
分布式事務解決辦法
什麽是分布式事務?
簡單的說,就是一次大的操作由不同的小操作組成,這些小的操作分布在不同的服務器上,且屬於不同的應用,分布式事務需要保證這些小操作要麽全部成功,要麽全部失敗。本質上說,分布式事務就是為了保證不同數據庫的數據一致性。
分布式事務產生的原因
服務化,隨著服務化,出現各個微服務,以及這些服務對應的庫表,多個庫表之間的數據操作 可能需要保證原子性。
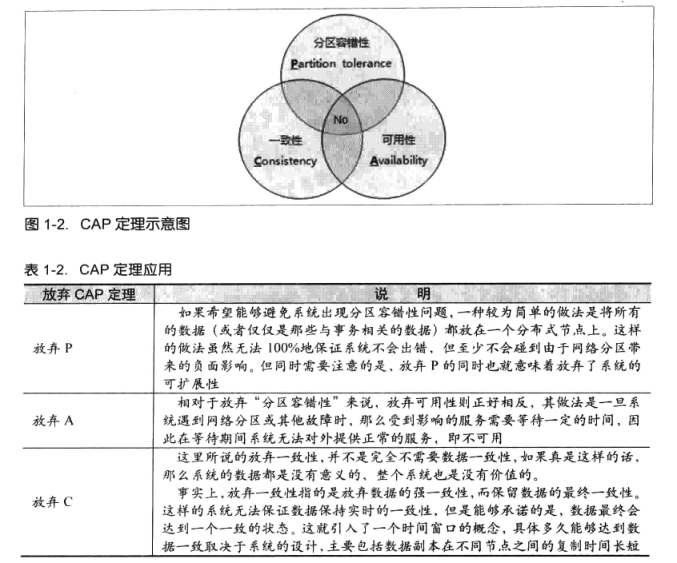
CAP定理
CAP理論告訴我們,一個分布式系統不可能同時滿足 一致性(C:Consistency)、可用性(A:Availability)和分區容錯性(P:Partion tolerance)這三個基本需求,最多只能同時滿足其中的兩項。
一致性
在分布式環境下,一致性是指數據在多個副本之間是否能夠保持一致的特性。
可用性
可用性是指系統提供的服務必須一直處於可用的狀態,對於用戶的每一個操作請求總是能夠在有限的時間內返回正確結果。
分區容錯性
分布式系統在遇到任何網絡分區故障的時候,仍然需要能夠保證對外提供滿足一致性和可用性的服務,除非是整個網絡環境都發生了故障。
網絡分區是指在分布式系統中,不同的節點分布在不同的子網絡(機房或異地網絡等)中,由於一些特殊的原因導致這些子網絡之間出現網絡不連通的狀況,但各個子網絡的內部網絡是正常的,從而導致整個系統的網絡環境被切分成了若幹孤立的區域。需要註意的是,組成一個分布式系統的每個節點的加入與退出都可以看作是一個特殊的網絡分區。
BASE理論
BASE理論指的是:
- Basically Available(基本可用):允許響應時間拉長,允許功能上的損失,允許降級頁面(系統繁忙,稍後重試等)
- Soft state(軟狀態):是指允許系統中的數據存在中間狀態,並認為該中間狀態的存在不會影響系統的整體可用性。
- Eventually consistent(最終一致性):本質就是需要保證最終數據能夠達到一致性,而不需要實時保證系統數據的強一致性。
兩階段提交
階段一 提交事務請求
- 事務詢問:
協調者向所有的參與者發送事務內容,詢問是否可以執行事務提交操作,並開始等待各參與者的響應。 - 執行事務:
各參與者節點執行事務操作,並將Undo和Redo信息記錄事務日誌中。 - 各參與者向協調者反饋事務詢問的響應:
如果參與者成功執行了事務操作,那麽就反饋給協調者Yes響應,表示事務可以執行;如果參與者沒有成功執行事務,那麽就反饋給協調者No響應,表示事務不可以執行。
上面的過程在形式上近似是協調者組織各參與者對一次事務操作的投票表態過程,因此這個階段也被稱為“投票階段”,即各參與者投票表明是否要繼續執行接下去的事務提交操作。
階段二 執行事務提交
在階段二中,協調者會根據各參與者的反饋情況來決定最終是否可以進行事務提交操作,正常情況下,包含以下兩種可能:
執行事務提交:
假如協調者從所有的參與者獲得的反饋都是Yes響應,那麽就會執行事務提交。
- 發送提交請求:協調者向所有參與者節點發出Commit請求。
- 事務提交:參與者接收到Commit請求後,會正式執行事務提交操作,並在完成提交之後釋放在整個事務執行期間占用的事務資源。
- 反饋事務提交結果:參與者在完成事務提交之後,向協調者發送ACK消息。
- 完成事務:協調者接收到所有參與者反饋的Ack消息後,完成事務。
中斷事務
假如任何一個參與者向協調者反饋了No響應,或者在等待超時之後,協調者尚無法接收到所有參與者的反饋響應,那麽就會中斷事務。
- 發送回滾請求:協調者向所有參與者階段發出Rollback請求。
- 執行事務回滾:參與者接收到Rollback請求後,會利用其在階段一中記錄的Undo信息來執行事務回滾操作,並在完成回滾之後釋放在整個事務執行期間占用的資源。
- 反饋事務回滾結果:參與者在完成事務回滾之後,向協調者發送Ack消息。
- 完成事務中斷:協調者接收到所有參與者反饋的Ack消息後,完成事務中斷。
兩階段提交將一個事務的處理過程分為了投票和執行兩個階段,其核心是對每個事務都采用先嘗試後提交的處理方式。
優缺點
兩階段提交協議的優點:原理簡單,實現方便。
兩階段提交協議的缺點:
- 同步阻塞:在兩階段提交的執行過程中,所有參與該事務操作的邏輯都處於阻塞狀態,也就是說,各個參與者在等待其他參與者響應的過程中,將無法進行任何其他操作。
- 單點問題:協調者單點問題。
- 數據不一致:在兩階段提交協議的階段二,即執行事務提交的時候,當協調者向所有的參與者發送Commit請求之後。發送了局部網絡異常或者是協調者在尚未發送完Commit請求之前自身發生了崩潰,導致最終只有部門參與者收到了Commit請求。於是,這部分收到了Commit請求的參與者就會進行事務的提交,而其它沒有收到Commit請求的參與者則無法進行事務提交,於是整個分布式系統便出現了數據不一致性的問題。
- 太過保守:如果在協調者指示參與者進行事務提交詢問的過程中,參與者出現故障而導致協調者始終無法獲取到所有參與者的響應信息的話,這時協調者只能依靠自身的超時機制來判斷是否需要中斷事務,這樣的策略顯得比較保守。換句話說,兩階段提交協議沒有設計較為完善的容錯機制,任意一個節點的失敗都會導致整個事務的失敗。
三階段提交
協議說明
三階段提交,將兩階段提交協議的“提交事務內容”過程一分為二,形成了由CanCommit、PreCommit和DoCommit三個階段組成的事務處理協議。
階段一
- 事務詢問:協調者向所有的參與者發送一個包含事務內容的canCommit請求,詢問是否可以執行事務提交操作,並開始等待各參與者的響應。
- 等待反饋:各參與者在接收到來自協調者的canCommit請求後,正常情況下,如果其自身認為可以順序執行事務,那麽會反饋Yes響應,並進入預備狀態,否則反饋No響應。
階段二:PreCommit
在階段二中,協調者會根據各參與者的反饋情況來決定是否可以進行事務的PreCommit操作,正常情況下,包含兩種可能。
執行事務預提交:
假如協調者從所有的參與者獲得的反饋都是Yes響應,那麽就會執行事務預提交。
- 發送事務預提交請求:協調者向所有參與者節點發出PreCommit的請求,並進入Prepared階段。
- 執行事務預提交操作:參與者接收到preCommit請求後,會執行事務操作,並將Undo和Redo信息記錄到事務日誌中。(執行但不提交)
- 反饋事務執行的響應:如果參與者成功執行了事務操作,那麽就會反饋給協調者Ack響應,同時等待最終的指令:提交(commit)或中止(abort)。
中斷事務:
假如任何一個參與者向協調者反饋了No響應,或者在等待超時之後,協調者尚無法接收到所有參與者的反饋響應,那麽就會中斷事務。
- 發送中斷請求:協調者向所有參與者節點發出abort請求。
- 無論是收到來自協調者的abort請求,或者是在等待協調者發送請求過程中出現超時,參與者都會中斷事務。
階段三:doCommit
該階段將進行真正的事務提交,會存在以下兩種可能的情況。
執行提交
- 發送提交請求:進入這一階段,假設協調者處於正常工作狀態,並且它接收到了來自所有參與者的Ack響應,那麽它將從“預提交”狀態轉換到“提交”狀態,並向所有的參與者發送doCommit請求。
- 執行事務操作:參與者接收到doCommit請求後,會正式執行事務提交操作,並在完成提交之後釋放在整個事務執行期間占用的事務資源。
- 反饋事務提交結果:參與者在完成事務提交之後,向協調者發送Ack消息。
- 完成事務:協調者接收到所有參與者反饋的Ack消息之後,完成事務。
中斷事務:
如果有任意一個參與者向協調者反饋了No響應,或者在等待超時之後,協調者尚無法接收到所有參與者的反饋響應,那麽就會中斷事務。
- 發送中斷請求:協調者向所有的參與者節點發送abort請求。
- 事務回滾:參與者接收到abort請求後,會利用其在階段二中記錄的Undo信息來執行事務回滾操作,並在完成回滾之後釋放在整個事務執行期間占用的資源。
- 反饋事務回滾結果:參與者在完成事務回滾之後,向協調者發送Ack消息。
- 中斷事務:協調者接收到所有參與者反饋的Ack消息後,中斷事務。
需要註意的是,一旦進入階段三,可能會存在以下兩種故障:
- 協調者出現問題。
- 協調者和參與者之間的網絡出現故障。
無論出現那種情況,最終都會導致參與者無法及時接收到來自協調者的doCommit或是abort請求,針對於這樣的異常情況,參與者都會在等待超時之後,繼續進行事務提交。(樂觀態度,認為前面已經進行過PreCommit請求了,事務一定能執行成功)。
優缺點:
三階段提交協議的優點:相較於兩階段提交協議,三階段提交協議最大的優點是降低了參與者的阻塞範圍,並且能夠在出現單點故障後繼續達成一致。
三階段提交協議的缺點:三階段提交協議在去除阻塞的同時也引入了新的問題,那就是在參與者接收到preCommit消息後,如果網絡出現分區,此時協調者所在的節點和部分參與者無法進行正常的網絡通信,在這種情況下,該參與者依然會進行事務的提交,這必然出現數據的不一致性。
ZooKeeper的ZAB協議
ZooKeeper並沒有完全采用Paxos算法,而是使用了一種稱為ZooKeeper Atomic Broadcast(ZAB,ZooKeeper原子消息廣播協議)的協議作為其數據一致性的核心算法。
ZAB協議是為分布式協調服務ZooKeeper專門設計的一種支持崩潰恢復的原子廣播協議。
ZAB並不是分布式事務的解決方案,而是分布式(主從)各副本之間的數據一致性解決方案。
ZAB的核心是定義了對於那些會改變ZooKeeper服務器數據狀態的事務請求的處理方式。
消息廣播
ZooKeeper只允許唯一的一個Leader服務器來接收並處理客戶端的所有事務請求,非Leader服務器即使接收到事務請求,也會轉發給Leader服務器。
所有事務請求必須由一個全局唯一的服務器來協調處理,這樣的服務器被稱為Leader服務器,而余下的其他服務器則成為Follower服務器。Leader服務器負責將一個客戶端事務請求轉換成一個事務Proposal(提議),並將該Proposal分發給集群中所有的Follower服務器。之後Leader服務器需要等待所有Follower服務器的反饋,一旦超過半數的Follower服務器進行了正確的反饋後,那麽Leader就會再次向所有的Follower服務器分發Commit消息,要求其將前一個Proposal進行提交。
這是一個類似於兩階段提交的過程,但是需要註意此處是只要求有超過半數的Follower服務器進行了正確的反饋即提交事務;並且在ZAB協議的提交過程中,移除了中斷邏輯,所有的Follower服務器要麽正常反饋Leader提出的事務Proposal,要麽拋棄Leader服務器。
消息順序性的處理
在整個消息廣播中,Leader服務器會為每個事務請求生成對應的Proposal來進行廣播,並且在廣播事務Proposal之前,Leader服務器會首先為這個事務Proposal分配一個全局單調遞增的唯一ID,我們稱之為事務ID(ZXID)。由於ZAB協議需要保證每一個消息嚴格的因果關系,因此必須將每一個Proposal按照其ZXID的先後順序來進行排序和處理。
這個ZXID是一個64位的數字,其中低32位可以看作是一個簡單的單調遞增的計數器,針對客戶端的每一個事務請求,Leader服務器在產生一個新的事務Proposal的時候,都會對該計數器進行加1操作。而高32位則代表了Leader周期epoch的編號,每當選舉產生一個新的Leader服務器,就會從這個Leader服務器上取出其本地日誌中最大事務Proposal的ZXID,並從該ZXID中解析出對於的epoch值,然後再對其進行加1操作,之後就會以此編號作為新的epoch,並將低32位置0來開始生成新的ZXID。
具體的保證順序性的解決辦法就是,在消息廣播過程中,Leader服務器會為每一個Follower服務器都各自分配一個單獨的隊列,然後將需要廣播的事務Proposal依次放入這些隊列中,並且根據FIFO策略來進行消息發送。每一個Follower服務器在接收到這個事務Proposal之後,都會首先將其以事務日誌的形式寫入到本地磁盤中去,並且在成功寫入後反饋給Leader服務器一個Ack響應。當Leader服務器接收到超過半數Follower的Ack響應之後,就會廣播一個Commit消息給所有的Follower服務器以通知其進行事務提交,同時Leader自身也會完成對事務的提交,而每一個Follower服務器在接收到Commit消息後,也會完成對事務的提交。
崩潰恢復(Leader選舉)
一旦Leader服務器出現崩潰,或者說由於網絡原因導致Leader服務器失去了與過半Follower的聯系,那麽就會進入崩潰恢復模式。此時,ZK集群將會發起一輪Leader選舉,選舉規則是:優先選事務ID大的,在事務Id相同的情況下,優先選服務器編號大的。
第一輪每臺服務器都選擇自己,並進行投票廣播;同時也接收來自其他服務器的投票信息,並拿接收到的投票中事務ID和服務器編號與自己的投票對比,誰高就選誰,然後再次廣播投票。 每次接收到投票,都會計算自己接收到選票是否能判斷某臺機器已經有超過半數的選票,一旦感知到這種情況,就會更改自己的狀態。 這樣選舉出來的Leader一定擁有集群中最大的事務ID,也就是數據最全的那臺機器。
因為是事務Id最大的機器,那個這個新選舉出來的leader一定具有所有已提交的提案。更為重要的是,如果讓具有最高事務Id的機器來成為Leader,就可以省去Leader服務器檢查Proposal的提交和丟失工作這一步操作了。 這裏說的提交是指:ZAB協議需要確保那些已經在Leader服務器上提交的事務最終被所有服務器提交。這裏說的丟棄是指:ZAB協議需要確保丟棄那些只在Leader服務器上被提出的事務。
數據同步
在完成Leader選舉之後,Leader服務器會檢查事務日誌中的所有已經提交的Proposal是否都已經被集群中過半的機器提交了,即是否完成數據同步。數據同步過程如下:
Leader服務器會為每一個Follower服務器都準備一個隊列,並將那些沒有被各個Follower服務器同步的事務以Proposal消息的形式逐個發送給Follower服務器,並在每一個Proposal消息後面緊接著再發送一個Commit消息,以表示該事務已經被提交。等到Follower服務器將所有其尚未同步的事務Proposal都從Leader服務器上同步過來並成功應用到本地數據庫中後,Leader服務器就會將該Follower服務器加入到真正可用的Follower列表中,並開始之後的其他流程。
分布式事務解決方案:
原則上盡量避免分布式事務,保證強一致性的成本遠比快速發現不一致並修復的成本高。
補償事務機制,保證最終一致性
事務補償就是指在事務鏈中的任何一個正向事務操作,都必須存在一個完全符合回滾規則的可逆事務。如果是一個完整的事務鏈,則必須保證事務鏈中的每一個業務操作都有對應的可逆服務。
比如提現操作,需要經歷賬戶余額扣除,第三方真正打款等多個操作。此時,如果使用補償操作流程如下:
- 用戶發起提現,扣除用戶賬戶余額,生成提現流水。
- 提交給第三方。
- 第三方嘗試打款,無論成功與失敗都會通知發起方。
- 發起方收到通知後,如果發現提現失敗,就嘗試給用戶生成一條提現失敗返回流水。將之前扣減的錢返回去。
TCC(try Confirm Cancel)
TCC其實也就是采用的補償機制,它分為三個階段:
- Try階段主要是對業務系統做檢測及資源預留。
- Confirm階段主要是對業務操作做確認提交,
- Cancel階段主要是在業務執行錯誤,需要回滾的狀態下執行的業務取消操作,釋放預留資源。
以會員卡扣款或余額消費或優惠券使用 凍結/占用-使用-核銷流程為例:
- try:檢查賬戶余額是否充足,充足的話就凍結(相當於預留出的資源,也可對多個資源進行凍結)
- confirm:執行整個分布式事務操作(相當於只利用try預留出的資源)。
- cancel:恢復try階段預留的資源。(若在某一個階段失敗,則將try預留的資源恢復try前的狀態,理解為把余額給加回去)
再以在線下單為例,Try階段會去扣庫存,Confirm階段則是去更新訂單狀態,如果更新訂單失敗,則進入Cancel階段,會去恢復庫存。
總之,TCC就是通過代碼人為實現了兩階段提交,不同的業務場景所寫的代碼都不一樣,復雜度也不一樣,因此,這種模式並不能很好地被復用。
基於消息的分布式事務
這類事務機制將分布式事務分成多個本地事務,這裏稱之為主事務與從事務。首先主事務本地進行提交,然後使用消息通知從事務,從事務從消息中獲取事務操作關鍵信息進行本地操作提交。可以看出這是一個異步事務機制、只能保證最終一致性;但可用性非常高,不會因為故障而發生阻塞。另外,主事務已經先行提交,如果因為從事務無法提交,要回滾主事務還是比較麻煩,所以這種模式只適用於理論上大概率成功的業務情況,即從事務的提交失敗可能是由於故障,而不大可能是邏輯錯誤。
基於異步消息的事務機制主要有兩種方式:本地消息表與事務消息。二者的區別在於:怎麽保證主事務的提交與消息發送這兩個操作的原子性。
本地消息表
基於本地消息表的方案是指將消息寫入本地數據庫,通過本地事務保證主事務與消息寫入的原子性。例如銀行轉賬的例子,偽碼如下:
begin transaction: update User set account = account - 100 where userId = 'A' ; insert into message(userId, amount, status) values('A', 100, 1) ; commit transaction主事務將消息寫入本地消息表後,從事務通過pull或者push模式,獲取消息並執行。如果是push模式,那麽一般使用具有持久化功能的消息隊列,從事務訂閱消息。如果是pull模式,那麽從事務定時去拉取消息,然後執行。
事務消息
所謂的事務消息就是基於消息中間件的兩階段提交,本質上是對消息中間件的一種特殊利用,它是將本地事務和發送消息放在一個分布式事務裏,保證要麽本地操作成功並且對外發送消息成功,要麽二者都失敗,開源的RocketMQ就支持這一特性(最新版已經不再支持了),下面我們以RocketMQ來分析其具體原理:
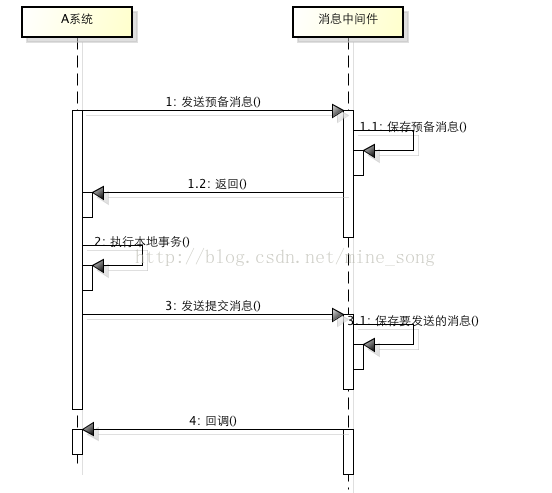
- RocketMQ第一階段發送Prepared消息時,會拿到消息的地址。
- 第二階段執行本地事務。
- 第三階段根據第二階段執行的結果通過第一階段拿到的地址去訪問消息,並修改消息狀態。如果此時確認消息發送失敗了,RocketMQ會定期掃描消息集群中的事務消息,如果發現了Prepared消息,就會向消息發送方確認(確認的方式 是強制在第一階段註冊一個回調接口,此時對該回調接口進行調用,獲得執行結果。),以決定事務消息狀態。
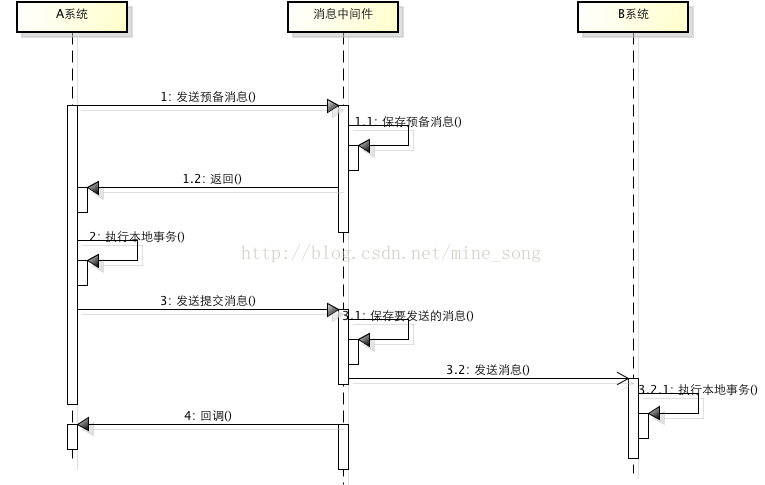
基於消息中間件的兩階段提交往往用在高並發場景下,將一個分布式事務拆分成一個消息事務(A系統的本地操作 + 發消息) + B系統的本地操作,其中B系統的操作由消息驅動,只要事務消息成功,那麽A操作一定成功,消息也一定發出來了,這時候B收到消息去執行本地操作,如果本地操作失敗,消息會重投,直到B操作成功,這樣就變相地實現了A與B的分布式事務。如果更完善的話,考慮B一直重試失敗情況,還可以提供一個A操作的回滾機制。整個過程原理如下:
對賬(最魯棒的技術)
實時對賬、準實時對賬、T+1的離線對賬。對不平,自動沖正,自動軋差。常見於交易結算等財務系統中。
最大努力送達型
- 允許中間狀態出現,比如提現處理中,同時記錄失敗記錄表,定時Job重試。
- 使用MQ延遲消息重試。
分布式事務解決辦法