
lambda架構簡介
1.Lambda架構背景介紹
Lambda架構是由Storm的作者Nathan Marz提出的一個實時大數據處理框架。Marz在Twitter工作期間開發了著名的實時大數據處理框架Storm,Lambda架構是其根據多年進行分布式大數據系統的經驗總結提煉而成。
Lambda架構的目標是設計出一個能滿足實時大數據系統關鍵特性的架構,包括有:高容錯、低延時和可擴展等。Lambda架構整合離線計算和實時計算,融合不可變性(Immunability),讀寫分離和復雜性隔離等一系列架構原則,可集成Hadoop,Kafka,Storm,Spark,Hbase等各類大數據組件。
2.大數據系統的關鍵特性
Marz認為大數據系統應具有以下的關鍵特性:
-
Robust and fault-tolerant(容錯性和魯棒性):對大規模分布式系統來說,機器是不可靠的,可能會當機,但是系統需要是健壯、行為正確的,即使是遇到機器錯誤。除了機器錯誤,人更可能會犯錯誤。在軟件開發中難免會有一些Bug,系統必須對有Bug的程序寫入的錯誤數據有足夠的適應能力,所以比機器容錯性更加重要的容錯性是人為操作容錯性。對於大規模的分布式系統來說,人和機器的錯誤每天都可能會發生,如何應對人和機器的錯誤,讓系統能夠從錯誤中快速恢復尤其重要。
-
Low latency reads and updates(低延時):很多應用對於讀和寫操作的延時要求非常高,要求對更新和查詢的響應是低延時的。
-
Scalable(橫向擴容):當數據量/負載增大時,可擴展性的系統通過增加更多的機器資源來維持性能。也就是常說的系統需要線性可擴展,通常采用scale out(通過增加機器的個數)而不是scale up(通過增強機器的性能)。
-
General(通用性):系統需要能夠適應廣泛的應用,包括金融領域、社交網絡、電子商務數據分析等。
-
Extensible(可擴展):需要增加新功能、新特性時,可擴展的系統能以最小的開發代價來增加新功能。
-
Allows ad hoc queries(方便查詢):數據中蘊含有價值,需要能夠方便、快速的查詢出所需要的數據。
-
Minimal maintenance(易於維護):系統要想做到易於維護,其關鍵是控制其復雜性,越是復雜的系統越容易出錯、越難維護。
-
Debuggable(易調試):當出問題時,系統需要有足夠的信息來調試錯誤,找到問題的根源。其關鍵是能夠追根溯源到每個數據生成點。
3.數據系統的本質
為了設計出能滿足前述的大數據關鍵特性的系統,我們需要對數據系統有本質性的理解。我們可將數據系統簡化為:
數據系統 = 數據 + 查詢
從而從數據和查詢兩方面來認識大數據系統的本質。
3.1.數據的本質
3.1.1.數據的特性:When & What
我們先從“數據”的特性談起。數據是一個不可分割的單位,數據有兩個關鍵的性質:When和What。
-
When是指數據是與時間相關的,數據一定是在某個時間點產生的。比如Log日誌就隱含著按照時間先後順序產生的數據,Log前面的日誌數據一定先於Log後面的日誌數據產生;消息系統中消息的接受者一定是在消息的發送者發送消息後接收到的消息。相比於數據庫,數據庫中表的記錄就丟失了時間先後順序的信息,中間某條記錄可能是在最後一條記錄產生後發生更新的。對於分布式系統,數據的時間特性尤其重要。分布式系統中數據可能產生於不同的系統中,時間決定了數據發生的全局先後順序。比如對一個值做算術運算,先+2,後*3,與先*3,後+2,得到的結果完全不同。數據的時間性質決定了數據的全局發生先後,也就決定了數據的結果。
-
What是指數據的本身。由於數據跟某個時間點相關,所以數據的本身是不可變的(immutable),過往的數據已經成為事實(Fact),你不可能回到過去的某個時間點去改變數據事實。這也就意味著對數據的操作其實只有兩種:讀取已存在的數據和添加更多的新數據。采用數據庫的記法,CRUD就變成了CR,Update和Delete本質上其實是新產生的數據信息,用C來記錄。
3.1.2.數據的存儲:Store Everything Rawly and Immutably
根據上述對數據本質特性的分析,Lamba架構中對數據的存儲采用的方式是:數據不可變,存儲所有數據。
通過采用不可變方式存儲所有的數據,可以有如下好處:
-
簡單。采用不可變的數據模型,存儲數據時只需要簡單的往主數據集後追加數據即可。相比於采用可變的數據模型,為了Update操作,數據通常需要被索引,從而能快速找到要更新的數據去做更新操作。
-
應對人為和機器的錯誤。前述中提到人和機器每天都可能會出錯,如何應對人和機器的錯誤,讓系統能夠從錯誤中快速恢復極其重要。不可變性(Immutability)和重新計算(Recomputation)則是應對人為和機器錯誤的常用方法。采用可變數據模型,引發錯誤的數據有可能被覆蓋而丟失。相比於采用不可變的數據模型,因為所有的數據都在,引發錯誤的數據也在。修復的方法就可以簡單的是遍歷數據集上存儲的所有的數據,丟棄錯誤的數據,重新計算得到Views(View的概念參考4.1.2)。重新計算的關鍵點在於利用數據的時間特性決定的全局次序,依次順序重新執行,必然能得到正確的結果。
當前業界有很多采用不可變數據模型來存儲所有數據的例子。比如分布式數據庫Datomic,基於不可變數據模型來存儲數據,從而簡化了設計。分布式消息中間件Kafka,基於Log日誌,以追加append-only的方式來存儲消息。
3.2.查詢
查詢是個什麽概念?Marz給查詢如下一個簡單的定義:
Query = Function(All Data)
該等式的含義是:查詢是應用於數據集上的函數。該定義看似簡單,卻幾乎囊括了數據庫和數據系統的所有領域:RDBMS、索引、OLAP、OLTP、MapReduce、EFL、分布式文件系統、NoSQL等都可以用這個等式來表示。
讓我們進一步深入看一下函數的特性,從而挖掘函數自身的特點來執行查詢。
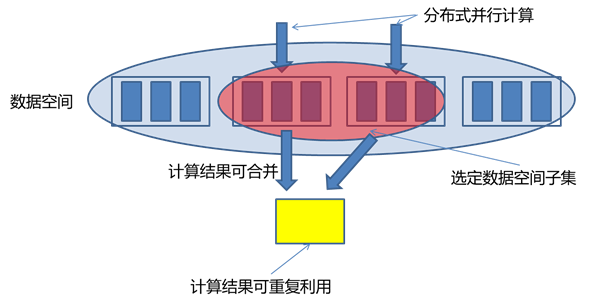
有一類稱為Monoid特性的函數應用非常廣泛。Monoid的概念來源於範疇學(Category Theory),其一個重要特性是滿足結合律。如整數的加法就滿足Monoid特性:
(a+b)+c=a+(b+c)
不滿足Monoid特性的函數很多時候可以轉化成多個滿足Monoid特性的函數的運算。如多個數的平均值Avg函數,多個平均值沒法直接通過結合來得到最終的平均值,但是可以拆成分母除以分子,分母和分子都是整數的加法,從而滿足Monoid特性。
Monoid的結合律特性在分布式計算中極其重要,滿足Monoid特性意味著我們可以將計算分解到多臺機器並行運算,然後再結合各自的部分運算結果得到最終結果。同時也意味著部分運算結果可以儲存下來被別的運算共享利用(如果該運算也包含相同的部分子運算),從而減少重復運算的工作量。
4.Lambda架構
有了上面對數據系統本質的探討,下面我們來討論大數據系統的關鍵問題:如何實時地在任意大數據集上進行查詢?大數據再加上實時計算,問題的難度比較大。
最簡單的方法是,根據前述的查詢等式Query = Function(All Data),在全體數據集上在線運行查詢函數得到結果。但如果數據量比較大,該方法的計算代價太大了,所以不現實。
Lambda架構通過分解的三層架構來解決該問題:Batch Layer,Speed Layer和Serving Layer。

4.1.Batch Layer
Batch Layer的功能主要有兩點:
- 存儲數據集
- 在數據集上預先計算查詢函數,構建查詢所對應的View
4.1.1.儲存數據集
根據前述對數據When&What特性的討論,Batch Layer采用不可變模型存儲所有的數據。因為數據量比較大,可以采用HDFS之類的大數據儲存方案。如果需要按照數據產生的時間先後順序存放數據,可以考慮如InfluxDB之類的時間序列數據庫(TSDB)存儲方案。
4.1.2.構建查詢View
上面說到根據等式Query = Function(All Data),在全體數據集上在線運行查詢函數得到結果的代價太大。但如果我們預先在數據集上計算並保存查詢函數的結果,查詢的時候就可以直接返回結果(或通過簡單的加工運算就可得到結果)而無需重新進行完整費時的計算了。這兒可以把Batch Layer看成是一個數據預處理的過程。我們把針對查詢預先計算並保存的結果稱為View,View是Lamba架構的一個核心概念,它是針對查詢的優化,通過View即可以快速得到查詢結果。 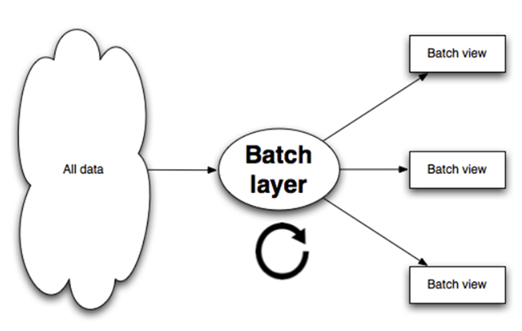
如果采用HDFS來儲存數據,我們就可以使用MapReduce來在數據集上構建查詢的View。Batch Layer的工作可以簡單的用如下偽碼表示: 
該工作看似簡單,實質非常強大。任何人為或機器發生的錯誤,都可以通過修正錯誤後重新計算來恢復得到正確結果。
對View的理解:
View是一個和業務關聯性比較大的概念,View的創建需要從業務自身的需求出發。一個通用的數據庫查詢系統,查詢對應的函數千變萬化,不可能窮舉。但是如果從業務自身的需求出發,可以發現業務所需要的查詢常常是有限的。Batch Layer需要做的一件重要的工作就是根據業務的需求,考察可能需要的各種查詢,根據查詢定義其在數據集上對應的Views。
4.2.Speed Layer
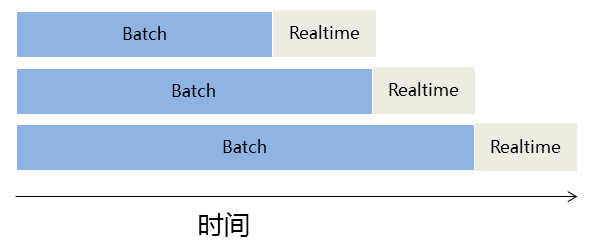
Batch Layer可以很好的處理離線數據,但有很多場景數據不斷實時生成,並且需要實時查詢處理。Speed Layer正是用來處理增量的實時數據。
Speed Layer和Batch Layer比較類似,對數據進行計算並生成Realtime View,其主要區別在於:
-
Speed Layer處理的數據是最近的增量數據流,Batch Layer處理的全體數據集
-
Speed Layer為了效率,接收到新數據時不斷更新Realtime View,而Batch Layer根據全體離線數據集直接得到Batch View。
Lambda架構將數據處理分解為Batch Layer和Speed Layer有如下優點:
-
容錯性。Speed Layer中處理的數據也不斷寫入Batch Layer,當Batch Layer中重新計算的數據集包含Speed Layer處理的數據集後,當前的Realtime View就可以丟棄,這也就意味著Speed Layer處理中引入的錯誤,在Batch Layer重新計算時都可以得到修正。這點也可以看成是CAP理論中的最終一致性(Eventual Consistency)的體現。
-
復雜性隔離。Batch Layer處理的是離線數據,可以很好的掌控。Speed Layer采用增量算法處理實時數據,復雜性比Batch Layer要高很多。通過分開Batch Layer和Speed Layer,把復雜性隔離到Speed Layer,可以很好的提高整個系統的魯棒性和可靠性。
4.3.Serving Layer
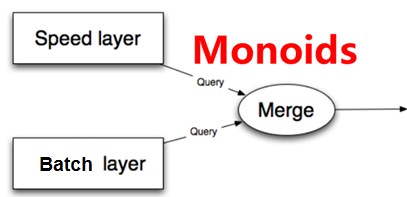
Lambda架構的Serving Layer用於響應用戶的查詢請求,合並Batch View和Realtime View中的結果數據集到最終的數據集。
這兒涉及到數據如何合並的問題。前面我們討論了查詢函數的Monoid性質,如果查詢函數滿足Monoid性質,即滿足結合率,只需要簡單的合並Batch View和Realtime View中的結果數據集即可。否則的話,可以把查詢函數轉換成多個滿足Monoid性質的查詢函數的運算,單獨對每個滿足Monoid性質的查詢函數進行Batch View和Realtime View中的結果數據集合並,然後再計算得到最終的結果數據集。另外也可以根據業務自身的特性,運用業務自身的規則來對Batch View和Realtime View中的結果數據集合並。
5.Big Picture
上面分別討論了Lambda架構的三層:Batch Layer,Speed Layer和Serving Layer。下圖給出了Lambda架構的一個完整視圖和流程。
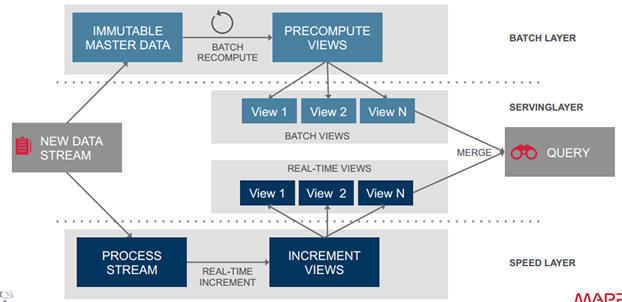
數據流進入系統後,同時發往Batch Layer和Speed Layer處理。Batch Layer以不可變模型離線存儲所有數據集,通過在全體數據集上不斷重新計算構建查詢所對應的Batch Views。Speed Layer處理增量的實時數據流,不斷更新查詢所對應的Realtime Views。Serving Layer響應用戶的查詢請求,合並Batch View和Realtime View中的結果數據集到最終的數據集。
5.1.Lambda架構組件選型
下圖給出了Lambda架構中各個層常用的組件。數據流存儲可選用基於不可變日誌的分布式消息系統Kafka;Batch Layer數據集的存儲可選用Hadoop的HDFS,或者是阿裏雲的ODPS;Batch View的預計算可以選用MapReduce或Spark;Batch View自身結果數據的存儲可使用MySQL(查詢少量的最近結果數據),或HBase(查詢大量的歷史結果數據)。Speed Layer增量數據的處理可選用Storm或Spark Streaming;Realtime View增量結果數據集為了滿足實時更新的效率,可選用Redis等內存NoSQL。
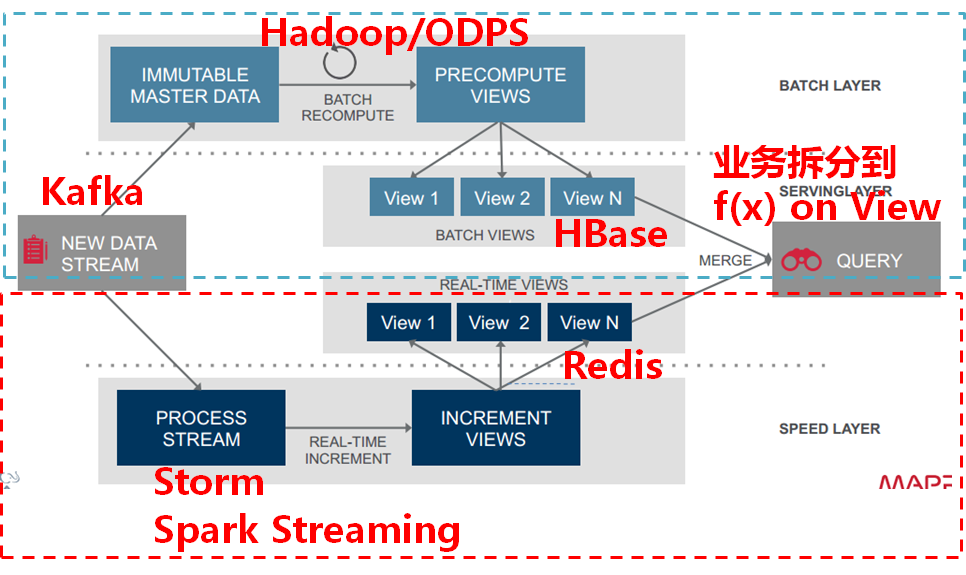
5.2.Lambda架構組件選型原則
Lambda架構是個通用框架,各個層選型時不要局限時上面給出的組件,特別是對於View的選型。從我對Lambda架構的實踐來看,因為View是個和業務關聯性非常大的概念,View選擇組件時關鍵是要根據業務的需求,來選擇最適合查詢的組件。不同的View組件的選擇要深入挖掘數據和計算自身的特點,從而選擇出最適合數據和計算自身特點的組件,同時不同的View可以選擇不同的組件。
6.Lambda架構 vs. Event Sourcing vs. CQRS
在Lambda架構身上可以看到很多現有設計思想和架構的影子,如Event Sourcing和CQRS,這兒我們把它們和Lambda架構做一結合對比,從而去更深入的理解Lambda架構。
6.1.事件溯源(Event Sourcing)vs. Lambda架構
事件溯源(Event Sourcing)是由大名鼎鼎的Martin Flower大叔提出來的架構模式。Event Sourcing本質上是一種數據持久化的方式,它將引發變化的事件(Event)本身存儲下來。相比於傳統數據是持久化方式,存儲的是事件引發的結果,而非事件本身,這樣我們在保存結果的同時,實際上失去了追溯導致結果原因的機會。
這兒可以看到Lambda架構中數據集的存儲和Event Sourcing中的思想是完全一致的,本質都是采用不可變的數據模型存儲引發變化的事件而非變化產生的結果。從而在發生錯誤的時候,能夠追本溯源,找到發生錯誤的根源,通過重新計算丟棄錯誤的信息來恢復系統,達到系統的容錯性。
6.2.CQRS vs. Lambda架構
CQRS (Command Query Responsibility Segregation)將對數據的修改操作和查詢操作分離,其本質和Lambda架構一樣,也是一種形式的讀寫分離。在Lambda架構中,數據以不可變的方式存儲下來(寫操作),轉換成查詢所對應的Views,查詢從View中直接得到結果數據(讀操作)。
讀寫分離將讀和寫兩個視角進行分離,帶來的好處是復雜性的隔離,從而簡化系統的設計。相比於傳統做法中的將讀和寫操作放在一起的處理方式,對於讀寫操作業務非常復雜的系統,只會使系統變得異常復雜,難以維護。

7.總結
本文介紹了Lambda架構的基本概念。Lambda架構通過對數據和查詢的本質認識,融合了不可變性(Immunability),讀寫分離和復雜性隔離等一系列架構原則,將大數據處理系統劃分為Batch Layer, Speed Layer和Serving Layer三層,從而設計出一個能滿足實時大數據系統關鍵特性(如高容錯、低延時和可擴展等)的架構。Lambda架構作為一個通用的大數據處理框架,可以很方便的集成Hadoop,Kafka,Storm,Spark,Hbase等各類大數據組件。
原文地址:https://blog.csdn.net/brucesea/article/details/45937875
lambda架構簡介