
[轉]攜程大數據實踐:高並發應用架構及推薦系統案例
本文來自攜程技術中心基礎業務研發部的《應用架構涅槃》系列分享。據基礎業務研發部負責人李小林介紹,互聯網二次革命的移動互聯網時代,如何吸引用戶、留住用戶並深入挖掘用戶價值,在激烈的競爭中脫穎而出,是各大電商的重要課題。通過各類大數據對用戶進行研究,以數據驅動產品是解決這個課題的主要手段,攜程的大數據團隊也由此應運而生;經過幾年的努力,大數據的相關技術為業務帶來了驚人的提升與幫助。以基礎大數據的用戶意圖服務為例,通過將廣告和欄位的“千人一面”變為“千人千面”,在提升用戶便捷性,可用性,降低費力度的同時,其轉化率也得到了數倍的提升,體現了大數據服務的真正價值。
在李小林看來,大數據是互聯網行業發展的趨勢,互聯網的從業人員需要高度關註大數據相關的技術及應用,也希望通過這一系列大數據相關的講座,讓各位同學有所收獲。
首場《應用架構涅磐》分享來自基礎業務研發部的董銳,包括業務高速發展帶來的應用架構挑戰、應對挑戰的架構涅磐、應用系統整體架構和推薦系統案例等四個部分。

一、業務高速發展帶來的應用架構挑戰
公司業務高速發展帶來哪些主要的變化,以及給我們的系統帶來了哪些挑戰?
- 業務需求的急速增長,訪問請求的並發量激增,2016年1月份以來,業務部門的服務日均請求量激增了5.5倍。
- 業務邏輯日益復雜化,基礎業務研發部需要支撐起OTA數十個業務線,業務邏輯日趨復雜和繁多。
- 業務數據源多樣化,異構化,接入的業務線、合作公司的數據源越來越多;接入的數據結構由以前的數據庫結構化數據整合轉為Hive表、評論文本數據、日誌數據、天氣數據、網頁數據等多元化異構數據整合。
- 業務的高速發展和叠代,部門一直以追求以最少的開發人力,以架構和系統的技術優化,支撐起攜程各業務線高速發展和叠代的需要。
在這種新形勢下,傳統應用架構不得不變,做為工程師也必然要自我涅槃,改為大數據及新的高並發架構,來應對業務需求激增及高速叠代的需要。計算分層分解、去SQL、去數據庫化、模塊化拆解的相關技改工作已經刻不容緩。
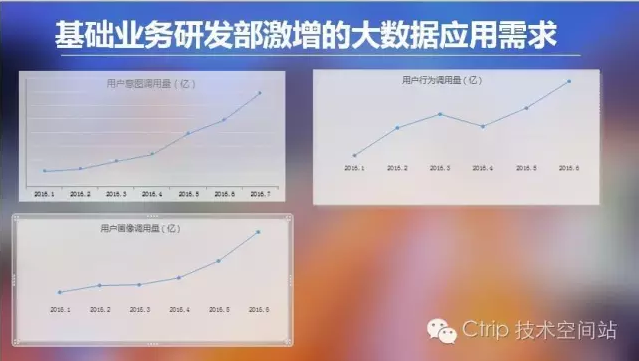
以用戶意圖(AI 點金杖)的個性化服務為例, 面對BU業務線的全面支持的迫切需要,其應用架構必須解決如下技術難點:
- 高訪問並發:每天近億次的訪問請求;
- 數據量大:每天TB級的增量數據,近百億條的用戶數據,上百萬的產品數據;
- 業務邏輯復雜:復雜個性化算法和LBS算法;例如:滿足一個復雜用戶請求需要大量計算和30次左右的SQL數據查詢,服務延時越來越長;
- 高速叠代上線:面對OTA多業務線的個性化、Cross-saling、Up-saling、需滿足提升轉化率的迫切需求,叠代欄位或場景要快速,同時減少研發成本。
二、應對挑戰的架構涅磐
面對這些挑戰,我們的應用系統架構應該如何涅磐?主要分如下三大方面系統詳解:
-
存儲的涅磐,這一點對於整個系統的吞吐量和並發量的提升起到最關鍵的作用,需要結合數據存儲模型和具體應用的場景。
-
計算的涅磐,可以從橫向和縱向考慮:橫向主要是增加並發度,首先想到的是分布式。縱向拆分就是要求我們找到計算的結合點從而進行分層,針對不同的層次選擇不同的計算地點。然後再將各層次計算完後的結果相結合,盡可能最大化系統整體的處理能力。
-
業務層架構的涅磐,要求系統的良好的模塊化設計,清楚的定義模塊的邊界,模塊自升級和可配置化。
三、應用系統的整體架構
認識到需要應對的挑戰,我們應該如何設計我們的系統呢,下面將全面的介紹下我們的應用系統整體架構。
下圖就是我們應用系統整體架構以及系統層次的模塊構成。
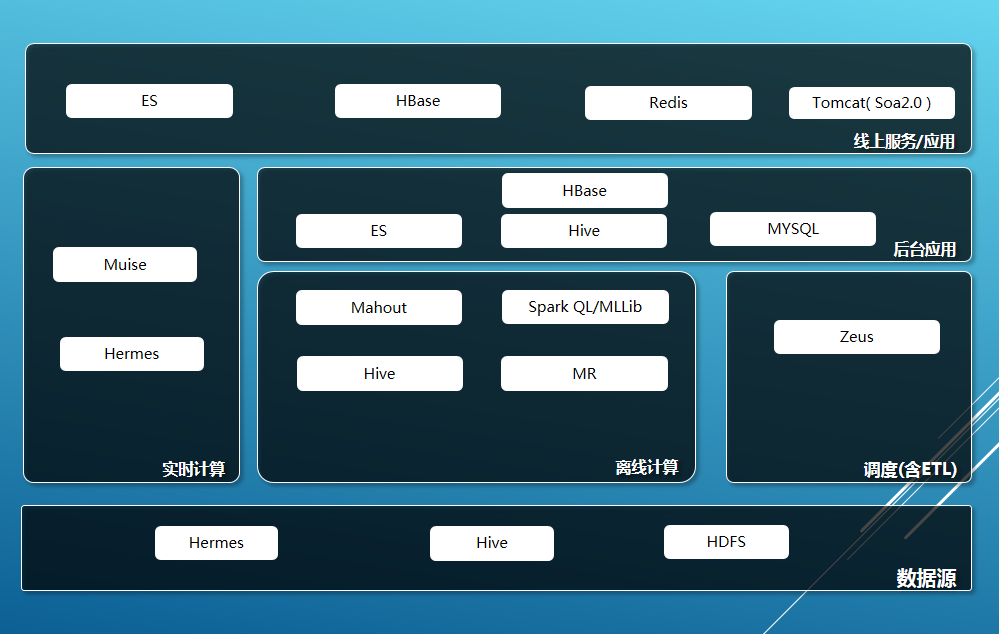
數據源部分,Hermes是攜程框架部門提供的消息隊列,基於Kafka和MySQL做為底層實現的封裝,應用於系統間實時數據傳輸交互通道。Hive和HDFS是攜程海量數據的主要存儲,兩者來自Hadoop生態體系。Hadoop大家已經很熟悉,如果不熟悉的同學只要知道Hadoop主要用於大數據量存儲和並行計算批處理工作。
Hive是基於Hadoop平臺的數據倉庫,沿用了關系型數據庫的很多概念。比如說數據庫和表,還有一套近似於SQL的查詢接口的支持,在Hive裏叫做HQL,但是其底層的實現細節和關系型數據庫完全不一樣,Hive底層所有的計算都是基於MR來完成,我們的數據工程師90%都數據處理工作都基於它來完成。
離線部分,包含的模塊有MR、Hive、Mahout、SparkQL/MLLib。Hive上面已經介紹過,Mahout簡單理解提供基於Hadoop平臺進行數據挖掘的一些機器學習的算法包。Spark類似hadoop也是提供大數據並行批量處理平臺,但是它是基於內存的。SparkQL 和Spark MLLib是基於Spark平臺的SQL查詢引擎和數據挖掘相關算法框架。我們主要用Mahout和Spark MLLib進行數據挖掘工作。
調度系統zeus,是淘寶開源大數據平臺調度系統,於2015年引進到攜程,之後我們進行了重構和功能升級,做為攜程大數據平臺的作業調度平臺。
近線部分,是基於Muise來實現我們的近實時的計算場景,Muise是也是攜程OPS提供的實時計算流處理平臺,內部是基於Storm實現與HERMES消息隊列搭配起來使用。例如,我們使用MUSIE通過消費來自消息隊列裏的用戶實時行為,訂單記錄,結合畫像等一起基礎數據,經一系列復雜的規則和算法,實時的識別出用戶的行程意圖。
後臺/線上應用部分,MySQL用於支撐後臺系統的數據庫。ElasticSearch是基於Lucene實現的分布式搜索引擎,用於索引用戶畫像的數據,支持離線精準營銷的用戶篩選,同時支持線上應用推薦系統的選品功能。HBase 基於Hadoop的HDFS 上的列存儲NoSQL數據庫,用於後臺報表可視化系統和線上服務的數據存儲。
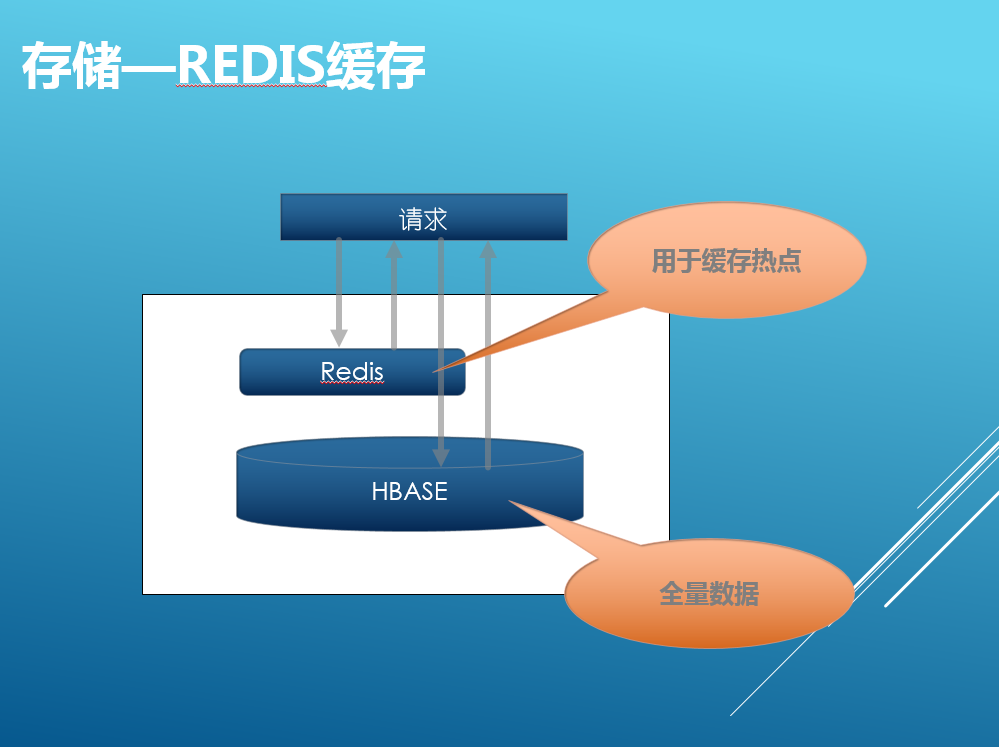
這裏說明一下, 在線和後臺應用使用的ElasticSearch和HBase集群是分開的,互不影響。Redis支持在線服務的高速緩存,用於緩存統計分析出來的熱點數據。
四、推薦系統案例
介紹完我們應用系統的整體構成,接下來分享基於這套系統架構實現的一個實例——攜程個性化推薦系統。
推薦系統的架構圖:
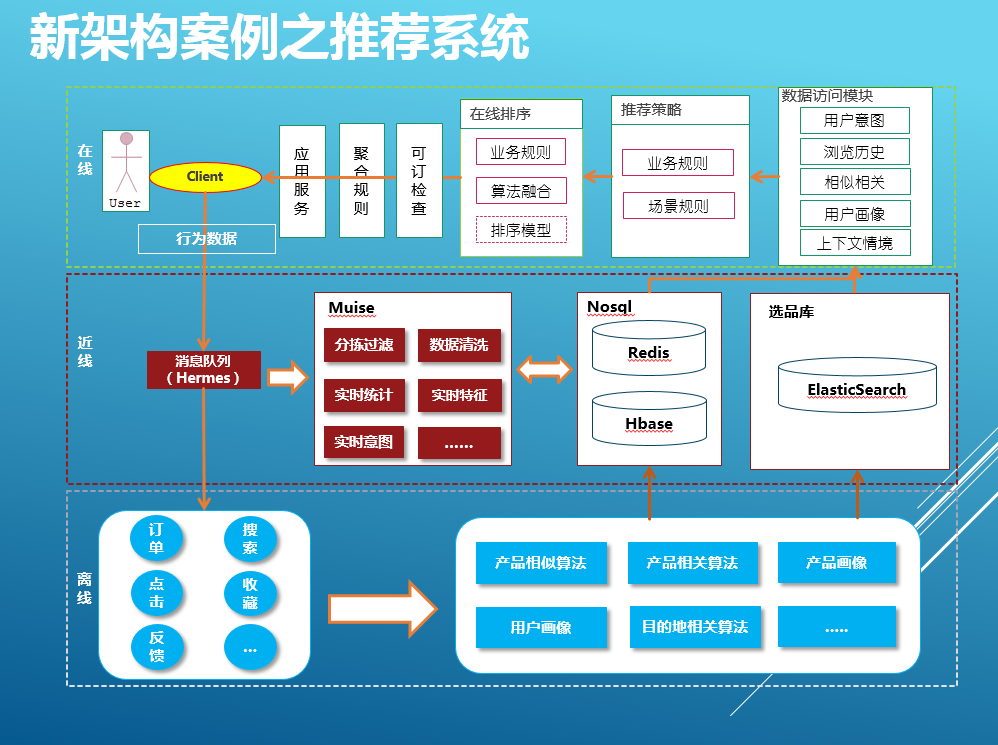
1、存儲的涅磐
1)NoSQL (HBase+Redis)

我們之前存儲使用的是MySQL,一般關系型數據庫會做為應用系統存儲的首選。大家知道MySQL非商業版對分布式支持不夠,在存儲數據量不高,查詢量和計算復雜度不是很大的情況下,可以滿足應用系統絕大部分的功能需求。
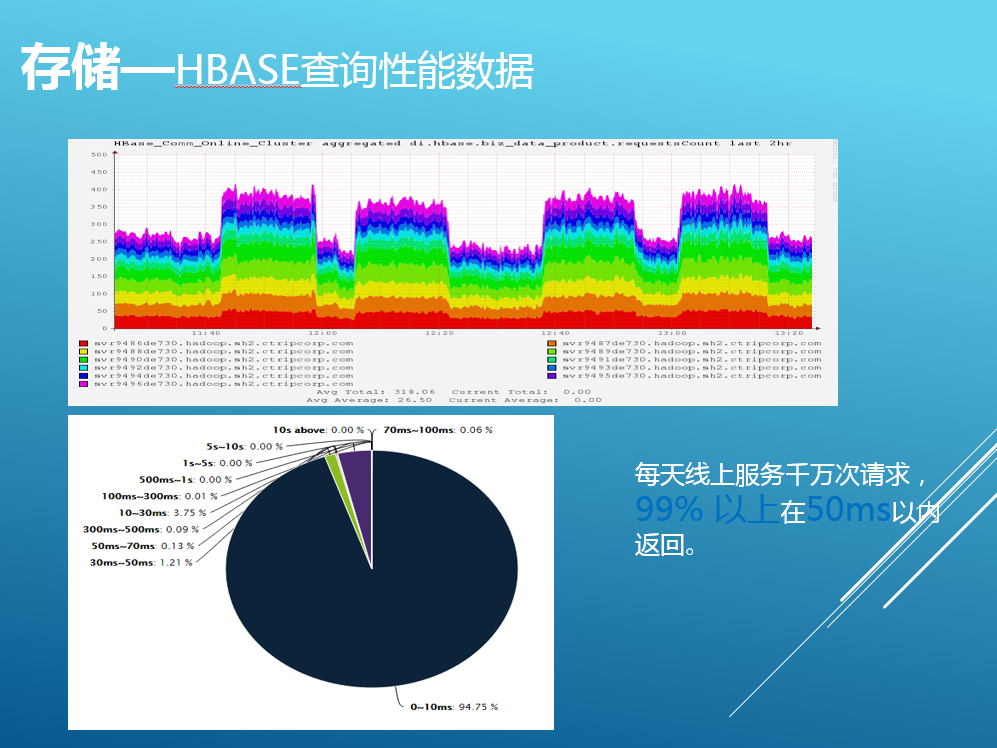
我們現狀是需要安全存儲海量的數據,高吞吐,並發能力強,同時隨著數據量和請求量的快速增加,能夠通過加節點來擴容。另外還需要支持故障轉移,自動恢復,無需額外的運維成本。綜上幾個主要因素,我們進行了大量的調研和測試,最終我們選用HBase和Redis兩個NoSQL數據庫來取代以往使用的MySQL。我們把用戶意圖以及推薦產品數據以KV的形式存儲在HBase中,我對操作HBase進行一些優化,其中包括rowkey的設計,預分配,數據壓縮等,同時針對我們的使用場景對HBase本身配置方面的也進行了調優。目前存儲的數據量已經達到TB級別,支持每天千萬次請求,同時保證99%在50毫秒內返回。
Redis和多數應用系統使用方式一樣,主要用於緩存熱點數據,這裏就不多說了。
2)搜索引擎 (ElasticSearch)
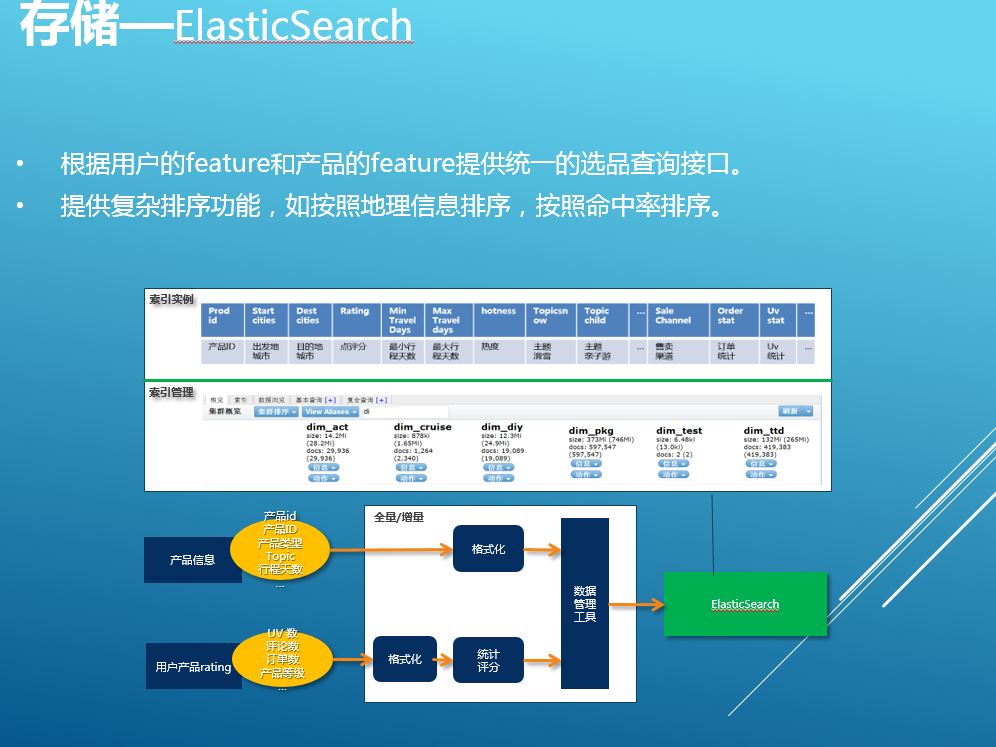
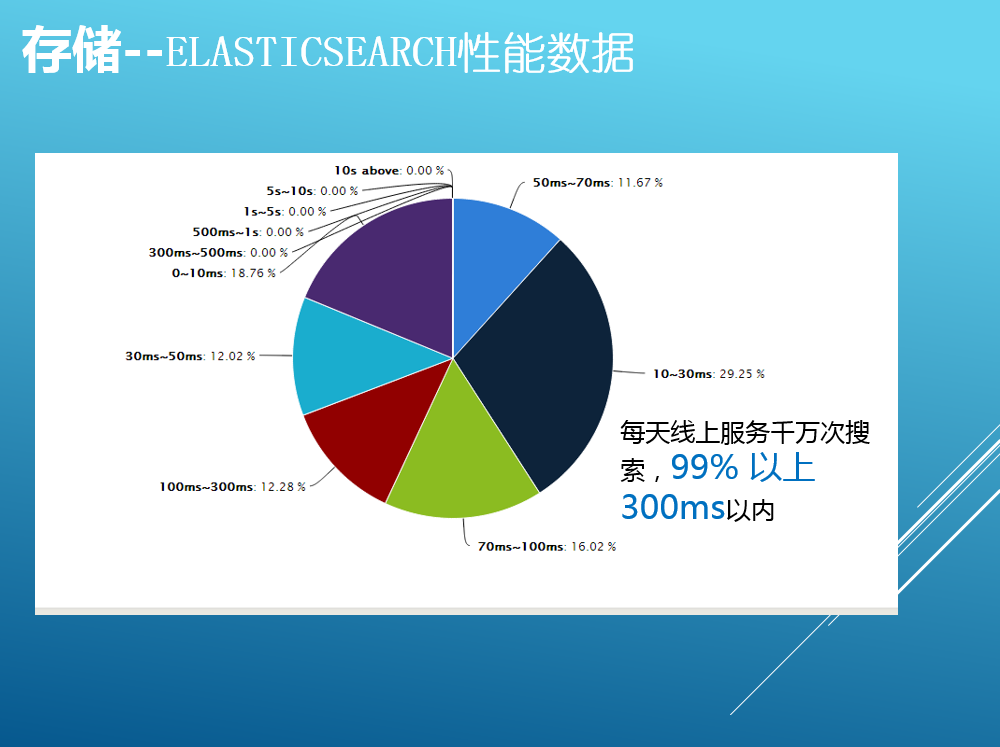
ES索引各業務線產品特征數據,提供基於用戶的意圖特征和產品特征復雜的多維檢索和排序功能,當前集群由4臺大內存物理機器構成,采用全內存索引。對比某一個復雜的查詢場景,之前用MySQL將近需要30次查詢,使用ES只需要一次組合查詢且在100毫秒內返回。目前每天千萬次搜索,99%以上在300毫秒以內返回。
2、計算的涅磐
1)數據源,我們的數據源分結構化和半結構化數據以及非結構化數據。

結構化數據主要是指攜程各產線的產品維表和訂單數據,有酒店、景酒、團隊遊、門票、景點等,還有一些基礎數據,比如城市表、車站等,這類數據基本上都是T+1,每天會有流程去各BU的生產表拉取數據。
半結構化數據是指,攜程用戶的訪問行為數據,例如瀏覽、搜索、預訂、反饋等,這邊順便提一下,這些數據這些是由前端采集框架實時采集,然後下發到後端的收集服務,由收集服務在寫入到Hermes消息隊列,一路會落地到Hadoop上面做長期存儲,另一路近線層可以通過訂閱Hermes此類數據Topic進行近實時的計算工作。
我們還用到外部合作渠道的數據,還有一些評論數據,評論屬於非結構化的,也是T+1更新。
2)離線計算,主要分三個處理階段。
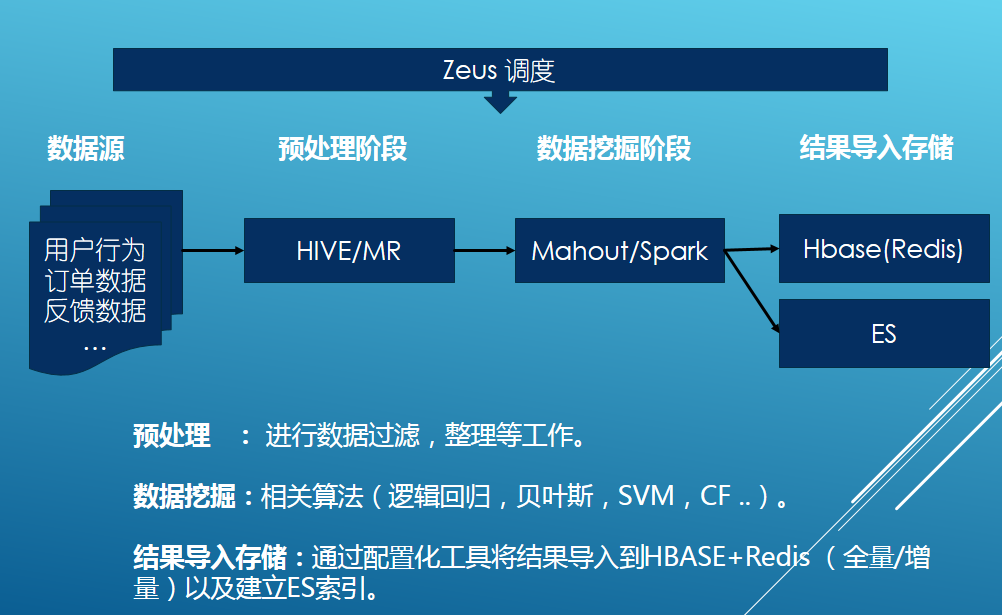
預處理階段,這塊主要為後續數據挖掘做一些數據的準備工作,數據去重,過濾,對缺失信息的補足。舉例來說采集下來的用戶行為數據,所含有的產品信息很少,我們會使用產品表的數據進行一些補足,確保給後續的數據挖掘使用時候盡量完整的。
數據挖掘階段,主要運用一些常用的數據挖掘算法進行模型訓練和推薦數據的輸出(分類、聚類、回歸、CF等)。
結果導入階段,我們通過可配置的數據導入工具將推薦數據,進行一系列轉換後,導入到HBase、Redis以及建立ES索引,Redis存儲的是經統計計算出的熱點數據。
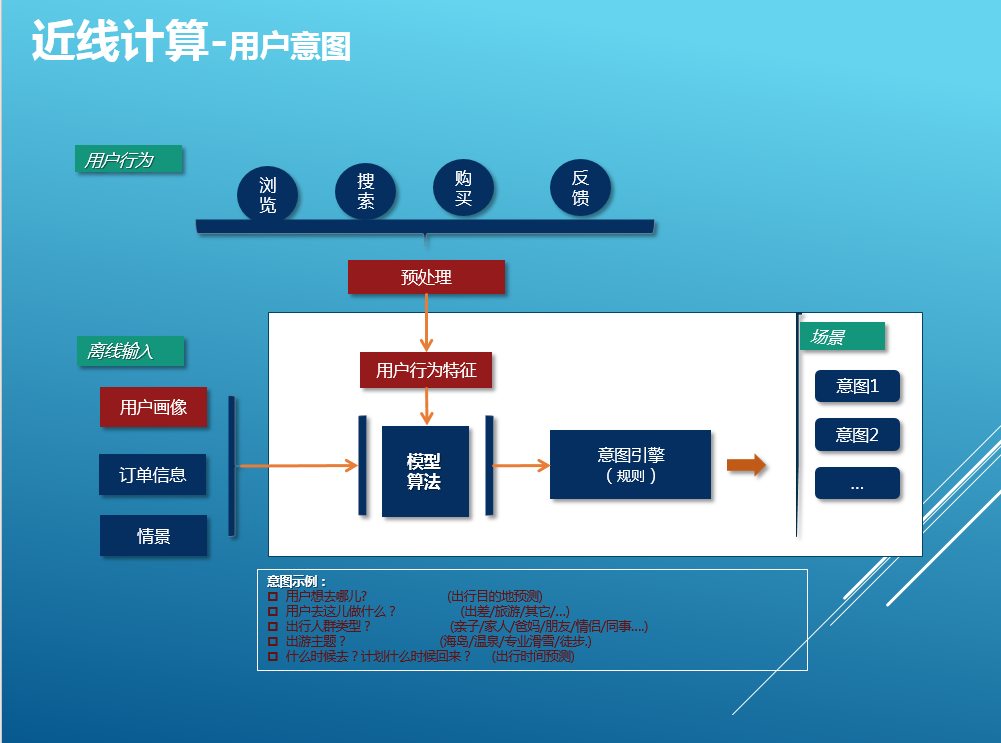
3)近線計算(用戶意圖、產品緩存)
當用戶沒有明確的目的性情況下,很難找到滿足興趣的產品,我們不僅需要了解用戶的歷史興趣,用戶實時行為特征的抽取和理解更加重要,以便快速的推薦出符合用戶當前興趣的產品,這就是用戶意圖服務需要實現的功能。
一般來說用戶特征分成兩大類:一種是穩定的特征(用戶畫像),如用戶性別、常住地、主題偏好等特征;另一類是根據用戶行為計算獲取的特征,如用戶對酒店星級的偏好、目的地偏好、跟團遊/自由行偏好等。基於前面所述的計算的特點,我們使用近在線計算來獲取第二類用戶特征,整體框圖如下。從圖中可以看出它的輸入數據源包括兩大類:第一類是實時的用戶行為;第二類是用戶畫像,歷史交易以及情景等離線模塊提供的數據。結合這兩類數據,經一些列復雜的近線學習算法和規則引擎,計算得出用戶當前實時意圖列表存儲到HBase和Redis中。
近線另一個工作是產品數據緩存,攜程的業務線很多,而我們的推薦系統會推各個業務線的產品,因此我們需要調用所有業務線的產品服務接口,但隨著我們上線的場景的增加,這樣無形的增加了對業務方接口的調用壓力。而且業務線產品接口服務主要應用於業務的主流程或關鍵型應用,比較重,且SLA服務等級層次不齊,可能會影響到整個推薦系統的響應時間。
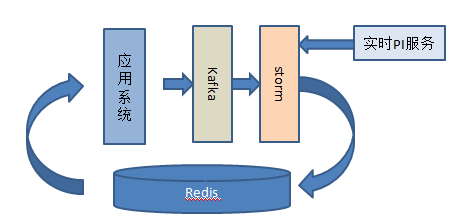
為了解決這兩個問題,我們設計了近在線計算來進行業務的產品信息異步緩存策略,具體的流程如下。
我們會將待推薦的產品Id全部通過Kafka異步下發,在Storm中我們會對各業務方的產品首先進行聚合,達到批處理個數或者時間gap時,再調用各業務方的接口,這樣減少對業務方接口的壓力。通過調用業務方接口更新的產品狀態臨時緩存起來(根據各業務產品信息更新周期分別設置緩存失效時間),在線計算的時候直接先讀取臨時緩存數據,緩存不存在的情況下,再擊穿到業務的接口服務。
4)在線計算(2個關鍵業務層架構模塊介紹)
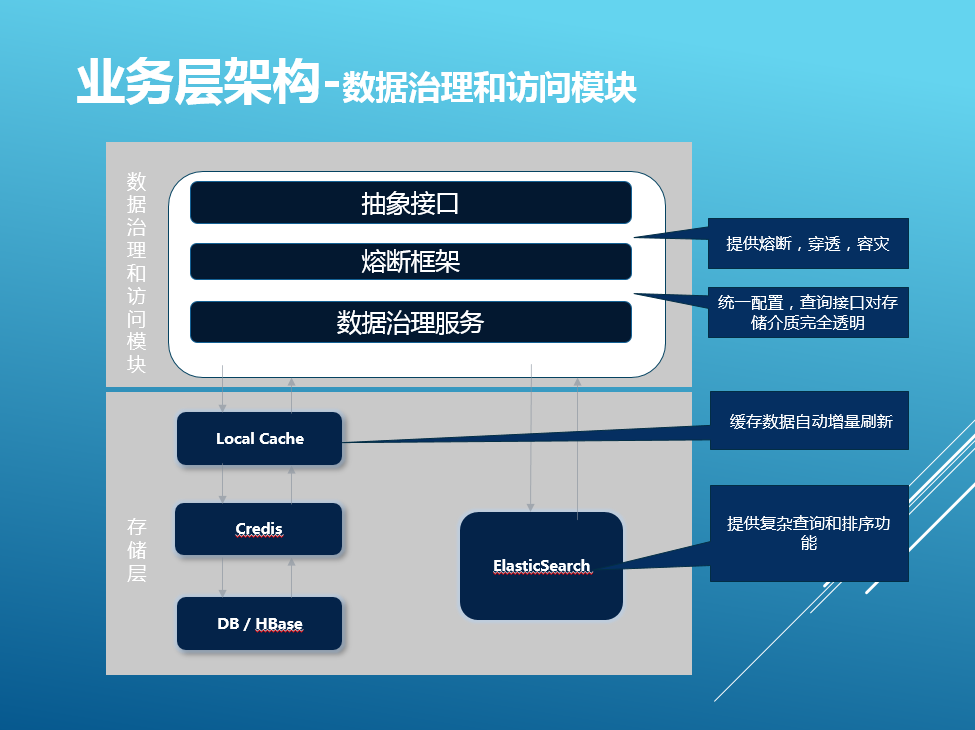
①業務層架構-數據治理和訪問模塊,支持的存儲介質,目前支持的存儲介質有Localcache、Redis、HBase、MySQL可以支持橫向擴展。統一配置,對同一份數據,采用統一配置,可以隨意存儲在任意介質,根據id查詢返回統一格式的數據,對查詢接口完全透明。
穿透策略和容災策略,Redis只存儲了熱數據,當需要查詢冷數據則可以自動到下一級存儲如HBase查詢,避免緩存資源浪費。當Redis出現故障時或請求數異常上漲,超過整體承受能力,此時服務降級自動生效,並可配置化。
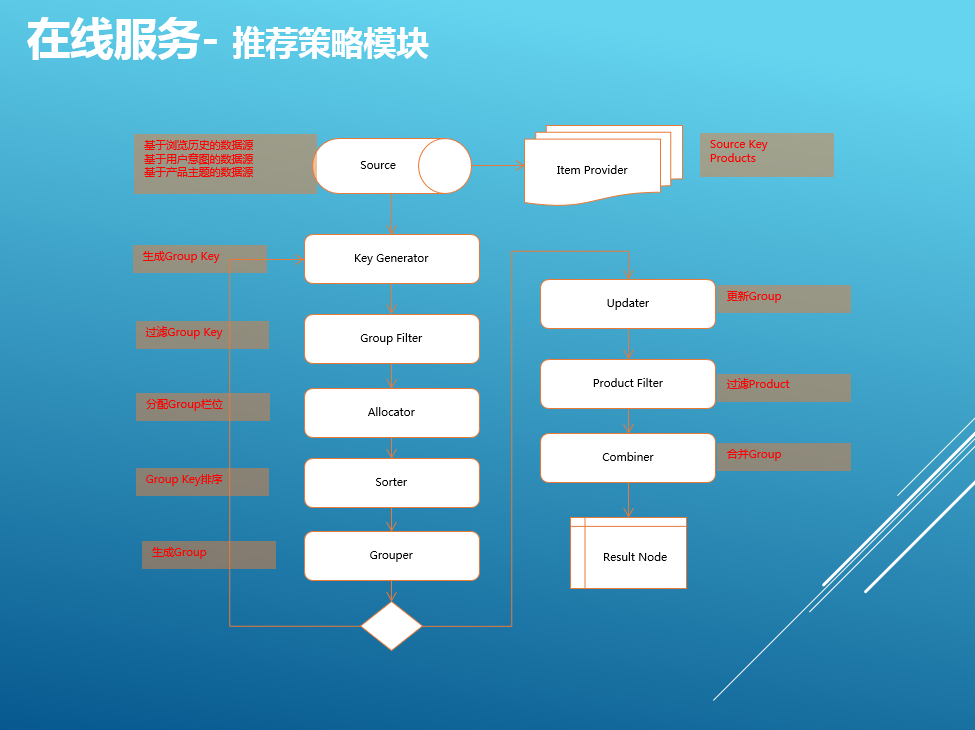
②業務層架構-推薦策略模塊,整個流程是先將用戶意圖、用戶瀏覽,相關推薦策略生成的產品集合等做為數據輸入,接著按照場景規則,業務邏輯重新過濾,聚合、排序。最後驗證和拼裝業務線產品信息後輸出推薦結果;
我們對此流程每一步進行了一些模塊化的抽象,將重排序邏輯按步驟抽象解耦,抽象如右圖所示的多個組件,開發新接口時僅需要將內部DSL拼裝便可以得到滿足業務需求的推薦服務;提高了代碼的復用率和可讀性,減少了超過50%的開發時間;對於充分驗證的模塊的復用,有效保證了服務的質量。
[轉]攜程大數據實踐:高並發應用架構及推薦系統案例