有後綴
- suffixes 返回多個擴展名列表
- with_suffix(suffix) 補充擴展名到路徑尾部,返回新的路徑,擴展名存在則無效
-
with_name(name) 替換目錄最後一個部分並返回一個新的路徑
- cwd() 返回當前工作目錄
-
home() 返回當前家目錄
- is_dir() 是否目錄
- is_file() 是否普通文件
- is_symlink() 是否軟鏈接
- is_socket() 是否socket文件
- is_block_device() 是否塊設備
- is_char_device() 是否字符設備
-
is_absolute() 是否絕對路徑
- resolve() 返回當前Path對象的絕對路徑,如果是軟鏈接則直接被解析
-
absolute() 返回絕對路徑,建議使用resolve
- exists() 目錄或文件是否存在
- rmdir() 刪除空目錄。沒有提供判斷目錄為空的方法
- touch(mode=0o666,exist_ok=True) 創建一個文件
-
as_uri() 將路徑返回成URI,例如"file:///etc/passwd"
-
mkdir(mode=0o777,parents=False,exist_ok=False)
- parents 是否創建父目錄,True等同於mkdir -p False時,父目錄不存在,則拋FileNotFoundError
- exist_ok False時,路徑存在,拋出FileExistsError True時,忽略此異常
-
iterdir() 叠代當前目錄
-
glob() 通配給定的模式
-
rglob() 通配給定的模式,遞歸目錄 返回一個生成器
-
match() 模式匹配,成功返回True
-
stat() 查看文件屬性
- lstat() 同stat 但如果時鏈接文件,則顯示本身的文件信息
文件操作
-
open(mdoe=‘r‘,buffering=-1,encoding=None,errors=None,newline=None)
- 類似內建函數open 返回一個文件對象
-
read_bytes()
- 以‘rb’讀取
-
read_text(encoding=None,errors=None)
- 以“rt‘讀取
-
Path.write_bytes(data)
- 以wb寫入
- write_text(data,encoding=None,errors=None)
- 以‘wt‘寫入
os模塊
-
os.name
- windows是nt,Linux是posix
-
os.uname()
- 返回系統信息 僅linux
-
sys.platform
- windos顯示win32 linux顯示linux
-
os.listdir(‘0:/temp‘)
- 返回目錄內容列表
-
os.stat(path, *, dir_fd=None, follow_symlinks=True)
- 本質上調用Linux的stat
- path:路徑的string或bytes,或fd文件描述符
- follow_symlinks True返回文件本身信息,False 如果時軟鏈連接則顯示軟鏈接本身
-
os.chmod(path, mode, *, dir_fd=None, follow_symlinks=True)
- 參考Linux chmod命令
- os.chown(path, uid, gid, *, dir_fd=None, follow_symlinks=True)
- 參考Linux chown命令
shutil模塊
-
copyfileobj(fsrc, fdst[, length])
- 復制內容
-
copyfile(src, dst, *, follow_symlinks=True)
- 復制內容
-
copymode(src, dst, *, follow_symlinks=True)
- 復制權限
-
copystat(src, dst, *, follow_symlinks=True)
- 復制元數據,包括權限
-
copy(src, dst, *, follow_symlinks=True)
- 復制內容、權限
-
copy2(src, dst, *, follow_symlinks=True)
- 復制內容、元數據
-
copytree(src, dst, symlinks=False, ignore=None, copy_function=copy2, ignore_dangling_symlinks=False)
- 遞歸復制目錄 默認使用copy2
-
rmtree(path, ignore_errors=False, onerror=None)
- 遞歸刪除 慎用
- move(src, dst, copy_function=copy2)
- 遞歸移動文件、目錄
csv文件
- Comma-Separated Values
- 被行分隔符、列分隔符劃分成行與列
-
csv不指定字符編碼
- 行分隔符為\r\n
- 列分隔符常為逗號或制表符
如果字段中含有雙引號、逗號、換行符,必須使用雙引號括起來。
如果字段本身包含雙引號,使用兩個雙引號表示一個轉義
csv模塊
-
reader(csvfile, dialect=‘excel‘, **fmtparams)
- 返回DictReader對象,是一個行叠代器
-
fmtparams可設置
- delimiter 列分隔符,默認逗號
- lineterninator 行分隔符 默認/r/n
-
quotechar 字段引用符號,默認雙引號
- doublequote 雙引號處理 默認True ,quochar顯示兩個,False 使用eacapechar作為quotechar的前綴
- escapechar 轉義字符,默認None
- quoting 指定雙引號規則。QUOTE_ALL所有字段 QUOTE_MINIMAL特殊字符字段 QUOTE_NONNUMNERIC非數字字段 QUOTE_NONE 不適用引號
- writer(csvfile, dialect=‘excel‘, **fmtparams)
- 返回DictWriter實例
- DictWriter的主要方法有writerow、writerows
ini文件
- ini文件格式形如:
[DEFAULT]
a = test
[mysql]
default-character-set=utf8
a = 1000
[mysqld]
datadir =/dbserver/data
port = 33060
character-set-server=utf8
sql_mode=NO_ENGINE_SUBSTITUTION,STRICT_TRANS_TABLES- 中括號的內容稱為section
- 每個section中,都是key,value形式的鍵值對,key稱為option
缺省section DEFAULT必須大寫
configparser模塊
ConfigParserle類
from configparser import ConfigParser
cfg = ConfigParser()-
可將section當作key,其對應的值是存儲著option的鍵值對字典,即ini文件是一個嵌套字典。默認使用有序字典
-
read(filenames, encoding=None)
- 讀取文件,filenames可單獨文件或文件列表
-
sections()
- 返回section列表。不包括缺省section
-
add_section(section_name)
- 增加section
-
has_section(section_name)
- 是否存在一個section
-
options(section)
- 返回一個section的options,包括缺省section的options
-
has_option(section)
- 是否存在一個section的option
-
get(section, option, *, raw=False, vars=None[, fallback])
- 從指定的section的option取值,如未找到,去DEFAULT找
- getint(section, option, *, raw=False, vars=None[, fallback])
- getfloat(section, option, *, raw=False, vars=None[, fallback])
-
getboolean(section, option, *, raw=False, vars=None[, fallback])
- 返回指定類型數據
-
items(raw=False, vars=None)
- 返回所有section名與其對象
-
items(section, raw=False, vars=None)
- 返回指定section的option的鍵值對二元組
-
set(section, option, value)
- 設置指定section的option=value(option,value必須為字符串 ),section不存在則拋異常
-
remove_section(section)
- 移除section及其option
-
remove_option(section, option)
- 移除指定section下的指定option
- write(fileobject, space_around_delimiters=True)
- 將當前config的所有內容寫入fileobject中
序列化與反序列化
定義
-
serialization 序列化
- 將內存中對象存儲下來,把它變成一個個字節 -> 二進制
-
deserialization 反序列化
- 將文件的一個個字節恢復成內存中對象 <- 二進制
- 序列化保存到文件就是持久化
- 一般將數據序列化後持久化或進行網絡傳輸或是從文件、接受自網絡的字節序列反序列化
pickle庫
-
dump(obj, protocol=None, *, fix_imports=True)
- 將對象序列化為bytes對象
-
dump(obj, file, protocol=None, *, fix_imports=True)
- 將對象序列化到文件對象,即存入文件
-
loads(file, *, fix_imports=True, encoding="ASCII", errors="strict")
- 從bytes對象反序列化
- load(bytes_object, *, fix_imports=True, encoding="ASCII", errors="strict")
- 從文件讀取數據反序列化
序列化、反序列化實驗
序列化應用
- 一般使用在網絡傳輸中,將數據序列化後通過網絡傳輸到遠程節點,遠程服務器上的服務將接收到的數據反序列化使用
- 註意:遠程接收端反序列化時必須有對應的數據類型,否則會報錯。尤其自定義類,必須遠程端有一致的定義
- 大多數項目都不是單機、單服務的。需要通過網路將數據傳送到其他節點,因此需要大量的序列化與反序列化
- 但是如果跨平臺、跨語言、跨協議之間通常使用XML、Json、Protocol Buffer等。不選擇pickle
Json模塊
-
JavaScript Object Notation
- Json數據類型
-
值
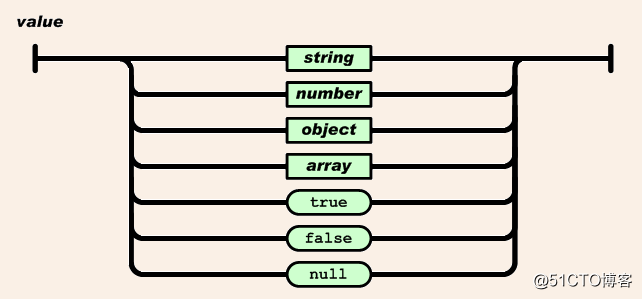
-
字符串
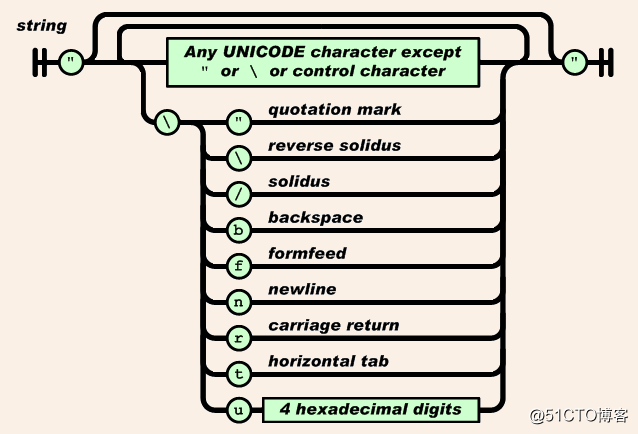
-
數值
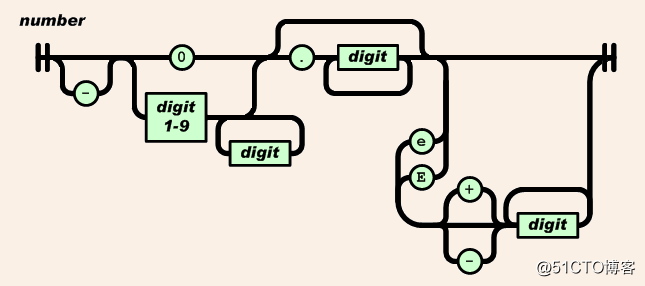
-
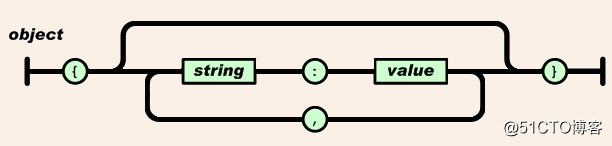
對象
- 無序鍵值對集合
- key必須是字符串,用雙引號包圍
- value可任意合法值
- 數組
- 有序的值的集合

- 有序的值的集合
常用方法
import json-
dumps(obj, *, skipkeys=False, ensure_ascii=True, check_circular=True, allow_nan=True, cls=None, indent=None, separators=None, default=None, sort_keys=False, **kw)
- json編碼
-
dump(obj, fp, *, skipkeys=False, ensure_ascii=True, check_circular=True, allow_nan=True, cls=None, indent=None, separators=None, default=None, sort_keys=False, **kw)
- json編碼並存入文件
-
loads(s, *, encoding=None, cls=None, object_hook=None, parse_float=None, parse_int=None, parse_constant=None, object_pairs_hook=None, **kw)
- json解碼
- load(fp, *, cls=None, object_hook=None, parse_float=None, parse_int=None, parse_constant=None, object_pairs_hook=None, **kw)
- json解碼,從文件讀取數據
MessagePack模塊
- 與json類似,但同樣數據所占空間要小於Json
安裝
- $ pip install msgpack-python
常用方法
import msgpack-
packb(o, **kwargs) <=> dumps
- 序列化對象。提供了dumps來兼容pickle和json
-
unpackb(packed, object_hook=None, list_hook=None, bool use_list=1, encoding=None, unicode_errors=‘strict‘, object_pairs_hook=None, ext_hook=ExtType, Py_ssize_t max_str_len=2147483647, Py_ssize_t max_bin_len=2147483647, Py_ssize_t max_array_len=2147483647, Py_ssize_t max_map_len=2147483647, Py_ssize_t max_ext_len=2147483647) <==> loads
- 反序列化對象。提供了loads來兼容
-
pack(o, stream, **kwargs) <==> dump
- 序列化對象保存到文件對象。提供了dump來兼容
- unpack(stream, object_hook=None, list_hook=None, bool use_list=1, encoding=None, unicode_errors=‘strict‘, object_pairs_hook=None, ext_hook=ExtType, Py_ssize_t max_str_len=2147483647, Py_ssize_t max_bin_len=2147483647, Py_ssize_t max_array_len=2147483647, Py_ssize_t max_map_len=2147483647, Py_ssize_t max_ext_len=2147483647) <==> load
- 反序列化對像保存到文件對象。提供了load來兼容
Python第六周 學習筆記(1)