
遷移學習總結
遷移學習與Adaboost
轉自:http://www.cnblogs.com/harvey888/p/5505511.html

Adaboost 算法的原理與推導
0 引言
一直想寫Adaboost來著,但遲遲未能動筆。其算法思想雖然簡單:聽取多人意見,最後綜合決策,但一般書上對其算法的流程描述實在是過於晦澀。昨日11月1日下午,在我組織的機器學習班 第8次課上Z講師講決策樹與Adaboost,其中,Adaboost講得酣暢淋漓,講完後,我知道,可以寫本篇博客了。
無心啰嗦,本文結合機器學習班決策樹與Adaboost 的PPT,跟鄒講Adaboost指數損失函數推導的PPT(第85~第98頁)、以及《統計學習方法》等參考資料寫就,可以定義為一篇課程筆記、讀書筆記或學習心得,有何問題或意見,歡迎於本文評論下隨時不吝指出,thanks。
1 Adaboost的原理
1.1 Adaboost是什麽
AdaBoost,是英文"Adaptive Boosting"(自適應增強)的縮寫,由Yoav Freund和Robert Schapire在1995年提出。它的自適應在於:前一個基本分類器分錯的樣本會得到加強,加權後的全體樣本再次被用來訓練下一個基本分類器。同時,在 每一輪中加入一個新的弱分類器,直到達到某個預定的足夠小的錯誤率或達到預先指定的最大叠代次數。
具體說來,整個Adaboost 叠代算法就3步:
- 初始化訓練數據的權值分布。如果有N個樣本,則每一個訓練樣本最開始時都被賦予相同的權值:1/N。
- 訓練弱分類器。具體訓練過程中,如果某個樣本點已經被準確地分類,那麽在構造下一個訓練集中,它的權值就被降低;相反,如果某個樣本點沒有被準確地分類,那麽它的權值就得到提高。然後,權值更新過的樣本集被用於訓練下一個分類器,整個訓練過程如此叠代地進行下去。
- 將 各個訓練得到的弱分類器組合成強分類器。各個弱分類器的訓練過程結束後,加大分類誤差率小的弱分類器的權重,使其在最終的分類函數中起著較大的決定作用, 而降低分類誤差率大的弱分類器的權重,使其在最終的分類函數中起著較小的決定作用。換言之,誤差率低的弱分類器在最終分類器中占的權重較大,否則較小。
1.2 Adaboost算法流程
給定一個訓練數據集T={(x1,y1), (x2,y2)…(xN,yN)},其中實例
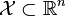 ,yi屬於標記集合{-1,+1},Adaboost的目的就是從訓練數據中學習一系列弱分類器或基本分類器,然後將這些弱分類器組合成一個強分類器。
,yi屬於標記集合{-1,+1},Adaboost的目的就是從訓練數據中學習一系列弱分類器或基本分類器,然後將這些弱分類器組合成一個強分類器。
Adaboost的算法流程如下:
- 步驟1. 首先,初始化訓練數據的權值分布。每一個訓練樣本最開始時都被賦予相同的權值:1/N。

- 步驟2. 進行多輪叠代,用m = 1,2, ..., M表示叠代的第多少輪
a. 使用具有權值分布Dm的訓練數據集學習,得到基本分類器(選取讓誤差率最低的閾值來設計基本分類器):

b. 計算Gm(x)在訓練數據集上的分類誤差率
c. 計算Gm(x)的系數,am表示Gm(x)在最終分類器中的重要程度(目的:得到基本分類器在最終分類器中所占的權重):由上述式子可知,Gm(x)在訓練數據集上的誤差率em就是被Gm(x)誤分類樣本的權值之和。

由上述式子可知,em <= 1/2時,am >= 0,且am隨著em的減小而增大,意味著分類誤差率越小的基本分類器在最終分類器中的作用越大。

d. 更新訓練數據集的權值分布(目的:得到樣本的新的權值分布),用於下一輪叠代

使得被基本分類器Gm(x)誤分類樣本的權值增大,而被正確分類樣本的權值減小。就這樣,通過這樣的方式,AdaBoost方法能“重點關註”或“聚焦於”那些較難分的樣本上。
其中,Zm是規範化因子,使得Dm+1成為一個概率分布:

- 步驟3. 組合各個弱分類器

從而得到最終分類器,如下:

1.3 Adaboost的一個例子
下面,給定下列訓練樣本,請用AdaBoost算法學習一個強分類器。

求解過程:初始化訓練數據的權值分布,令每個權值W1i = 1/N = 0.1,其中,N = 10,i = 1,2, ..., 10,然後分別對於m = 1,2,3, ...等值進行叠代。
拿到這10個數據的訓練樣本後,根據 X 和 Y 的對應關系,要把這10個數據分為兩類,一類是“1”,一類是“-1”,根據數據的特點發現:“0 1 2”這3個數據對應的類是“1”,“3 4 5”這3個數據對應的類是“-1”,“6 7 8”這3個數據對應的類是“1”,9是比較孤獨的,對應類“-1”。拋開孤獨的9不講,“0 1 2”、“3 4 5”、“6 7 8”這是3類不同的數據,分別對應的類是1、-1、1,直觀上推測可知,可以找到對應的數據分界點,比如2.5、5.5、8.5 將那幾類數據分成兩類。當然,這只是主觀臆測,下面實際計算下這個具體過程。
叠代過程1
對於m=1,在權值分布為D1(10個數據,每個數據的權值皆初始化為0.1)的訓練數據上,經過計算可得:
- 閾值v取2.5時誤差率為0.3(x < 2.5時取1,x > 2.5時取-1,則6 7 8分錯,誤差率為0.3),
- 閾 值v取5.5時誤差率最低為0.4(x < 5.5時取1,x > 5.5時取-1,則3 4 5 6 7 8皆分錯,誤差率0.6大於0.5,不可取。故令x > 5.5時取1,x < 5.5時取-1,則0 1 2 9分錯,誤差率為0.4),
- 閾值v取8.5時誤差率為0.3(x < 8.5時取1,x > 8.5時取-1,則3 4 5分錯,誤差率為0.3)。
可以看到,無論閾值v取2.5,還是8.5,總得分錯3個樣本,故可任取其中任意一個如2.5,弄成第一個基本分類器為:

上面說閾值v取2.5時則6 7 8分錯,所以誤差率為0.3,更加詳細的解釋是:因為樣本集中
- 0 1 2對應的類(Y)是1,因它們本身都小於2.5,所以被G1(x)分在了相應的類“1”中,分對了。
- 3 4 5本身對應的類(Y)是-1,因它們本身都大於2.5,所以被G1(x)分在了相應的類“-1”中,分對了。
- 但6 7 8本身對應類(Y)是1,卻因它們本身大於2.5而被G1(x)分在了類"-1"中,所以這3個樣本被分錯了。
- 9本身對應的類(Y)是-1,因它本身大於2.5,所以被G1(x)分在了相應的類“-1”中,分對了。
從而得到G1(x)在訓練數據集上的誤差率(被G1(x)誤分類樣本“6 7 8”的權值之和)e1=P(G1(xi)≠yi) = 3*0.1 = 0.3。
然後根據誤差率e1計算G1的系數:

這個a1代表G1(x)在最終的分類函數中所占的權重,為0.4236。
接著更新訓練數據的權值分布,用於下一輪叠代:

值得一提的是,由權值更新的公式可知,每個樣本的新權值是變大還是變小,取決於它是被分錯還是被分正確。
即如果某個樣本被分錯了,則yi * Gm(xi)為負,負負得正,結果使得整個式子變大(樣本權值變大),否則變小。
第一輪叠代後,最後得到各個數據新的權值分布D2 = (0.0715, 0.0715, 0.0715, 0.0715, 0.0715, 0.0715, 0.1666, 0.1666, 0.1666, 0.0715)。由此可以看出,因為樣本中是數據“6 7 8”被G1(x)分錯了,所以它們的權值由之前的0.1增大到0.1666,反之,其它數據皆被分正確,所以它們的權值皆由之前的0.1減小到0.0715。
分類函數f1(x)= a1*G1(x) = 0.4236G1(x)。
此時,得到的第一個基本分類器sign(f1(x))在訓練數據集上有3個誤分類點(即6 7 8)。
從上述第一輪的整個叠代過程可以看出:被誤分類樣本的權值之和影響誤差率,誤差率影響基本分類器在最終分類器中所占的權重。
叠代過程2
對於m=2,在權值分布為D2 = (0.0715, 0.0715, 0.0715, 0.0715, 0.0715, 0.0715, 0.1666, 0.1666, 0.1666, 0.0715)的訓練數據上,經過計算可得:
- 閾值v取2.5時誤差率為0.1666*3(x < 2.5時取1,x > 2.5時取-1,則6 7 8分錯,誤差率為0.1666*3),
- 閾值v取5.5時誤差率最低為0.0715*4(x > 5.5時取1,x < 5.5時取-1,則0 1 2 9分錯,誤差率為0.0715*3 + 0.0715),
- 閾值v取8.5時誤差率為0.0715*3(x < 8.5時取1,x > 8.5時取-1,則3 4 5分錯,誤差率為0.0715*3)。
所以,閾值v取8.5時誤差率最低,故第二個基本分類器為:

面對的還是下述樣本:
很明顯,G2(x)把樣本“3 4 5”分錯了,根據D2可知它們的權值為0.0715, 0.0715, 0.0715,所以G2(x)在訓練數據集上的誤差率e2=P(G2(xi)≠yi) = 0.0715 * 3 = 0.2143。
計算G2的系數:

更新訓練數據的權值分布:

D3 = (0.0455, 0.0455, 0.0455, 0.1667, 0.1667, 0.01667, 0.1060, 0.1060, 0.1060, 0.0455)。被分錯的樣本“3 4 5”的權值變大,其它被分對的樣本的權值變小。
f2(x)=0.4236G1(x) + 0.6496G2(x)
此時,得到的第二個基本分類器sign(f2(x))在訓練數據集上有3個誤分類點(即3 4 5)。
叠代過程3
對於m=3,在權值分布為D3 = (0.0455, 0.0455, 0.0455, 0.1667, 0.1667, 0.01667, 0.1060, 0.1060, 0.1060, 0.0455)的訓練數據上,經過計算可得:
- 閾值v取2.5時誤差率為0.1060*3(x < 2.5時取1,x > 2.5時取-1,則6 7 8分錯,誤差率為0.1060*3),
- 閾值v取5.5時誤差率最低為0.0455*4(x > 5.5時取1,x < 5.5時取-1,則0 1 2 9分錯,誤差率為0.0455*3 + 0.0715),
- 閾值v取8.5時誤差率為0.1667*3(x < 8.5時取1,x > 8.5時取-1,則3 4 5分錯,誤差率為0.1667*3)。
所以閾值v取5.5時誤差率最低,故第三個基本分類器為:

依然還是原樣本:
此時,被誤分類的樣本是:0 1 2 9,這4個樣本所對應的權值皆為0.0455,
所以G3(x)在訓練數據集上的誤差率e3 = P(G3(xi)≠yi) = 0.0455*4 = 0.1820。
計算G3的系數:

更新訓練數據的權值分布:

D4 = (0.125, 0.125, 0.125, 0.102, 0.102, 0.102, 0.065, 0.065, 0.065, 0.125)。被分錯的樣本“0 1 2 9”的權值變大,其它被分對的樣本的權值變小。
f3(x)=0.4236G1(x) + 0.6496G2(x)+0.7514G3(x)
此時,得到的第三個基本分類器sign(f3(x))在訓練數據集上有0個誤分類點。至此,整個訓練過程結束。
現在,咱們來總結下3輪叠代下來,各個樣本權值和誤差率的變化,如下所示(其中,樣本權值D中加了下劃線的表示在上一輪中被分錯的樣本的新權值):
- 訓練之前,各個樣本的權值被初始化為D1 = (0.1, 0.1,0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1);
- 第一輪叠代中,樣本“6 7 8”被分錯,對應的誤差率為e1=P(G1(xi)≠yi) = 3*0.1 = 0.3,此第一個基本分類器在最終的分類器中所占的權重為a1 = 0.4236。第一輪叠代過後,樣本新的權值為D2 = (0.0715, 0.0715, 0.0715, 0.0715, 0.0715, 0.0715, 0.1666, 0.1666, 0.1666, 0.0715);
- 第二輪叠代中,樣本“3 4 5”被分錯,對應的誤差率為e2=P(G2(xi)≠yi) = 0.0715 * 3 = 0.2143,此第二個基本分類器在最終的分類器中所占的權重為a2 = 0.6496。第二輪叠代過後,樣本新的權值為D3 = (0.0455, 0.0455, 0.0455, 0.1667, 0.1667, 0.01667, 0.1060, 0.1060, 0.1060, 0.0455);
- 第三輪叠代中,樣本“0 1 2 9”被分錯,對應的誤差率為e3 = P(G3(xi)≠yi) = 0.0455*4 = 0.1820,此第三個基本分類器在最終的分類器中所占的權重為a3 = 0.7514。第三輪叠代過後,樣本新的權值為D4 = (0.125, 0.125, 0.125, 0.102, 0.102, 0.102, 0.065, 0.065, 0.065, 0.125)。
從上述過程中可以發現,如果某些個樣本被分錯,它們在下一輪叠代中的權值將被增大,同時,其它被分對的樣本在下一輪叠代中的權值將被減小。就這樣,分錯樣本權值增大,分對樣本權值變小,而在下一輪叠代中,總是選取讓誤差率最低的閾值來設計基本分類器,所以誤差率e(所有被Gm(x)誤分類樣本的權值之和)不斷降低。
綜上,將上面計算得到的a1、a2、a3各值代入G(x)中,G(x) = sign[f3(x)] = sign[ a1 * G1(x) + a2 * G2(x) + a3 * G3(x) ],得到最終的分類器為:
G(x) = sign[f3(x)] = sign[ 0.4236G1(x) + 0.6496G2(x)+0.7514G3(x) ]。
2 Adaboost的誤差界
通過上面的例子可知,Adaboost在學習的過程中不斷減少訓練誤差e,直到各個弱分類器組合成最終分類器,那這個最終分類器的誤差界到底是多少呢?
事實上,Adaboost 最終分類器的訓練誤差的上界為:

下面,咱們來通過推導來證明下上述式子。
當G(xi)≠yi時,yi*f(xi)<0,因而exp(-yi*f(xi))≥1,因此前半部分得證。
關於後半部分,別忘了:

整個的推導過程如下:

這個結果說明,可以在每一輪選取適當的Gm使得Zm最小,從而使訓練誤差下降最快。接著,咱們來繼續求上述結果的上界。
對於二分類而言,有如下結果:

其中,
繼續證明下這個結論。
由之前Zm的定義式跟本節最開始得到的結論可知:

而這個不等式
值得一提的是,如果取γ1, γ2… 的最小值,記做γ(顯然,γ≥γi>0,i=1,2,...m),則對於所有m,有:

這個結論表明,AdaBoost的訓練誤差是以指數速率下降的。另外,AdaBoost算法不需要事先知道下界γ,AdaBoost具有自適應性,它能適應弱分類器各自的訓練誤差率 。
最後,Adaboost 還有另外一種理解,即可以認為其模型是加法模型、損失函數為指數函數、學習算法為前向分步算法的二類分類學習方法,下個月即12月份會再推導下,然後更新此文。而在此之前,有興趣的可以參看《統計學習方法》第8.3節或其它相關資料。
3 Adaboost 指數損失函數推導
事實上,在上文1.2節Adaboost的算法流程的步驟3中,我們構造的各個基本分類器的線性組合
是一個加法模型,而Adaboost算法其實是前向分步算法的特例。那麽問題來了,什麽是加法模型,什麽又是前向分步算法呢?
3.1 加法模型和前向分步算法
如下圖所示的便是一個加法模型

其中,


在給定訓練數據及損失函數


隨後,該問題可以作如此簡化:從前向後,每一步只學習一個基函數及其系數,逐步逼近上式,即:每步只優化如下損失函數:

這個優化方法便就是所謂的前向分步算法。
下面,咱們來具體看下前向分步算法的算法流程:
- 輸入:訓練數據集
- 損失函數:
- 基函數集:
- 輸出:加法模型
- 算法步驟:
- 1. 初始化
- 2. 對於m=1,2,..M
- a)極小化損失函數



得到參數

- b)更新

- 3. 最終得到加法模型

就這樣,前向分步算法將同時求解從m=1到M的所有參數(
3.2 前向分步算法與Adaboost的關系
在上文第2節最後,我們說Adaboost 還有另外一種理解,即可以認為其模型是加法模型、損失函數為指數函數、學習算法為前向分步算法的二類分類學習方法。其實,Adaboost算法就是前向分步算法的一個特例,Adaboost 中,各個基本分類器就相當於加法模型中的基函數,且其損失函數為指數函數。
換句話說,當前向分步算法中的基函數為Adaboost中的基本分類器時,加法模型等價於Adaboost的最終分類器
你甚至可以說,這個最終分類器其實就是一個加法模型。只是這個加法模型由基本分類器

下面,咱們便來證明:當前向分步算法的損失函數是指數損失函數

時,其學習的具體操作等價於Adaboost算法的學習過程。
假設經過m-1輪叠代,前向分步算法已經得到

而後在第m輪叠代得到

而

針對這種需要求解多個參數的情況,可以先固定其它參數,求解其中一兩個參數,然後逐一求解剩下的參數。例如我們可以固定

換言之,在面對

- 先假定
- 然後再逐一求解其它未知參數。
且考慮到上式中的





值得一提的是,
接下來,便是要證使得上式達到最小的

為求解上式,咱們先求
首先求

別忘了,
跟1.2節所述的誤差率的計算公式對比下:
可知,上面得到的
然後求
這個式子的後半部分可以進一步化簡,得:

接著將上面求得的
代入上式中,且對

這裏的
此外,毫無疑問,上式中的

即
就這樣,結合模型

從而有:

與上文1.2節介紹的權值更新公式

相比,只相差一個規範化因子,即後者多了一個
所以,整個過程下來,我們可以看到,前向分步算法逐一學習基函數的過程,確實是與Adaboost算法逐一學習各個基本分類器的過程一致,兩者完全等價。
綜上,本節不但提供了Adaboost的另一種理解:加法模型,損失函數為指數函數,學習算法為前向分步算法,而且也解釋了最開始1.2節中基本分類器
4 參考文獻與推薦閱讀
- wikipedia上關於Adaboost的介紹:http://zh.wikipedia.org/zh-cn/AdaBoost;
- 鄒博之決策樹與Adaboost PPT:http://pan.baidu.com/s/1hqePkdY;
- 鄒博講Adaboost指數損失函數推導的PPT:http://pan.baidu.com/s/1kTkkepD(第85頁~第98頁);
- 《統計學習方法 李航著》第8章;
- 關於adaboost的一些淺見:http://blog.sina.com.cn/s/blog_6ae183910101chcg.html;
- A Short Introduction to Boosting:http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.93.5148&rep=rep1&type=pdf;
- 南大周誌華教授做的關於boosting 25年的報告PPT:http://vdisk.weibo.com/s/FcILTUAi9m111;
- 《數據挖掘十大算法》第7章 Adaboost;
- http://summerbell.iteye.com/blog/532376;
- 統計學習那些事:http://cos.name/2011/12/stories-about-statistical-learning/;
- 統計學習基礎學習筆記:http://www.loyhome.com/%E2%89%AA%E7%BB%9F%E8%AE%A1%E5%AD%A6%E4%B9%A0%E7%B2%BE%E8%A6%81the-elements-of-statistical-learning%E2%89%AB%E8%AF%BE%E5%A0%82%E7%AC%94%E8%AE%B0%EF%BC%88%E5%8D%81%E5%9B%9B%EF%BC%89/;
- PRML第十四章組合模型讀書筆記:http://vdisk.weibo.com/s/DmxNcM5_IaUD;
- 順便推薦一個非常實用的在線編輯LaTeX 公式的網頁:http://www.codecogs.com/latex/eqneditor.php?lang=zh-cn。
遷移學習總結