
mq使用場景、不丟不重、時序性
mq使用場景、不丟不重、時序性、削峰
參考:
http://zhuanlan.51cto.com/art/201704/536407.htm
http://zhuanlan.51cto.com/art/201703/535090.htm
http://zhuanlan.51cto.com/art/201704/536306.htm
http://zhuanlan.51cto.com/art/201611/521602.htm
http://zhuanlan.51cto.com/art/201611/521602.htm
http://zhuanlan.51cto.com/art/201703/534752.htm
http://zhuanlan.51cto.com/art/201703/534475.htm
微信公眾號:架構師之路
到底什麽時候該使用MQ?
一、緣起
一切脫離業務的架構設計與新技術引入都是耍流氓。
引入一個技術之前,首先應該解答的問題是,這個技術解決什麽問題。
就像微服務分層架構之前,應該首先回答,為什麽要引入微服務,微服務究竟解決什麽問題(詳見《互聯網架構為什麽要做微服務?》)。
最近分享了幾篇MQ相關的文章:
《MQ如何實現延時消息》
《MQ如何實現消息必達》
《MQ如何實現冪等性》
不少網友詢問,究竟什麽時候使用MQ,MQ究竟適合什麽場景,故有了此文。
二、MQ是幹嘛的
消息總線(Message Queue),後文稱MQ,是一種跨進程的通信機制,用於上下遊傳遞消息。
在互聯網架構中,MQ是一種非常常見的上下遊“邏輯解耦+物理解耦”的消息通信服務。
使用了MQ之後,消息發送上遊只需要依賴MQ,邏輯上和物理上都不用依賴其他服務。
三、什麽時候不使用消息總線
既然MQ是互聯網分層架構中的解耦利器,那所有通訊都使用MQ豈不是很好?這是一個嚴重的誤區,調用與被調用的關系,是無法被MQ取代的。
MQ的不足是:
1)系統更復雜,多了一個MQ組件
2)消息傳遞路徑更長,延時會增加
3)消息可靠性和重復性互為矛盾,消息不丟不重難以同時保證
4)上遊無法知道下遊的執行結果,這一點是很致命的
舉個栗子:用戶登錄場景,登錄頁面調用passport服務,passport服務的執行結果直接影響登錄結果,此處的“登錄頁面”與“passport服務”就必須使用調用關系,而不能使用MQ通信。
無論如何,記住這個結論:調用方實時依賴執行結果的業務場景,請使用調用,而不是MQ。
四、什麽時候使用MQ
【典型場景一:數據驅動的任務依賴】
什麽是任務依賴,舉個栗子,互聯網公司經常在淩晨進行一些數據統計任務,這些任務之間有一定的依賴關系,比如:
1)task3需要使用task2的輸出作為輸入
2)task2需要使用task1的輸出作為輸入
這樣的話,tast1, task2, task3之間就有任務依賴關系,必須task1先執行,再task2執行,載task3執行。

對於這類需求,常見的實現方式是,使用cron人工排執行時間表:
1)task1,0:00執行,經驗執行時間為50分鐘
2)task2,1:00執行(為task1預留10分鐘buffer),經驗執行時間也是50分鐘
3)task3,2:00執行(為task2預留10分鐘buffer)
這種方法的壞處是:
1)如果有一個任務執行時間超過了預留buffer的時間,將會得到錯誤的結果,因為後置任務不清楚前置任務是否執行成功,此時要手動重跑任務,還有可能要調整排班表
2)總任務的執行時間很長,總是要預留很多buffer,如果前置任務提前完成,後置任務不會提前開始
3)如果一個任務被多個任務依賴,這個任務將會稱為關鍵路徑,排班表很難體現依賴關系,容易出錯
4)如果有一個任務的執行時間要調整,將會有多個任務的執行時間要調整
無論如何,采用“cron排班表”的方法,各任務耦合,誰用過誰痛誰知道(采用此法的請評論留言)
優化方案是,采用MQ解耦:
1)task1準時開始,結束後發一個“task1 done”的消息
2)task2訂閱“task1 done”的消息,收到消息後第一時間啟動執行,結束後發一個“task2 done”的消息
3)task3同理
采用MQ的優點是:
1)不需要預留buffer,上遊任務執行完,下遊任務總會在第一時間被執行
2)依賴多個任務,被多個任務依賴都很好處理,只需要訂閱相關消息即可
3)有任務執行時間變化,下遊任務都不需要調整執行時間
需要特別說明的是,MQ只用來傳遞上遊任務執行完成的消息,並不用於傳遞真正的輸入輸出數據。
【典型場景二:上遊不關心執行結果】
上遊需要關註執行結果時要用“調用”,上遊不關註執行結果時,就可以使用MQ了。
舉個栗子,58同城的很多下遊需要關註“用戶發布帖子”這個事件,比如招聘用戶發布帖子後,招聘業務要獎勵58豆,房產用戶發布帖子後,房產業務要送2個置頂,二手用戶發布帖子後,二手業務要修改用戶統計數據。
對於這類需求,常見的實現方式是,使用調用關系:
帖子發布服務執行完成之後,調用下遊招聘業務、房產業務、二手業務,來完成消息的通知,但事實上,這個通知是否正常正確的執行,帖子發布服務根本不關註。
這種方法的壞處是:
1)帖子發布流程的執行時間增加了
2)下遊服務當機,可能導致帖子發布服務受影響,上下遊邏輯+物理依賴嚴重
3)每當增加一個需要知道“帖子發布成功”信息的下遊,修改代碼的是帖子發布服務,這一點是最惡心的,屬於架構設計中典型的依賴倒轉,誰用過誰痛誰知道(采用此法的請評論留言)
優化方案是,采用MQ解耦:
1)帖子發布成功後,向MQ發一個消息
2)哪個下遊關註“帖子發布成功”的消息,主動去MQ訂閱
采用MQ的優點是:
1)上遊執行時間短
2)上下遊邏輯+物理解耦,除了與MQ有物理連接,模塊之間都不相互依賴
3)新增一個下遊消息關註方,上遊不需要修改任何代碼
典型場景三:上遊關註執行結果,但執行時間很長
有時候上遊需要關註執行結果,但執行結果時間很長(典型的是調用離線處理,或者跨公網調用),也經常使用回調網關+MQ來解耦。
舉個栗子,微信支付,跨公網調用微信的接口,執行時間會比較長,但調用方又非常關註執行結果,此時一般怎麽玩呢?
一般采用“回調網關+MQ”方案來解耦:
1)調用方直接跨公網調用微信接口
2)微信返回調用成功,此時並不代表返回成功
3)微信執行完成後,回調統一網關
4)網關將返回結果通知MQ
5)請求方收到結果通知
這裏需要註意的是,不應該由回調網關來調用上遊來通知結果,如果是這樣的話,每次新增調用方,回調網關都需要修改代碼,仍然會反向依賴,使用回調網關+MQ的方案,新增任何對微信支付的調用,都不需要修改代碼啦。
五、總結
MQ是一個互聯網架構中常見的解耦利器。
什麽時候不使用MQ?
上遊實時關註執行結果
什麽時候使用MQ?
1)數據驅動的任務依賴
2)上遊不關心多下遊執行結果
3)異步返回執行時間長
==【完】==
相關閱讀:
《MQ如何實現延時消息》
《MQ如何實現消息必達》
《MQ如何實現冪等性》
消息總線能否實現消息必達?
一、緣起
上周討論了兩期環形隊列的業務應用:
《高效定時任務的觸發》
《延遲消息的快速實現》
兩期的均有大量讀者提問:
- 任務、延遲消息都放在內存裏,萬一重啟了怎麽辦?
- 能否保證消息必達?
今天就簡單聊聊消息隊列(MsgQueue)的消息必達性架構與流程。
二、架構方向
MQ要想盡量消息必達,架構上有兩個核心設計點:
(1)消息落地
(2)消息超時、重傳、確認
三、MQ核心架構

上圖是一個MQ的核心架構圖,基本可以分為三大塊:
(1)發送方 -> 左側粉色部分
(2)MQ核心集群 -> 中間藍色部分
(3)接收方 -> 右側黃色部分
粉色發送方又由兩部分構成:業務調用方與MQ-client-sender
其中後者向前者提供了兩個核心API:
- SendMsg(bytes[] msg)
- SendCallback()
藍色MQ核心集群又分為四個部分:MQ-server,zk,db,管理後臺web
黃色接收方也由兩部分構成:業務接收方與MQ-client-receiver
其中後者向前者提供了兩個核心API:
- RecvCallback(bytes[] msg)
- SendAck()
MQ是一個系統間解耦的利器,它能夠很好的解除發布訂閱者之間的耦合,它將上下遊的消息投遞解耦成兩個部分,如上述架構圖中的1箭頭和2箭頭:
(1)發送方將消息投遞給MQ,上半場
(2)MQ將消息投遞給接收方,下半場
四、MQ消息可靠投遞核心流程
MQ既然將消息投遞拆成了上下半場,為了保證消息的可靠投遞,上下半場都必須盡量保證消息必達。

MQ消息投遞上半場,MQ-client-sender到MQ-server流程見上圖1-3:
- MQ-client將消息發送給MQ-server(此時業務方調用的是API:SendMsg)
- MQ-server將消息落地,落地後即為發送成功
- MQ-server將應答發送給MQ-client(此時回調業務方是API:SendCallback)
MQ消息投遞下半場,MQ-server到MQ-client-receiver流程見上圖4-6:
- MQ-server將消息發送給MQ-client(此時回調業務方是API:RecvCallback)
- MQ-client回復應答給MQ-server(此時業務方主動調用API:SendAck)
- MQ-server收到ack,將之前已經落地的消息刪除,完成消息的可靠投遞
1. 如果消息丟了怎麽辦?
MQ消息投遞的上下半場,都可以出現消息丟失,為了降低消息丟失的概率,MQ需要進行超時和重傳。
2. 上半場的超時與重傳
MQ上半場的1或者2或者3如果丟失或者超時,MQ-client-sender內的timer會重發消息,直到期望收到3,如果重傳N次後還未收到,則SendCallback回調發送失敗,需要註意的是,這個過程中MQ-server可能會收到同一條消息的多次重發。
3. 下半場的超時與重傳
MQ下半場的4或者5或者6如果丟失或者超時,MQ-server內的timer會重發消息,直到收到5並且成功執行6,這個過程可能會重發很多次消息,一般采用指數退避的策略,先隔x秒重發,2x秒重發,4x秒重發,以此類推,需要註意的是,這個過程中MQ-client-receiver也可能會收到同一條消息的多次重發。
MQ-client與MQ-server如何進行消息去重,如何進行架構冪等性設計,下一次撰文另述,此處暫且認為為了保證消息必達,可能收到重復的消息。
五、總結
消息總線是系統之間的解耦利器,但切勿濫用,未來也會撰文細究MQ的使用場景,消息總線為了盡量保證消息必達,架構設計方向為:
- 消息收到先落地
- 消息超時、重傳、確認保證消息必達
消息總線真的能保證冪等?
一、緣起
如《消息總線消息必達》所述,MQ消息必達,架構上有兩個核心設計點:
(1)消息落地
(2)消息超時、重傳、確認

再次回顧消息總線核心架構,它由發送端、服務端、固化存儲、接收端四大部分組成。
為保證消息的可達性,超時、重傳、確認機制可能導致消息總線、或者業務方收到重復的消息,從而對業務產生影響。
舉個栗子:
購買會員卡,上遊支付系統負責給用戶扣款,下遊系統負責給用戶發卡,通過MQ異步通知。不管是上半場的ACK丟失,導致MQ收到重復的消息,還是下半場ACK丟失,導致購卡系統收到重復的購卡通知,都可能出現,上遊扣了一次錢,下遊發了多張卡。
消息總線的冪等性設計至關重要,是本文將要討論的重點。
二、上半場的冪等性設計

MQ消息發送上半場,即上圖中的1-3
- 1,發送端MQ-client將消息發給服務端MQ-server
- 2,服務端MQ-server將消息落地
- 3,服務端MQ-server回ACK給發送端MQ-client
如果3丟失,發送端MQ-client超時後會重發消息,可能導致服務端MQ-server收到重復消息。
此時重發是MQ-client發起的,消息的處理是MQ-server,為了避免步驟2落地重復的消息,對每條消息,MQ系統內部必須生成一個inner-msg-id,作為去重和冪等的依據,這個內部消息ID的特性是:
(1)全局唯一
(2)MQ生成,具備業務無關性,對消息發送方和消息接收方屏蔽
有了這個inner-msg-id,就能保證上半場重發,也只有1條消息落到MQ-server的DB中,實現上半場冪等。
三、下半場的冪等性設計

MQ消息發送下半場,即上圖中的4-6
- 4,服務端MQ-server將消息發給接收端MQ-client
- 5,接收端MQ-client回ACK給服務端
- 6,服務端MQ-server將落地消息刪除
需要強調的是,接收端MQ-client回ACK給服務端MQ-server,是消息消費業務方的主動調用行為,不能由MQ-client自動發起,因為MQ系統不知道消費方什麽時候真正消費成功。
如果5丟失,服務端MQ-server超時後會重發消息,可能導致MQ-client收到重復的消息。
此時重發是MQ-server發起的,消息的處理是消息消費業務方,消息重發勢必導致業務方重復消費(上例中的一次付款,重復發卡),為了保證業務冪等性,業務消息體中,必須有一個biz-id,作為去重和冪等的依據,這個業務ID的特性是:
(1)對於同一個業務場景,全局唯一
(2)由業務消息發送方生成,業務相關,對MQ透明
(3)由業務消息消費方負責判重,以保證冪等
最常見的業務ID有:支付ID,訂單ID,帖子ID等。
具體到支付購卡場景,發送方必須將支付ID放到消息體中,消費方必須對同一個支付ID進行判重,保證購卡的冪等。
有了這個業務ID,才能夠保證下半場消息消費業務方即使收到重復消息,也只有1條消息被消費,保證了冪等。
三、總結
MQ為了保證消息必達,消息上下半場均可能發送重復消息,如何保證消息的冪等性呢?
上半場
- MQ-client生成inner-msg-id,保證上半場冪等。
- 這個ID全局唯一,業務無關,由MQ保證。
下半場
- 業務發送方帶入biz-id,業務接收方去重保證冪等。
- 這個ID對單業務唯一,業務相關,對MQ透明。
結論:冪等性,不僅對MQ有要求,對業務上下遊也有要求。
消息“時序”與“一致性”為何這麽難?
分布式系統中,很多業務場景都需要考慮消息投遞的時序,例如:
(1)單聊消息投遞,保證發送方發送順序與接收方展現順序一致
(2)群聊消息投遞,保證所有接收方展現順序一致
(3)充值支付消息,保證同一個用戶發起的請求在服務端執行序列一致
消息時序是分布式系統架構設計中非常難的問題,ta為什麽難,有什麽常見優化實踐,是本文要討論的問題。
一、為什麽時序難以保證,消息一致性難?
為什麽分布式環境下,消息的時序難以保證,這邊簡要分析了幾點原因:
【時鐘不一致】
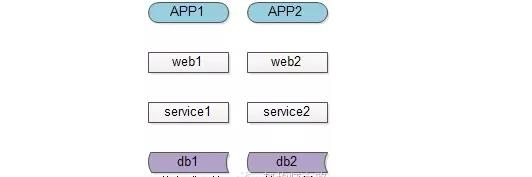
分布式環境下,有多個客戶端、有web集群、service集群、db集群,他們都分布在不同的機器上,機器之間都是使用的本地時鐘,而沒有一個所謂的“全局時鐘”,所以不能用“本地時間”來完全決定消息的時序。
【多客戶端(發送方)】
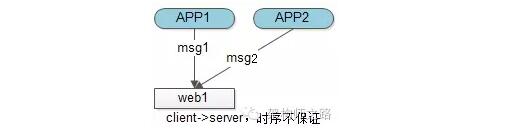
多服務器不能用“本地時間”進行比較,假設只有一個接收方,能否用接收方本地時間表示時序呢?遺憾的是,由於多個客戶端的存在,即使是一臺服務器的本地時間,也無法表示“絕對時序”。
如上圖,絕對時序上,APP1先發出msg1,APP2後發出msg2,都發往服務器web1,網絡傳輸是不能保證msg1一定先於msg2到達的,所以即使以一臺服務器web1的時間為準,也不能精準描述msg1與msg2的絕對時序。
【服務集群(多接收方)】
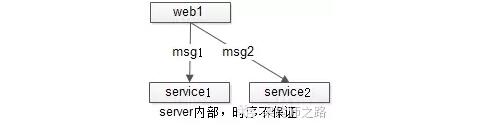
多發送方不能保證時序,假設只有一個發送方,能否用發送方的本地時間表示時序呢?遺憾的是,由於多個接收方的存在,無法用發送方的本地時間,表示“絕對時序”。
如上圖,絕對時序上,web1先發出msg1,後發出msg2,由於網絡傳輸及多接收方的存在,無法保證msg1先被接收到先被處理,故也無法保證msg1與msg2的處理時序。
【網絡傳輸與多線程】
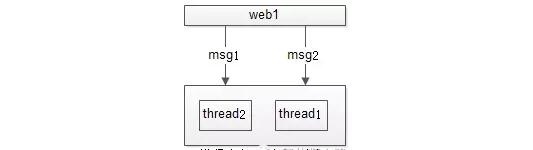
多發送方與多接收方都難以保證絕對時序,假設只有單一的發送方與單一的接收方,能否保證消息的絕對時序呢?結論是悲觀的,由於網絡傳輸與多線程的存在,仍然不行。
如上圖,web1先發出msg1,後發出msg2,即使msg1先到達(網絡傳輸其實還不能保證msg1先到達),由於多線程的存在,也不能保證msg1先被處理完。
【怎麽保證絕對時序】
通過上面的分析,假設只有一個發送方,一個接收方,上下遊連接只有一條連接池,通過阻塞的方式通訊,難道不能保證先發出的消息msg1先處理麽?
回答:可以,但吞吐量會非常低,而且單發送方單接收方單連接池的假設不太成立,高並發高可用的架構不會允許這樣的設計出現。
二、優化實踐
【以客戶端或者服務端的時序為準】
多客戶端、多服務端導致“時序”的標準難以界定,需要一個標尺來衡量時序的先後順序,可以根據業務場景,以客戶端或者服務端的時間為準,例如:
(1)郵件展示順序,其實是以客戶端發送時間為準的,潛臺詞是,發送方只要將郵件協議裏的時間調整為1970年或者2970年,就可以在接收方收到郵件後一直“置頂”或者“置底”
(2)秒殺活動時間判斷,肯定得以服務器的時間為準,不可能讓客戶端修改本地時間,就能夠提前秒殺
【服務端能夠生成單調遞增的id】
這個是毋庸置疑的,不展開討論,例如利用單點寫db的seq/auto_inc_id肯定能生成單調遞增的id,只是說性能及擴展性會成為潛在瓶頸。對於嚴格時序的業務場景,可以利用服務器的單調遞增id來保證時序。
【大部分業務能接受誤差不大的趨勢遞增id】
消息發送、帖子發布時間、甚至秒殺時間都沒有這麽精準時序的要求:
(1)同1s內發布的聊天消息時序亂了
(2)同1s內發布的帖子排序不對
(3)用1s內發起的秒殺,由於服務器多臺之間時間有誤差,落到A服務器的秒殺成功了,落到B服務器的秒殺還沒開始,業務上也是可以接受的(用戶感知不到)
所以,大部分業務,長時間趨勢遞增的時序就能夠滿足業務需求,非常短時間的時序誤差一定程度上能夠接受。
關於絕對遞增id,趨勢遞增id的生成架構,詳見文章《細聊分布式ID生成方法》,此處不展開。
【利用單點序列化,可以保證多機相同時序】
數據為了保證高可用,需要做到進行數據冗余,同一份數據存儲在多個地方,怎麽保證這些數據的修改消息是一致的呢?利用的就是“單點序列化”:
(1)先在一臺機器上序列化操作
(2)再將操作序列分發到所有的機器,以保證多機的操作序列是一致的,最終數據是一致的
典型場景一:數據庫主從同步
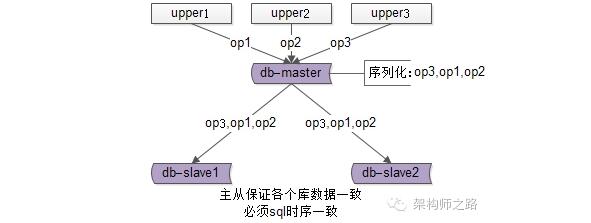
數據庫的主從架構,上遊分別發起了op1,op2,op3三個操作,主庫master來序列化所有的SQL寫操作op3,op1,op2,然後把相同的序列發送給從庫slave執行,以保證所有數據庫數據的一致性,就是利用“單點序列化”這個思路。
典型場景二:GFS中文件的一致性
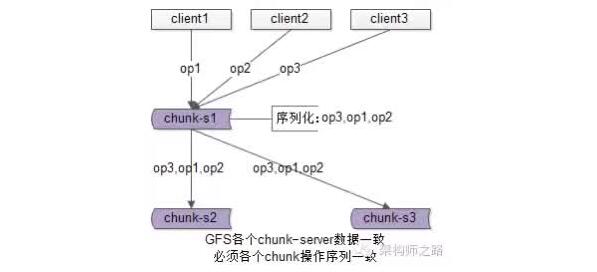
GFS(Google File System)為了保證文件的可用性,一份文件要存儲多份,在多個上遊對同一個文件進行寫操作時,也是由一個主chunk-server先序列化寫操作,再將序列化後的操作發送給其他chunk-server,來保證冗余文件的數據一致性的。
【單對單聊天,怎麽保證發送順序與接收順序一致】
單人聊天的需求,發送方A依次發出了msg1,msg2,msg3三個消息給接收方B,這三條消息能否保證顯示時序的一致性(發送與顯示的順序一致)?
回答:
(1)如果利用服務器單點序列化時序,可能出現服務端收到消息的時序為msg3,msg1,msg2,與發出序列不一致
(2)業務上不需要全局消息一致,只需要對於同一個發送方A,ta發給B的消息時序一致就行,常見優化方案,在A往B發出的消息中,加上發送方A本地的一個絕對時序,來表示接收方B的展現時序
msg1{seq:10, receiver:B,msg:content1 }
msg2{seq:20, receiver:B,msg:content2 }
msg3{seq:30, receiver:B,msg:content3 }
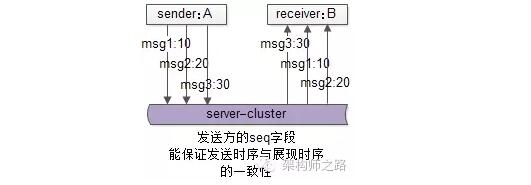
潛在問題:如果接收方B先收到msg3,msg3會先展現,後收到msg1和msg2後,會展現在msg3的前面。
無論如何,是按照接收方收到時序展現,還是按照服務端收到的時序展現,還是按照發送方發送時序展現,是pm需要思考的點,技術上都能夠實現(接收方按照發送時序展現是更合理的)。
總之,需要一桿標尺來衡量這個時序。
【群聊消息,怎麽保證各接收方收到順序一致】
群聊消息的需求,N個群友在一個群裏聊,怎麽保證所有群友收到的消息顯示時序一致?
回答:
(1)不能再利用發送方的seq來保證時序,因為發送方不單點,時間也不一致
(2)可以利用服務器的單點做序列化
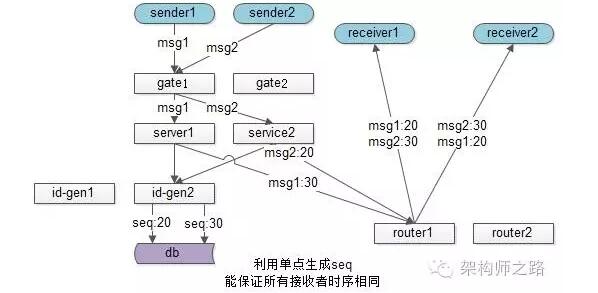
此時群聊的發送流程為:
(1)sender1發出msg1,sender2發出msg2
(2)msg1和msg2經過接入集群,服務集群
(3)service層到底層拿一個唯一seq,來確定接收方展示時序
(4)service拿到msg2的seq是20,msg1的seq是30
(5)通過投遞服務講消息給多個群友,群友即使接收到msg1和msg2的時間不同,但可以統一按照seq來展現
這個方法能實現,所有群友的消息展示時序相同。
缺點是,這個生成全局遞增序列號的服務很容易成為系統瓶頸,還有沒有進一步的優化方法呢?
思路:群消息其實也不用保證全局消息序列有序,而只要保證一個群內的消息有序即可,這樣的話,“id串行化”就成了一個很好的思路。
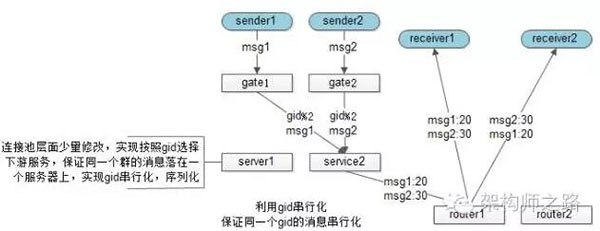
這個方案中,service層不再需要去一個統一的後端拿全局seq,而是在service連接池層面做細小的改造,保證一個群的消息落在同一個service上,這個service就可以用本地seq來序列化同一個群的所有消息,保證所有群友看到消息的時序是相同的。
關於id串行化的細節,可詳見《利用id串行化解決緩存與數據庫一致性問題》,此處不展開。
三、總結
(1)分布式環境下,消息的有序性是很難的,原因多種多樣:時鐘不一致,多發送方,多接收方,多線程,網絡傳輸不確定性等
(2)要“有序”,先得有衡量“有序”的標尺,可以是客戶端標尺,可以是服務端標尺
(3)大部分業務能夠接受大範圍趨勢有序,小範圍誤差;絕對有序的業務,可以借助服務器絕對時序的能力
(4)單點序列化,是一種常見的保證多機時序統一的方法,典型場景有db主從一致,gfs多文件一致
(5)單對單聊天,只需保證發出的時序與接收的時序一致,可以利用客戶端seq
(6)群聊,只需保證所有接收方消息時序一致,需要利用服務端seq,方法有兩種,一種單點絕對時序,另一種id串行化
1分鐘實現“延遲消息”功能
一、緣起
很多時候,業務有“在一段時間之後,完成一個工作任務”的需求。
例如:滴滴打車訂單完成後,如果用戶一直不評價,48小時後會將自動評價為5星。
一般來說怎麽實現這類“48小時後自動評價為5星”需求呢?
1. 常見方案:
啟動一個cron定時任務,每小時跑一次,將完成時間超過48小時的訂單取出,置為5星,並把評價狀態置為已評價。
假設訂單表的結構為:t_order(oid, finish_time, stars, status, …),更具體的,定時任務每隔一個小時會這麽做一次:
- select oid from t_order where finish_time > 48hours and status=0;
- update t_order set stars=5 and status=1 where oid in[…];
如果數據量很大,需要分頁查詢,分頁update,這將會是一個for循環。
2. 方案的不足:
(1)輪詢效率比較低
(2)每次掃庫,已經被執行過記錄,仍然會被掃描(只是不會出現在結果集中),有重復計算的嫌疑
(3)時效性不夠好,如果每小時輪詢一次,最差的情況下,時間誤差會達到1小時
(4)如果通過增加cron輪詢頻率來減少(3)中的時間誤差,(1)中輪詢低效和(2)中重復計算的問題會進一步凸顯
如何利用“延時消息”,對於每個任務只觸發一次,保證效率的同時保證實時性,是今天要討論的問題。
二、高效延時消息設計與實現
高效延時消息,包含兩個重要的數據結構:
- 環形隊列,例如可以創建一個包含3600個slot的環形隊列(本質是個數組)
- 任務集合,環上每一個slot是一個Set
同時,啟動一個timer,這個timer每隔1s,在上述環形隊列中移動一格,有一個Current Index指針來標識正在檢測的slot。
Task結構中有兩個很重要的屬性:
- Cycle-Num:當Current Index第幾圈掃描到這個Slot時,執行任務
- Task-Function:需要執行的任務指針
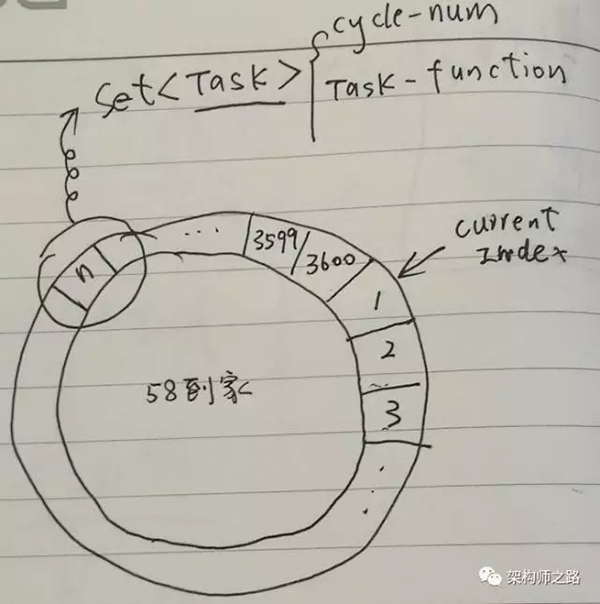
假設當前Current Index指向第一格,當有延時消息到達之後,例如希望3610秒之後,觸發一個延時消息任務,只需:
- 計算這個Task應該放在哪一個slot,現在指向1,3610秒之後,應該是第11格,所以這個Task應該放在第11個slot的Set中
- 計算這個Task的Cycle-Num,由於環形隊列是3600格(每秒移動一格,正好1小時),這個任務是3610秒後執行,所以應該繞3610/3600=1圈之後再執行,於是Cycle-Num=1
Current Index不停的移動,每秒移動到一個新slot,這個slot中對應的Set,每個Task看Cycle-Num是不是0:
- 如果不是0,說明還需要多移動幾圈,將Cycle-Num減1
- 如果是0,說明馬上要執行這個Task了,取出Task-Funciton執行(可以用單獨的線程來執行Task),並把這個Task從Set中刪除
使用了“延時消息”方案之後,“訂單48小時後關閉評價”的需求,只需將在訂單關閉時,觸發一個48小時之後的延時消息即可:
- 無需再輪詢全部訂單,效率高
- 一個訂單,任務只執行一次
- 時效性好,精確到秒(控制timer移動頻率可以控制精度)
三、總結
環形隊列是一個實現“延時消息”的好方法,開源的MQ好像都不支持延遲消息,不妨自己實現一個簡易的“延時消息隊列”,能解決很多業務問題,並減少很多低效掃庫的cron任務。
一、緣起
很多時候,業務有定時任務或者定時超時的需求,當任務量很大時,可能需要維護大量的timer,或者進行低效的掃描。
例如:58到家APP實時消息通道系統,對每個用戶會維護一個APP到服務器的TCP連接,用來實時收發消息,對這個TCP連接,有這樣一個需求:“如果連續30s沒有請求包(例如登錄,消息,keepalive包),服務端就要將這個用戶的狀態置為離線”。
其中,單機TCP同時在線量約在10w級別,keepalive請求包大概30s一次,吞吐量約在3000qps。
一般來說怎麽實現這類需求呢?
1. “輪詢掃描法”
1)用一個Map
2)當某個用戶uid有請求包來到,實時更新這個Map
3)啟動一個timer,當Map中不為空時,輪詢掃描這個Map,看每個uid的last_packet_time是否超過30s,如果超過則進行超時處理
2. “多timer觸發法”
1)用一個Map
2)當某個用戶uid有請求包來到,實時更新這個Map,並同時對這個uid請求包啟動一個timer,30s之後觸發
3)每個uid請求包對應的timer觸發後,看Map中,查看這個uid的last_packet_time是否超過30s,如果超過則進行超時處理
- 方案一:只啟動一個timer,但需要輪詢,效率較低
- 方案二:不需要輪詢,但每個請求包要啟動一個timer,比較耗資源
特別在同時在線量很大時,很容易CPU100%,如何高效維護和觸發大量的定時/超時任務,是本文要討論的問題。
二、環形隊列法
廢話不多說,三個重要的數據結構:
1)30s超時,就創建一個index從0到30的環形隊列(本質是個數組)
2)環上每一個slot是一個Set,任務集合
3)同時還有一個Map

同時:
1)啟動一個timer,每隔1s,在上述環形隊列中移動一格,0->1->2->3…->29->30->0…
2)有一個Current Index指針來標識剛檢測過的slot
1. 當有某用戶uid有請求包到達時:
1)從Map結構中,查找出這個uid存儲在哪一個slot裏
2)從這個slot的Set結構中,刪除這個uid
3)將uid重新加入到新的slot中,具體是哪一個slot呢 =>Current Index指針所指向的上一個slot,因為這個slot,會被timer在30s之後掃描到
(4)更新Map,這個uid對應slot的index值
2. 哪些元素會被超時掉呢?
Current Index每秒種移動一個slot,這個slot對應的Set中所有uid都應該被集體超時!如果最近30s有請求包來到,一定被放到Current Index的前一個slot了,Current Index所在的slot對應Set中所有元素,都是最近30s沒有請求包來到的。
所以,當沒有超時時,Current Index掃到的每一個slot的Set中應該都沒有元素。
3. 優勢:
(1)只需要1個timer
(2)timer每1s只需要一次觸發,消耗CPU很低
(3)批量超時,Current Index掃到的slot,Set中所有元素都應該被超時掉
三、總結
這個環形隊列法是一個通用的方法,Set和Map中可以是任何task,本文的uid是一個最簡單的舉例。
問:為什麽會有本文?
答:上一篇文章《到底什麽時候該使用MQ?》引起了廣泛的討論,有朋友回復說,MQ的還有一個典型應用場景是緩沖流量,削峰填谷,本文將簡單介紹下,MQ要實現什麽細節,才能緩沖流量,削峰填谷。
問:站點與服務,服務與服務上下遊之間,一般如何通訊?
答:有兩種常見的方式
一種是“直接調用”,通過RPC框架,上遊直接調用下遊。
在某些業務場景之下(具體哪些業務場景,見《到底什麽時候該使用MQ?》),可以采用“MQ推送”,上遊將消息發給MQ,MQ將消息推送給下遊。
問:為什麽會有流量沖擊?
答:不管采用“直接調用”還是“MQ推送”,都有一個缺點,下遊消息接收方無法控制到達自己的流量,如果調用方不限速,很有可能把下遊壓垮。
舉個栗子,秒殺業務:
上遊發起下單操作
下遊完成秒殺業務邏輯(庫存檢查,庫存凍結,余額檢查,余額凍結,訂單生成,余額扣減,庫存扣減,生成流水,余額解凍,庫存解凍)
上遊下單業務簡單,每秒發起了10000個請求,下遊秒殺業務復雜,每秒只能處理2000個請求,很有可能上遊不限速的下單,導致下遊系統被壓垮,引發雪崩。
為了避免雪崩,常見的優化方案有兩種:
1)業務上遊隊列緩沖,限速發送
2)業務下遊隊列緩沖,限速執行
不管哪種方案,都會引入業務的復雜性,有“緩沖流量”需求的系統都需要加入類似的機制(具體怎麽保證消息可達,見《消息總線能否實現消息必達?》),正所謂“通用痛點統一解決”,需要一個通用的機制解決這個問題。
問:如何緩沖流量?
答:明明中間有了MQ,並且MQ有消息落地的機制,為何不能利用MQ來做緩沖呢?顯然是可以的。
問:MQ怎麽改能緩沖流量?
答:由MQ-server推模式,升級為MQ-client拉模式。
MQ-client根據自己的處理能力,每隔一定時間,或者每次拉取若幹條消息,實施流控,達到保護自身的效果。並且這是MQ提供的通用功能,無需上下遊修改代碼。
問:如果上遊發送流量過大,MQ提供拉模式確實可以起到下遊自我保護的作用,會不會導致消息在MQ中堆積?
答:下遊MQ-client拉取消息,消息接收方能夠批量獲取消息,需要下遊消息接收方進行優化,方能夠提升整體吞吐量,例如:批量寫。
結論
1)MQ-client提供拉模式,定時或者批量拉取,可以起到削平流量,下遊自我保護的作用(MQ需要做的)
2)要想提升整體吞吐量,需要下遊優化,例如批量處理等方式(消息接收方需要做的)
58到家架構優化具備整體性,需要通用服務和業務方一起優化升級。
mq使用場景、不丟不重、時序性