
IBM服務器多塊硬盤離線數據恢復方法
需要進行數據恢復的是北京一家公司的IBM X3850服務器,服務器掛載了5塊73G SAS硬盤組成raid5磁盤陣列,4號盤為熱備盤(Hot-Spare),由於未知原因2號盤離線後未能成功激活熱備盤rebuild,後3號盤離線,RAID崩潰。
用戶服務器的操作系統為linux redhat 5.3,服務器存儲有oracle數據庫,因oracle已經不再對基於數據庫上的oa系統提供後續支持,用戶要求盡可能數據恢復+操作系統復原。
【數據恢復初檢結情況】
Raid陣列中硬盤無明顯物理故障,raid無同步表現。
【raid陣列數據恢復方案】
1、關閉服務器並確保數據恢復過程中保持服務器關閉狀態以保護故障服務器原始狀態。
3、將需要進行數據恢復的硬盤掛載至北亞數據恢復中心只讀環境中,對所有故障硬盤做完全鏡像(參考<如何對磁盤做完整的全盤鏡像備份>)。用於數據恢復操作使用。
4、分析備份磁盤的raid結構,得到原raid陣列的RAID級別,條帶規則,條帶大小,校驗方向,META區域等必要信息並根據這些信息搭建虛擬raid5環境。
5、解釋虛擬磁盤及文件系統,然後檢測虛擬結構的正確性,如果虛擬結構不正確則重復上述步驟,直到成功為止。
6、數據檢測正常後進行數據回遷,原則上不再使用原盤,如確實經客戶認可需要使用原盤則需要確認原盤已經完整備份後再重建raid、回遷數據。可以使用linux livecd或win pe(通常不支持)等進行,也可以在故障服務器上用另外硬盤安裝一個回遷用的操作系統,再進行扇區級別的回遷。
【恢復周期】
備份時間,約2小時。
解釋及導出數據時間,約4小時。
回遷操作系統,約4小時。
【數據恢復實施過程】
1、對用戶服務器進行鏡像後發現除2號盤有壞扇區存在,其他盤均無壞道,壞道數量悅遊20個左右。
2、分析結構:得到的最佳結構為0,1,2,3盤序,缺3號盤,塊大小512扇區,backward parity(Adaptec),結構如下圖:
圖一: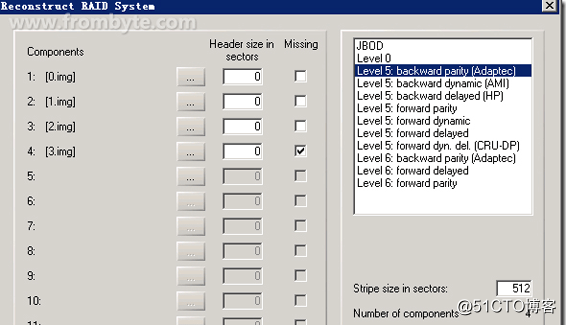
3、組好後數據驗證,200M以上的最新壓縮包進行測試性解壓查看有無報錯,確定結構是否正確,解壓正常,結構正確。直接按此結構生成虛擬RAID到一塊單硬盤上,打開文件系統無明顯報錯。
4、在對客戶原盤進行備份後重建raid陣列(將存在壞道的2號硬盤以新盤替換),連接恢復好的數據盤後通過“dd”命令進行全盤回寫操作。
【系統復原過程】
使用“dd”命令進行全盤回寫操作後啟動操作系統卻出現報錯:/etc/rc.d/rc.sysinit:Line 1:/sbin/pidof:Permission denied ,系統無法進入
工程師預判報錯原因為文件權限問題,於是用SystemRescueCd重啟後檢查文件時間、權限、大小均有明顯錯誤。
對數據中的根分區進行了重新分析,將出錯的/sbin/pidof定位出來發現問題的原因再於2號盤的壞道。。
通過沒有壞道的0號盤,1號盤,3號盤進行對2號盤的損壞區域xor補齊後校驗文件系統依然有錯誤,再一次對iNode表進行檢查發現2號盤損壞區域有部分節點表現為(圖中的55 55 55部分):
圖二:
問題顯而易見,節點中描述的uid還正常存在,但屬性,大小,以最初的分配塊均不正確。此種情況下是沒有辦法找回損壞的節點了,只能希望修復此節點,或復制一個相同的文件過來。對所有可能有錯的文件,均通過日誌確定原節點塊的節點信息,再做修正。
修正後重新dd根分區,執行fsck -fn /dev/sda5,進行檢測,依然有報錯,如下圖:
圖三: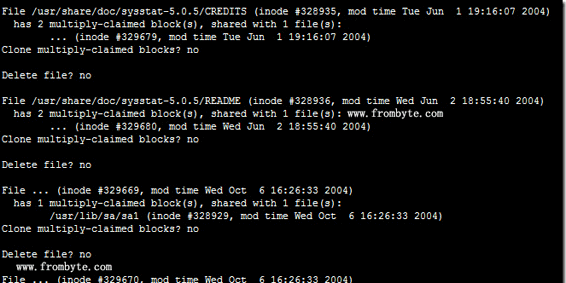
根據提示,在系統中發現有多個節點共用同樣的數據塊。按此提示進行底層分析,發現,因3號盤早掉線,幫存在節點信息的新舊交集。
按節點所屬的文件進行區別,清除錯誤節點後,再次執行fsck -fn /dev/sda5,依然有報錯信息,但已經很少。根據提示,發現這些節點多位於doc目錄下,不影響系統啟動,於是直接fsck -fy /dev/sda5強行修復。
修復後,重啟系統,成功進入桌面。
啟動數據庫服務,啟動應用軟件,一切正常,無報錯。
到此,數據恢復及系統回遷工作完成。
IBM服務器多塊硬盤離線數據恢復方法