
Python爬蟲入門 | 4 爬取豆瓣TOP250圖書信息


先來看看頁面長啥樣的:https://book.douban.com/top250
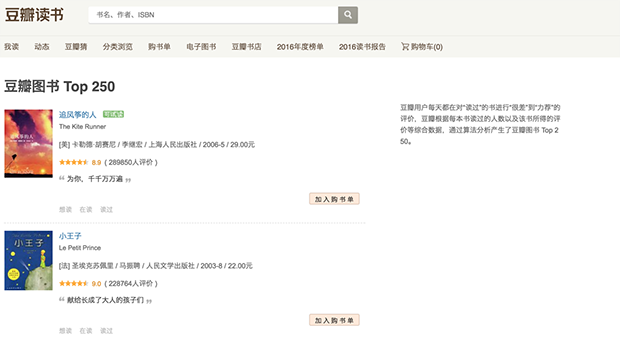
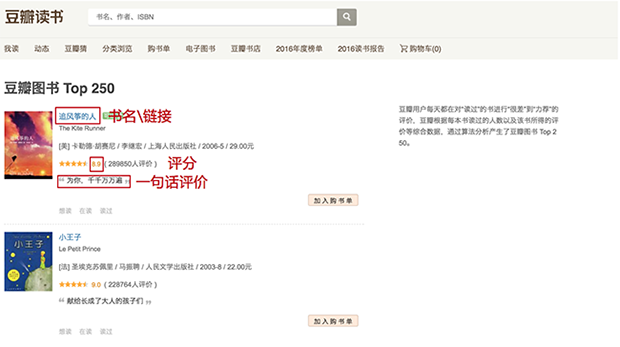
我們將要爬取哪些信息:書名、鏈接、評分、一句話評價……
1. 爬取單個信息
我們先來嘗試爬取書名,利用之前的套路,還是先復制書名的xpath:
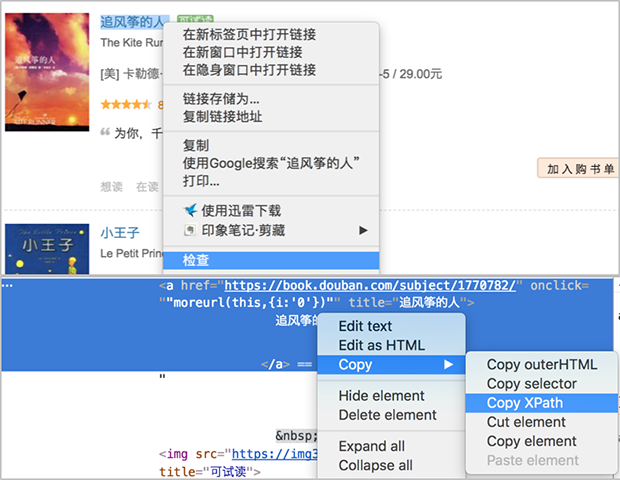
得到第一本書《追風箏的人》的書名xpath如下:
//*[@id="content"]/div/div[1]/div/table[1]/tbody/tr/td[2]/div[1]/a
得到xpath,我們就可以按照之前的方法來嘗試一下:
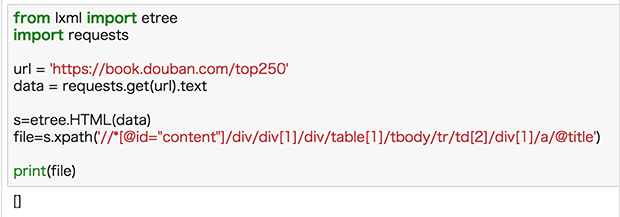
返回的竟然是空值,這就很尷尬了。
這裏需要註意,瀏覽器復制的 xpath 信息並不是完全可靠的,瀏覽器經常會自己在裏面增加多余的 tbody 標簽,我們需要手動把這些標簽刪掉。

修改 xpath 後再來嘗試,結果如下:
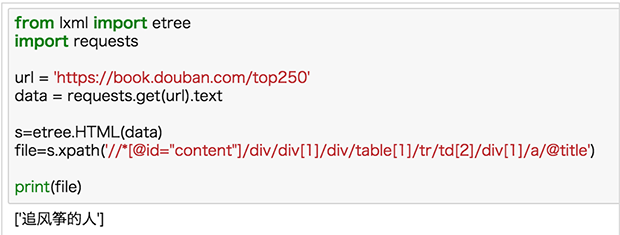
切記:瀏覽器復制 xpath 不是完全可靠,看到 tbody 標簽特別要註意。
分別復制《追風箏的人》、《小王子》、《圍城》、《解憂雜貨店》的 xpath 信息進行對比:
//*[@id="content"]/div/div[1]/div/table[1]/tbody/tr/td[2]/div[1]/a //*[@id="content"]/div/div[1]/div/table[2]/tbody/tr/td[2]/div[1]/a //*[@id="content"]/div/div[1]/div/table[3]/tbody/tr/td[2]/div[1]/a //*[@id="content"]/div/div[1]/div/table[4]/tbody/tr/td[2]/div[1]/a
比較可以發現書名的 xpath 信息僅僅 table 後的序號不一樣,並且跟書的序號一致,於是去掉序號(去掉 tbody),我們可以得到通用的 xpath 信息:
//*[@id=“content”]/div/div[1]/div/table/tr/td[2]/div[1]/a
好了,我們試試把這一頁全部書名爬下來:
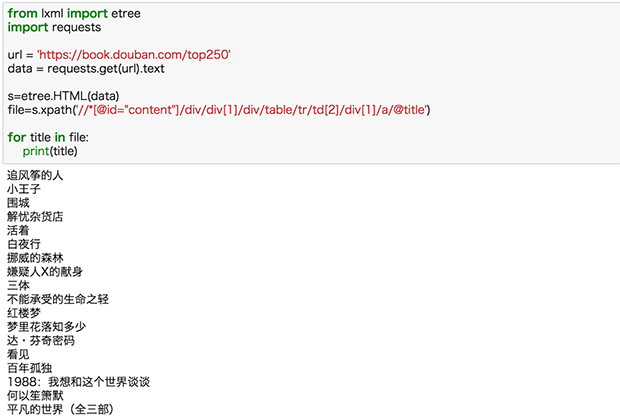
2.爬取多個信息

分別復制《追風箏的人》、《小王子》、《圍城》、《解憂雜貨店》評分的 xpath 信息進行對比:
//*[@id="content"]/div/div[1]/div/table[1]/tbody/tr/td[2]/div[2]/span[2] //*[@id="content"]/div/div[1]/div/table[2]/tbody/tr/td[2]/div[2]/span[2] //*[@id="content"]/div/div[1]/div/table[3]/tbody/tr/td[2]/div[2]/span[2] //*[@id="content"]/div/div[1]/div/table[4]/tbody/tr/td[2]/div[2]/span[2]
相信你已經可以秒寫出爬取全部評分的xpath了:
//*[@id=“content”]/div/div[1]/div/table/tr/td[2]/div[2]/span[2]
把評分的xpath放入之前的代碼,運行:
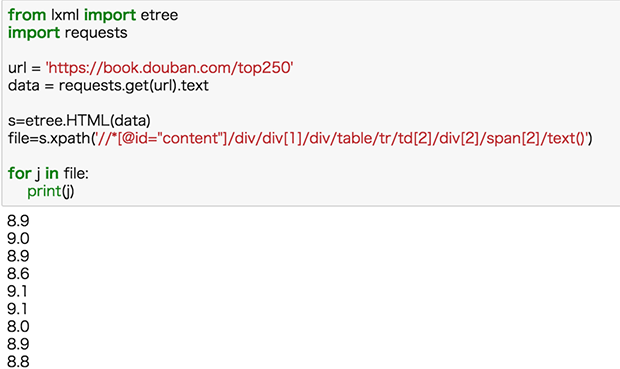
現在我們再把書名和評分同時爬取下來:
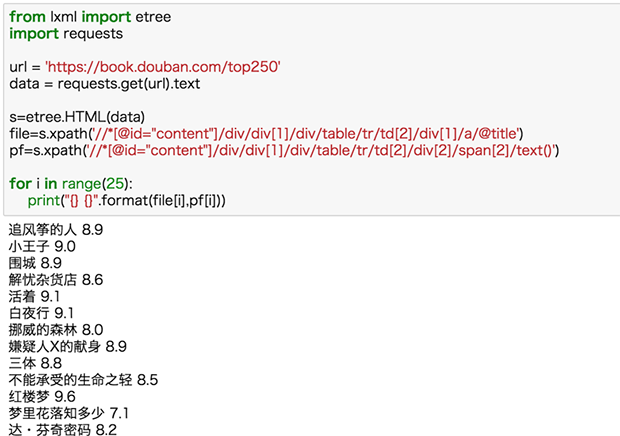
這裏我們默認書名和評分爬到的都是完全的、正確的信息,這種默認一般情況沒問題,但其實是有缺陷的,如果我們某一項少爬或多爬了信息,那麽兩種數據的量就不一樣了,從而匹配錯誤。比如下面的例子:
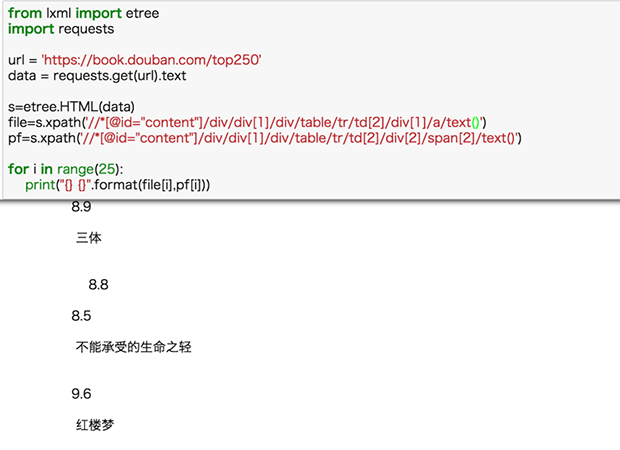
書名xpath 後的@title 改為 text(),獲取的文本數量與評分數量不一致,出現匹配錯位。
如果我們以每本書為單位,分別取獲取對應的信息,那肯定完全匹配。
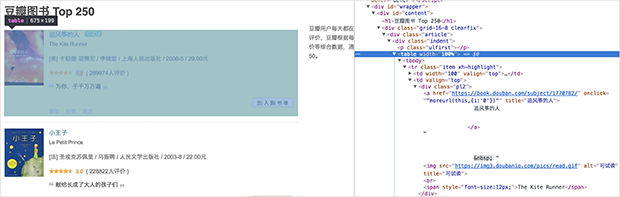
書名的標簽肯定在這本書的框架內,於是我們從書名的標簽向上找,發現覆蓋整本書的標簽(左邊網頁會有代碼包含內容的信息),把xpath 信息復制下來:
//*[@id="content"]/div/div[1]/div/table[1]
我們將整本書和書名的xpath進行對比
//*[@id=“content”]/div/div[1]/div/table[1] #整本書 //*[@id=“content”]/div/div[1]/div/table[1]/tr/td[2]/div[1]/a #書名 //*[@id=“content”]/div/div[1]/div/table[1]/tr/td[2]/div[2]/span[2] #評分
不難發現,書名和評分 xpath 的前半部分和整本書的 xpath 一致的,
那我們可以通過這樣寫 xpath 的方式來定位信息:
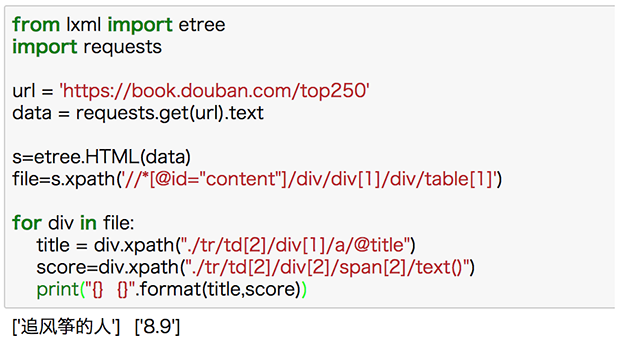
file=s.xpath(“//*[@id=“content”]/div/div[1]/div/table[1]”) title =div.xpath(“./tr/td[2]/div[1]/a/@title”) score=div.xpath(“./tr/td[2]/div[2]/span[2]/text()”)
在實際的代碼中來看一下:
剛剛我們爬了一本書的信息,那如何爬這個頁面所有書呢?很簡單啊,把 xpath 中<table>後面定位的序號去掉就ok。
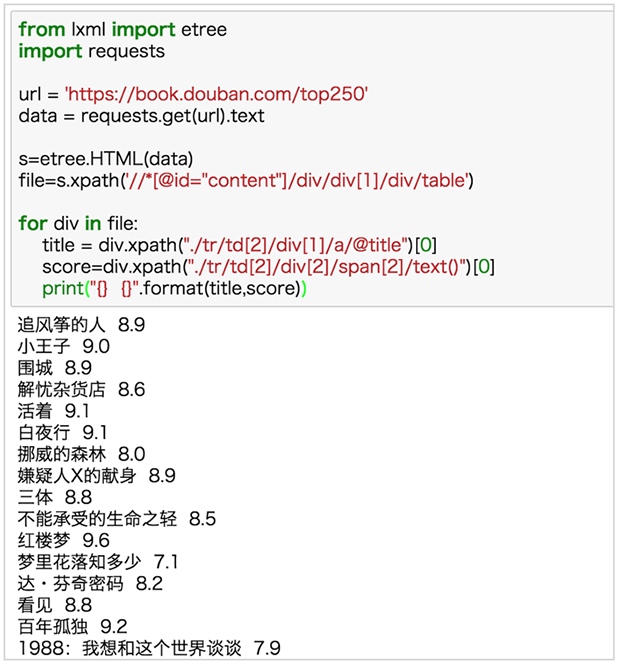
終於看到廬山真面目了,不過,等等~
title = div.xpath("./tr/td[2]/div[1]/a/@title")[0]
score=div.xpath("./tr/td[2]/div[2]/span[2]/text()")[0]為什麽這兩行後面多了個 [0] 呢?我們之前爬出來的數據是列表,外面帶個方框,看著非常難受,列表只有一個值,對其取第一個值就OK。如果不熟悉列表的知識,可以回去補補。
接下來就是按照這樣的方式多爬幾個元素啦!

有一個點需要註意的是:
num=div.xpath("./tr/td[2]/div[2]/span[3]/text()")[0].strip("(").strip().strip(")")這行代碼用了幾個 strip() 方法,()裏面表示要刪除的內容,strip(“(”) 表示刪除括號, strip() 表示刪除空白符。
嗯,已經把一個頁面搞定了,接下來需要,把所有頁面的信息都爬下來。
3.翻頁,爬取所有頁面信息
先來看一下翻頁後url是如何變化的:
https://book.douban.com/top250?start=0 #第一頁 https://book.douban.com/top250?start=25 #第二頁 https://book.douban.com/top250?start=50 #第三頁
url 變化的規律很簡單,只是 start=() 的數字不一樣而已,而且是以每頁25為單位,遞增25,這不正是每頁的書籍的數量嗎?於是,我們只需要寫一個循環就可以了啊。
for a in range(10):
url = 'https://book.douban.com/top250?start={}'.format(a*25)
#總共10個頁面,用 a*25 保證以25為單位遞增這裏要強調一下 Python range() 函數
基本語法:range(start, stop, step)
start:計數從 start 開始。默認是從 0 開始。例如 range(5) 等價於range(0,5);
end:計數到 end 結束,但不包括 end。例如:range(0,5)是 [0,1,2,3,4] 沒有5
step:步長,默認為1。例如:range(0,5) 等價於 range(0,5,1)
>>>range(10) #從 0 開始到 10 (不包含) [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] >>> range(1, 11) #從 1 開始到 11 (不包含) [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] >>> range(0, 30, 5) #從0到30(不包含),步長為5 [0, 5, 10, 15, 20, 25]
加上循環之後,完整代碼如下:
from lxml import etree
import requests
import time
for a in range(10):
url = 'https://book.douban.com/top250?start={}'.format(a*25)
data = requests.get(url).text
s=etree.HTML(data)
file=s.xpath('//*[@id="content"]/div/div[1]/div/table')
time.sleep(3)
for div in file:
title = div.xpath("./tr/td[2]/div[1]/a/@title")[0]
href = div.xpath("./tr/td[2]/div[1]/a/@href")[0]
score=div.xpath("./tr/td[2]/div[2]/span[2]/text()")[0]
num=div.xpath("./tr/td[2]/div[2]/span[3]/text()")[0].strip("(").strip().strip(")").strip()
scrible=div.xpath("./tr/td[2]/p[2]/span/text()")
if len(scrible) > 0:
print("{},{},{},{},{}\n".format(title,href,score,num,scrible[0]))
else:
print("{},{},{},{}\n".format(title,href,score,num))來運行一下:

請務必要自己練習幾遍,你覺得自己看懂了,還是會出錯,不信我們賭五毛錢。
Python 的基礎語法很重要,沒事的時候多去看看:字符串、列表、字典、元組、條件語句、循環語句……
編程最重要的是實戰,比如你已經能夠爬TOP250的圖書了,去試試TOP250電影呢。
好了,這節課就到這裏!

Python爬蟲入門 | 4 爬取豆瓣TOP250圖書信息