
2018年企業運維開發經典面試題
負責DevOps業務線項目的實施交付工作
負責idc機房、私有雲、公有雲的私有化部署工作
負責公司產品的測試、生產環境搭建、維護
完善各環境中服務穩定性、監控、日誌、部署、安全等需求
?
?【任職要求】
計算機相關專業本科畢業,2年以上的工作經驗
深入理解Linux操作系統、體系結構
優秀的腳本語言的開發能力(bash,python)
熟悉常用的持續集成工具(例如Jenkins等)
熟悉Linux操作系統,熟悉常用的CentOS/Ubuntu/RedHat,熟悉網絡知識
熟悉Linux下常用的應用集群、高可用和負載均衡技術
熟練使用常見開源監控工具者優先,如zabbix、Nagios、elk等
熟練使用常見關系型數據庫Mysql、Postgresql,或Nosql數據庫
熟悉Redis 相關原理及高可用的最佳實踐
熟練使用阿裏雲、aws、騰訊雲相關產品
熟練掌握docker相關知識
掌握git相關原理,github,gitlab
具備紮實的系統集成和運維技術能力
認同DevOps文化,認同“Automate Everything You Can”的原則,在開源社群活躍並有積極貢獻者優先。
有技術熱情和探索精神,有較強的快速學習能力和自驅能力,有良好的全局意識和系統風險識別能力
具備良好的英文閱讀能力和快速學習能力
可以接受臨時的出差工作
積極主動、責任心強、現場協調能力強、富有團結精神;有人際溝通能力和團隊合作能力;性格開朗外向,做事認真細致,有責任感和風險意識;;
【加分項】
有微服務相關使用經驗
有kafka、elk相關使用經驗
有springcloud、nodejs 微服務部署相關經驗
有Docker/k8s/Mesos/Swarm生產環境的使用經驗
阿裏雲/aws 命令行工具的開發使用經驗
有海量設備監控系統/自動化平臺/服務管理/自動化部署/日誌收集等系統開發設計經驗
面試題如下:




1、描述Hbase中scan和get的功能以及實現的異同
HBase的查詢實現只提供兩種方式: 1、按指定RowKey獲取唯一一條記錄,get方法(org.apache.hadoop.hbase.client.Get) 2、按指定的條件獲取一批記錄,scan方法(org.apache.hadoop.hbase.client.Scan) 實現條件查詢功能使用的就是scan方式
2、redis的並發競爭問題如何解決
方案一:可以使用獨占鎖的方式,類似操作系統的mutex機制。(網上有例子,http://blog.csdn.net/black_ox/article/details/48972085 不過實現相對復雜,成本較高)
方案二:使用樂觀鎖的方式進行解決(成本較低,非阻塞,性能較高)
3、為什麽redis需要把所有數據放到內存中
redis為了達到最快的讀寫速度將數據都讀到內存中,並通過異步的方式將數據寫入磁盤。所以redis具有快速和持久化的特征。如果不將數據放在內存中,磁盤I/O速度會嚴重影響redis的性能。如果使用了最大使用的內存,則數據已有記錄數達到內存限值後不能繼續插入新值。
4、redis支持的數據類型
Redis支持五種數據類型:string(字符串),hash(哈希),list(列表),set(集合)及zset(sorted set:有序集合)。
5、處理中文時出現錯誤‘ascil’ codec can‘t decode byte 0xe9 in position 0:ordinal not in range(128) 解決辦法“UnicodeDecodeError”:‘ascli‘ codec decode byte 0xe9 in posttion 0:ordinal not in range(128)
解決辦法,在該python文件的前面加上如下幾句,問題得到解決。
import sys
default_encoding = ‘utf-8‘
if sys.getdefaultencoding() != default_encoding:
reload(sys)
sys.setdefaultencoding(default_encoding)
6、python裏面match()和search()的區別
match()函數只檢測RE是不是在string的開始位置匹配,search()會掃描整個string查找匹配;
也就是說match()只有在0位置匹配成功的話才有返回,如果不是開始位置匹配成功的話,match()就返回none。
例如:
print(re.match(‘super‘, ‘superstition‘).span()) 會返回(0, 5)
而print(re.match(‘super‘, ‘insuperable‘)) 則返回None
search()會掃描整個字符串並返回第一個成功的匹配:
例如:print(re.search(‘super‘, ‘superstition‘).span())返回(0, 5)
print(re.search(‘super‘, ‘insuperable‘).span())返回(2, 7)
其中span函數定義如下,返回位置信息:
span([group]):
返回(start(group), end(group))。
7、python裏面如何實現tuple和list的轉換
Python中,tuple和list均為內置類型,
以list作為參數將tuple類初始化,將返回tuple類型
tuple([1,2,3]) #list轉換為tuple
以tuple作為參數將list類初始化,將返回list類型
list((1,2,3)) #tuple轉換為list
8、請寫出一段python代碼實現刪除一個list裏面的重復元素
我寫的代碼:
list1 = [5,1,3,1,6,2,3]
list2 = []
for i in list1:
if i not in list2:
list2.append(i)
else:
continue
list1=list2
網上給出的答案:
for i in list1:
if i not in list2:
list2.append(i)
else:
continue
9、如何批量刪除或者停止運行的容器
docker rm -f $(docker ps -a)
10、docker本地鏡像文件放在哪
/var/lib/docker
11、構建docker鏡像應該遵循哪些規則
整體原則上,盡量保持鏡像功能的明確和內容的精簡,要點包括:
盡量選取滿足需求但較小的基礎系統鏡像,例如docker.io/centos7
清理編譯生成文件、安裝包的緩存等臨時文件
安裝各個軟件是要指定準確的版本號,並避免引入不需要的依賴
應用盡量使用系統的庫和依賴
使用dockerfile創建鏡像時要添加.dockerignore文件或使用幹凈的工作目錄
12、容器退出後,通過docker ps 命令查不到,數據會丟失嗎
不會
13、docker查看日誌
docker logs -f 容器id
14、如何控制容器占用系統資源(cpu、內存)的份額
:在使用 docker create 命令創建容器或使用 docker run 創建並啟動容器的時候,可以使用 -c|--cpu-shares[=0] 參數來調整容器使用 CPU 的權重;使用 -m|--memory[=MEMORY] 參數來調整容器使用內存的大小。
15、如何根據容器的名字列出容器狀態
docker status 容器id
16、docker與LXC有何不同
lxc 是 Linux 內核容器虛擬化的一項技術,可以實現資源的隔離和控制,也就是對 Cgroup 和 Namespace 兩個屬性的控制。對於 docker 而言,它發展到現在不僅僅是容器的代名詞了,不過它的基礎技術是需要依賴內核的 Cgroup 和 Namespace 特性。docker 出現之初,便是采用了 lxc 技術作為 docker 底層,對容器虛擬化的控制。後來隨著 docker 的發展,它自己封裝了 libcontainer (golang 的庫)來實現 Cgroup 和 Namespace 控制,從而消除了對 lxc 的依賴。總結一下,lxc 是早期版本 docker 的一個基礎組件,docker 主要用到了它對 Cgroup 和 Namespace 兩個內核特性的控制。
17、docker與Vagrant有何不同
Vagrant適合用來管理虛擬機,而docker適合用來管理應用環境。
18、開發環境中docker與vagrant如何選擇
Docker是應用執行環境,不是虛擬機,對於宿主來說只是個隔離的進程;而Vagrant是虛擬機輔助軟件,使用Vagrant既使用虛擬機,因此所運行的是一個完整操作系統。這是最本質的區別。
Docker運行需要依托Linux內核,因此對於Windows, OSX系統而言,需要有一個Linux虛擬機運行起來,才可以使用Docker。因此在這種環境下,從單一虛擬機角度來說,Docker和Vagrant沒有占用資源的差別。對於 Linux工作環境來說,那就沒有這個問題,使用Docker要比Vagrant輕量級很多。
而在OSX, Windows下使用Docker和Vagrant開發,很重要的一個問題在於共享文件目錄上。之前大家在這兩個系統上安裝的Docker環境都是通過Docker Toolbox ( https://docs.docker.com/toolbox/overview/ )來安裝配置的,它使用的是Virtualbox,對於共享主機文件目錄到Docker環境上有一些問題,大多數情況能用,但是部分情況會出故障。所以相對於 Docker Toolbox的環境而言,如果需要一些文件目錄監控等高級功能,vagrant更適合開發。
但是,這個問題現在已經解決,Docker剛剛發布了Docker for Mac/Windows (beta) (https://docs.docker.com/docker-for-mac/),這將不在使用Virtualbox,而是使用 xhype (OSX), Hyper-V (Windows 10) 來運行一個更為精簡的Linux (Alpine)。由於使用了操作系統原生虛擬框架,因此共享目錄上的種種問題得到了解決,此外 Alpine 的使用,讓Linux虛擬機加載更為迅速。所以在這種情況下,使用 Docker 要比 Vagrant 有更多的優勢。
所以,從未來角度看,Docker是大勢所趨。
19、salt minion配置文件的默認路徑
/etc/salt/minion
20、如何手動刷新pillar
在master端定義,指定給對應的minion。可以使用saltuitl.refresh_pillar刷新。
21、介紹下salt的反射系統
略
22、寫一個腳本,判斷192.168.1.0/24網絡裏,當前在線ip有哪些
#!/bin/bash
for ip in seq 1 255
do
{
ping -c 1 192.168.1.$ip > /dev/null 2>&1
if [ $? -eq 0 ]; then
echo 192.168.1.$ip UP
else
echo 192.168.1.$ip DOWN
fi
}&
done
wait
23、描述linux運行級別0-6的含義
0:關機
1:單用戶模式
2:無網絡支持的多用戶模式
3:有網絡支持的多用戶模式(文本模式,工作中最常使用的模式)
4:保留,未使用
5:有網絡支持有X-Window支持的多用戶模式
6:重新引導系統,即重啟
24、linux開機過程
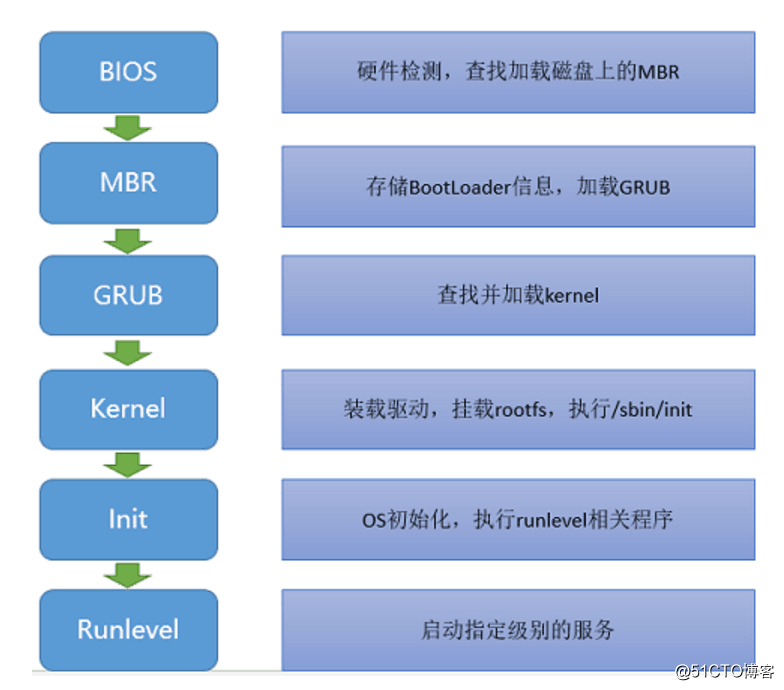
25、修改內核如何生效
source /etc/profile
26、Django中想驗證表單提交是否格式正確需要用到Form中哪個函數
is_valid()函數方法,用於檢查表單提交是否正確。
27、Django中如何讀取和保存session,整個session的運行機制是什麽
說到session的運行機制,就一定要先說一下cookie這一段信息。一般情況下cookies都是我們的瀏覽器生成的(顯然可以人為修改),用於服務器對戶進行篩選和維護,但是這個聽上去很好吃的東西,能存的東西有點少而且容易被別人利用。這時候基於cookies的session的意義就比較明顯了,在客戶端的cookies中我們只保存session id,而將完整信息以加密信息的形式保存到服務器端,這樣服務器可以根據session id相對安全的在數據庫中查詢用戶的更細致的信息和狀態。
28、kafka查看指定topic信息
bin/kafka-topics.sh --zookeeper node01:2181 --describe --topic t_cdr
29、git初始化和更新子模塊
git submodule init 初始化子模塊
git submodule update 更新子模塊
30、ubuntu搜索可用包
apt-cache search package-name
31、在10.0.0.8/8中劃分出3個子網,保證每個子網有4089個私有ip
略,本人不太精通子網劃分
32、ip報文格式
版本:IP協議的版本,目前的IP協議版本號為4,下一代IP協議版本號為6。
首部長度:IP報頭的長度。固定部分的長度(20字節)和可變部分的長度之和。共占4位。最大為1111,即10進制的15,代表IP報頭的最大長度可以為15個32bits(4字節),也就是最長可為15*4=60字節,除去固定部分的長度20字節,可變部分的長度最大為40字節。
服務類型:Type Of Service。
總長度:IP報文的總長度。報頭的長度和數據部分的長度之和。
標識:唯一的標識主機發送的每一分數據報。通常每發送一個報文,它的值加一。當IP報文長度超過傳輸網絡的MTU(最大傳輸單元)時必須分片,這個標識字段的值被復制到所有數據分片的標識字段中,使得這些分片在達到最終目的地時可以依照標識字段的內容重新組成原先的數據。
標誌:共3位。R、DF、MF三位。目前只有後兩位有效,DF位:為1表示不分片,為0表示分片。MF:為1表示“更多的片”,為0表示這是最後一片。
片位移:本分片在原先數據報文中相對首位的偏移位。(需要再乘以8)
生存時間:IP報文所允許通過的路由器的最大數量。每經過一個路由器,TTL減1,當為0時,路由器將該數據報丟棄。TTL 字段是由發送端初始設置一個 8 bit字段.推薦的初始值由分配數字 RFC 指定,當前值為 64。發送 ICMP 回顯應答時經常把 TTL 設為最大值 255。
協議:指出IP報文攜帶的數據使用的是那種協議,以便目的主機的IP層能知道要將數據報上交到哪個進程(不同的協議有專門不同的進程處理)。和端口號類似,此處采用協議號,TCP的協議號為6,UDP的協議號為17。ICMP的協議號為1,IGMP的協議號為2.
首部校驗和:計算IP頭部的校驗和,檢查IP報頭的完整性。
源IP地址:標識IP數據報的源端設備。
目的IP地址:標識IP數據報的目的地址。
33、keepalived工作原理
Layer3,4,&5工作早IP/TCP協議棧的IP層,TCP層,及應用層
原理:
Layer3:keepalived使用layer3的方式工作時,keepalived會定期向服務器群中發送一個ICMP的數據包(即我們平時用的ping程序),如果發現某臺服務器的IP地址沒有激活,keepalived便會報告這臺服務器是小,並將他從服務器群中剔除。Layer3的方式是以服務器的IP第孩子是否有效作為服務器工作正常與否的標準。
Layer4:主要以TCP端口的狀態來決定服務器工作正常與否。如web sercer的服務端口一般是80.如果keepalived檢測到80端口沒有啟動,則keepalived將這臺服務器從服務群中刪除。
Layer5:layer5就是工作載具體的應用層,比layer3,4要復雜一點,載網絡上占用的寬帶也要打一些。Keepalived將根據用戶的設定檢查服務器的運行是否正常。如果設定不相符,則keepalived將把服務器從群中踢除。
2018年企業運維開發經典面試題