
集成學習lgb庫調參的粒子群方法
阿新 • • 發佈:2018-06-12
機器學習 算法 集成學習 粒子群算法是模擬鳥群蜂群的覓食行為的一種算法。基本思想是通過群體中個體之間的協作和信息共享來尋找最優解。試著想一下一群鳥在尋找食物,在這個區域中只有一只蟲子,所有的鳥都不知道食物在哪。但是它們知道自己的當前位置距離食物有多遠,同時它們知道離食物最近的鳥的位置。想一下這時候會發生什麽?
鳥A:哈哈哈原來蟲子離我最近!
鳥B,C,D:我得趕緊往 A 那裏過去看看!
同時各只鳥在位置不停變化時候離食物的距離也不斷變化,所以一定有過離食物最近的位置,這也是它們的一個參考。鳥某某:我剛剛的位置好像靠近了食物,我得往那裏靠近!
公式請自行百度 知乎
具體代碼流程如下: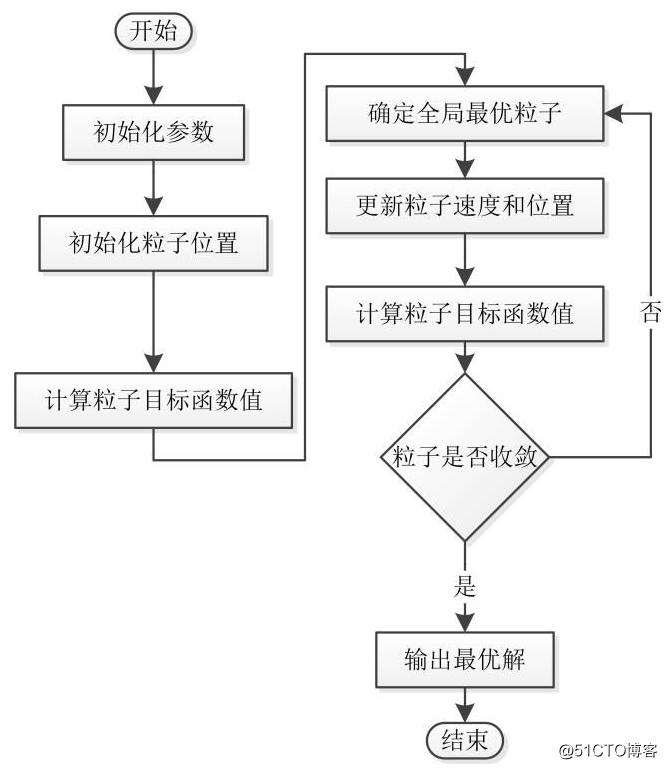
本文主要描述如何用粒子群方法搜索到一個適合lgb的參數
先要定一個損失函數:
def gini_coef(wealths): cum_wealths = np.cumsum(sorted(np.append(wealths, 0))) sum_wealths = cum_wealths[-1] xarray = np.array(range(0, len(cum_wealths))) / np.float(len(cum_wealths)-1) yarray = cum_wealths / sum_wealths B = np.trapz(yarray, x=xarray) A = 0.5 - B return A / (A+B)
當然也可以傳入訓練數據的標簽值 和預測值做協方差 這裏采用基尼系數作為損失函數
定義一個評估函數:用於評估該參數版本的效果如何:
def evaluate(train1 , feature_use,parent): np.set_printoptions(suppress=True) print("*************************************") print(parent) model_lgb = lgb.LGBMRegressor(objective=‘regression‘, min_sum_hessian_in_leaf=parent[0], learning_rate=parent[1], bagging_fraction=parent[2], feature_fraction=parent[3], num_leaves=int(parent[4]), n_estimators=int(parent[5]), max_bin=int(parent[6]), bagging_freq=int(parent[7]), feature_fraction_seed=int(parent[8]), min_data_in_leaf=int(parent[9]), is_unbalance = True ) targetme = train1[‘target‘] X_train, X_test, y_train, y_test = train_test_split(train1[feature_use] , targetme, test_size=0.5) model_lgb.fit(X_train.fillna(-1), y_train) y_pred = model_lgb.predict(X_test.fillna(-1)) return gini_coef(y_pred)
參數初始化代碼:
## 參數初始化
# 粒子群算法中的兩個參數
c1 = 1.49445
c2 = 1.49445
maxgen= 50 # 進化次數
sizepop= 100 # 種群規模
Vmax1=0.1
Vmin1=-0.1
## 產生初始粒子和速度
pop=[]
V = []
fitness =[]
for i in range(sizepop):
# 隨機產生一個種群
temp_pop =[]
temp_v = []
min_sum_hessian_in_leaf = random.random()
temp_pop.append(min_sum_hessian_in_leaf)
temp_v.append(random.random())
learning_rate = random.uniform(0.001,0.2)
temp_pop.append(learning_rate)
temp_v.append(random.random())
bagging_fraction = random.uniform(0.5,1)
temp_pop.append(bagging_fraction)
temp_v.append(random.random())
feature_fraction = random.uniform(0.3,1)
temp_pop.append(feature_fraction)
temp_v.append(random.random())
num_leaves = random.randint(3,100)
temp_pop.append(num_leaves)
temp_v.append(random.randint(-3,3))
n_estimators = random.randint(800,1200)
temp_pop.append(n_estimators)
temp_v.append(random.randint(-3,3))
max_bin = random.randint(100,500)
temp_pop.append(max_bin)
temp_v.append(random.randint(-3,3))
bagging_freq = random.randint(1,10)
temp_pop.append(bagging_freq)
temp_v.append(random.randint(-3,3))
feature_fraction_seed = random.randint(1,10)
temp_pop.append(feature_fraction_seed)
temp_v.append(random.randint(-3,3))
min_data_in_leaf = random.randint(1,20)
temp_pop.append(min_data_in_leaf)
temp_v.append(random.randint(-3,3))
pop.append(temp_pop) # 初始種群
V.append(temp_v) # 初始化速度
# 計算適應度
fitness.append(evaluate(train1,feature_use ,temp_pop)) # 染色體的適應度 end
pop = np.array(pop)
V = np.array(V)
# 個體極值和群體極值
bestfitness =min(fitness)
bestIndex = fitness.index(bestfitness)
zbest=pop[bestIndex,:] #全局最佳
gbest=pop #個體最佳
fitnessgbest=fitness #個體最佳適應度值
fitnesszbest=bestfitness #全局最佳適應度值開始叠代尋優:
count = 0
## 叠代尋優
for i in range(maxgen):
for j in range(sizepop):
count = count + 1
print(count)
# 速度更新
V[j,:] = V[j,:] + c1 * random.random() * (gbest[j,:] - pop[j,:]) + c2 * random.random() * (zbest - pop[j,:])
if(V[j,0]<-0.1):
V[j,0]=-0.1
if(V[j,0]>0.1):
V[j,0]=0.1
if(V[j,1]<-0.02):
V[j,1]=-0.02
if(V[j,1]>0.02):
V[j,1]=0.02
if(V[j,2]<-0.1):
V[j,2]=-0.1
if(V[j,2]>0.1):
V[j,2]=0.1
if(V[j,3]<-0.1):
V[j,3]=-0.1
if(V[j,3]>0.1):
V[j,3]=0.1
if(V[j,4]<-2):
V[j,4]=-2
if(V[j,4]>2):
V[j,4]=2
if(V[j,5]<-10):
V[j,5]=-10
if(V[j,5]>10):
V[j,5]=10
if(V[j,6]<-5):
V[j,6]=-5
if(V[j,6]>5):
V[j,6]=5
if(V[j,7]<-1):
V[j,7]=-1
if(V[j,7]>1):
V[j,7]=1
if(V[j,8]<-1):
V[j,8]=-1
if(V[j,8]>1):
V[j,8]=1
if(V[j,9]<-1):
V[j,9]=-1
if(V[j,9]>1):
V[j,9]=1
pop[j,:]=pop[j,:]+0.5*V[j,:]
if(pop[j,0]<0):
pop[j,0]=0.001
if (pop[j, 0] > 1):
pop[j, 0] = 0.9
if (pop[j, 1] < 0):
pop[j, 1] = 0.001
if (pop[j, 1] > 0.2):
pop[j, 1] = 0.2
if (pop[j, 2] < 0.5):
pop[j, 2] = 0.5
if (pop[j, 2] > 1):
pop[j, 2] = 1
if (pop[j, 3] < 0.3):
pop[j, 3] = 0.3
if (pop[j, 3] > 1):
pop[j, 3] = 1
if (pop[j, 4] < 3):
pop[j, 4] =3
if (pop[j, 4] > 100):
pop[j, 4] = 100
if (pop[j, 5] < 800):
pop[j, 5] = 800
if (pop[j, 5] > 1200):
pop[j, 5] = 1200
if (pop[j, 6] < 100):
pop[j, 6] = 100
if (pop[j, 6] > 500):
pop[j, 6] = 500
if (pop[j, 7] < 1):
pop[j, 7] = 1
if (pop[j, 7] > 10):
pop[j, 7] = 10
if (pop[j, 8] < 1):
pop[j, 8] = 1
if (pop[j, 8] > 10):
pop[j, 8] = 10
if (pop[j, 9] < 1):
pop[j, 9] = 1
if (pop[j, 9] > 20):
pop[j, 9] = 20
fitness[j] = evaluate(train1,feature_use,pop[j,:])
for k in range(1,sizepop):
if(fitness[k] > fitnessgbest[k]):
gbest[k,:] = pop[k,:]
fitnessgbest[k] = fitness[k]
#群體最優更新
if fitness[k] > fitnesszbest:
zbest = pop[k,:]
fitnesszbest = fitness[k]載入參數進行預測:
# 采用lgb回歸預測模型,具體參數設置如下
model_lgb = lgb.LGBMRegressor(objective=‘regression‘,
min_sum_hessian_in_leaf=zbest[0],
learning_rate=zbest[1],
bagging_fraction=zbest[2],
feature_fraction=zbest[3],
num_leaves=int(zbest[4]),
n_estimators=int(zbest[5]),
max_bin=int(zbest[6]),
bagging_freq=int(zbest[7]),
feature_fraction_seed=int(zbest[8]),
min_data_in_leaf=int(zbest[9]),
is_unbalance=True)
targetme=train1[‘target‘]
model_lgb.fit(train1[feature_use].fillna(-1), train1[‘target‘])
y_pred = model_lgb.predict(test1[feature_use].fillna(-1))
print("lgb success")上文中的 train是 pandas中的dataframe類型,下圖為這個代碼運行起來的情況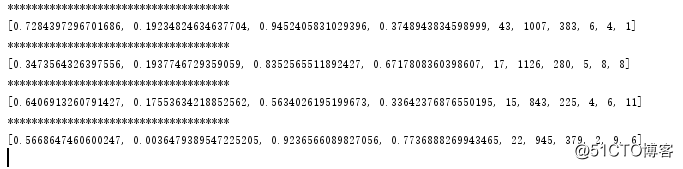
有技術交流的可以掃描以下
集成學習lgb庫調參的粒子群方法