
Structured Streaming教程(1) —— 基本概念與使用
近年來,大數據的計算引擎越來越受到關註,spark作為最受歡迎的大數據計算框架,也在不斷的學習和完善中。在Spark2.x中,新開放了一個基於DataFrame的無下限的流式處理組件——Structured Streaming,它也是本系列的主角,廢話不多說,進入正題吧!
簡單介紹
在有過1.6的streaming和2.x的streaming開發體驗之後,再來使用Structured Streaming會有一種完全不同的體驗,尤其是在代碼設計上。
在過去使用streaming時,我們很容易的理解為一次處理是當前batch的所有數據,只要針對這波數據進行各種處理即可。如果要做一些類似pv uv的統計,那就得借助有狀態的state的DStream,或者借助一些分布式緩存系統,如Redis、Alluxio都能實現。需要關註的就是盡量快速的處理完當前的batch數據,以及7*24小時的運行即可。
可以看到想要去做一些類似Group by的操作,Streaming是非常不便的。Structured Streaming則完美的解決了這個問題。
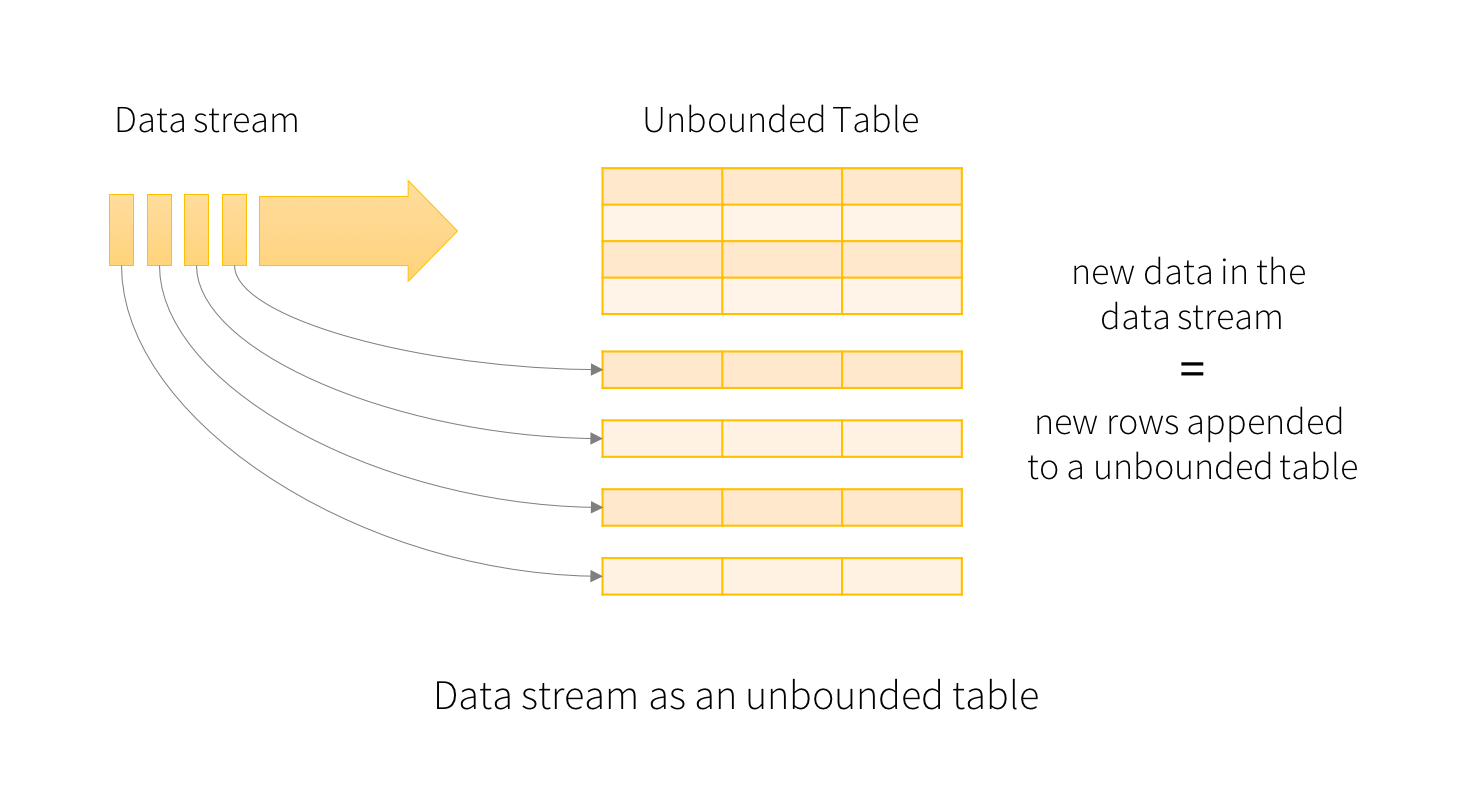
在Structured Streaming中,把源源不斷到來的數據通過固定的模式“追加”或者“更新”到了上面無下限的DataFrame中。剩余的工作則跟普通的DataFrame一樣,可以去map、filter,也可以去groupby().count()。甚至還可以把流處理的dataframe跟其他的“靜態”DataFrame進行join。另外,還提供了基於window時間的流式處理。總之,Structured Streaming提供了快速、可擴展、高可用、高可靠的流式處理。
小栗子
在大數據開發中,Word Count就是基本的演示示例,所以這裏也模仿官網的例子,做一下演示。
直接看一下完整的例子:
package xingoo.sstreaming
import org.apache.spark.sql.SparkSession
object WordCount {
def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder
.master("local")
.appName("StructuredNetworkWordCount" 效果就是在控制臺輸入nc -lk 9999,然後輸入一大堆的字符,控制臺就輸出了對應的結果:

然後來詳細看一下代碼:
val spark = SparkSession
.builder
.master("local")
.appName("StructuredNetworkWordCount")
.getOrCreate()
spark.sparkContext.setLogLevel("WARN")
import spark.implicits._上面就不用太多解釋了吧,創建一個本地的sparkSession,設置日誌的級別為WARN,要不控制臺太亂。然後引入spark sql必要的方法(如果沒有import spark.implicits._,基本類型是無法直接轉化成DataFrame的)。
val lines = spark.readStream
.format("socket")
.option("host", "localhost")
.option("port", 9999)
.load()創建了一個Socket連接的DataStream,並通過load()方法獲取當前批次的DataFrame。
val words = lines.as[String].flatMap(_.split(" "))
val wordCounts = words.groupBy("value").count()先把DataFrame轉成單列的DataSet,然後通過空格切分每一行,再根據value做groupby,並統計個數。
val query = wordCounts.writeStream
.outputMode("complete")
.format("console")
.start()調用DataFrame的writeStream方法,轉換成輸出流,設置模式為"complete",指定輸出對象為控制臺"console",然後調用start()方法啟動計算。並返回queryStreaming,進行控制。
這裏的outputmode和format都會後續詳細介紹。
query.awaitTermination()通過QueryStreaming的對象,調用awaitTermination阻塞主線程。程序就可以不斷循環調用了。
觀察一下Spark UI,可以發現程序穩定的在運行~

總結
這就是一個最基本的wordcount的例子,想象一下,如果沒有Structured Streaming,想要統計全局的wordcount,還是很費勁的(即便使用streaming的state,其實也不是那麽好用的)。
Structured Streaming教程(1) —— 基本概念與使用