
記生產服務器頻繁死機重大事故
曙光天闊I620
Vmware ESXI 6.5
虛機機操作系統:centos 6.9
raid 5
問題現象:
系統陸續出現斷續無法訪問的現象;nginx虛機、mysql虛機階段性頻繁宕機;無Dump日誌,kernel日誌無異常, message無錯誤信息;
問題排查過程
最開始我們懷疑是因為軟件程序的問題,所以最先查看了linux系統日誌,可是日誌中並沒有留下任何蛛絲馬跡。
然後我們又分析了nginx的access日誌和error日誌同樣一無所獲,之後根據訪問量打印出了top url,收集宕機之前的最後幾次請求進行比對,同樣沒有任何線索。宕機是沒有規律且隨機發生的事件。
考慮到業務量問題,我們緊接著對nginx所在虛擬機進行了內核優化,包括tcp等參數的調整,期望從這上面找到答案,並且從官方獲取到系統鏡像的md5進行校驗,然而宕機依舊發生,並且發生的時間都是訪問的高峰時期或者在磁盤負載很大的時候。主備機制雖然生效了,但是主機宕掉備機宕,為了保證系統正常運行,我們只能是靠人肉運維來支持。
所幸vmware是基於linux內核編寫的,為排查降低了一定的難度,但是我們對vmware沒有任何經驗,也只能是摸著石頭過河。
為了對系統運行情況有更全面的檢測,我們對Vmware ESX服務器系統軟件日誌進行了深入的分析。經分析我們在“vmkernel.log”文件中發現下列情況,磁盤陣列子系統系統響應不穩定。
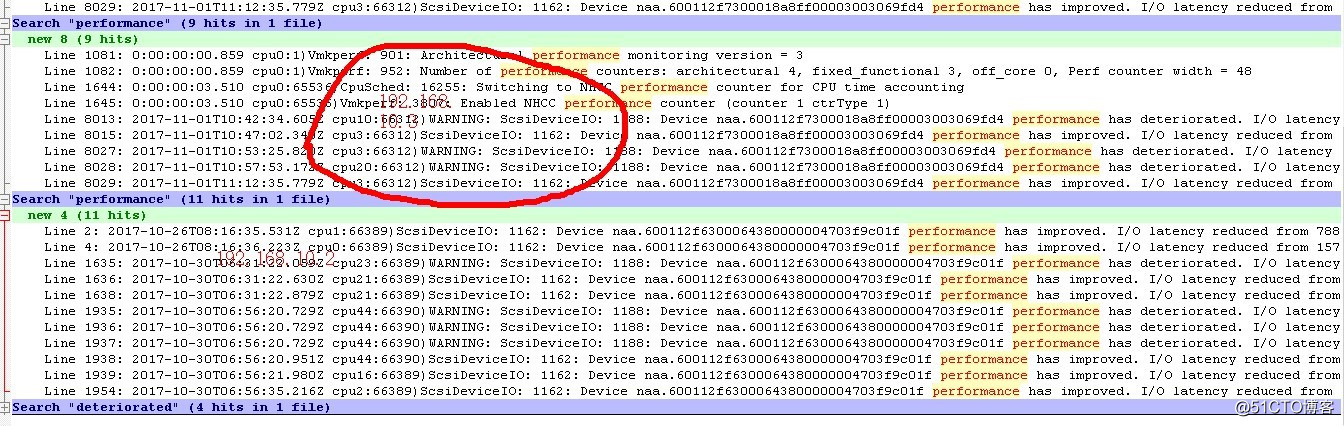
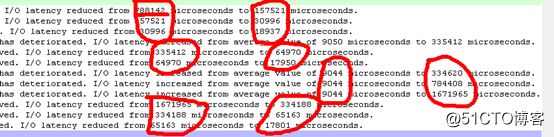
? 如下圖,磁盤陣列子系統延遲響應時間在9044到1671965微秒之間徘徊(根據經驗磁盤平均響應時間一般在30-40毫秒之間),最大延遲達到1.7秒:
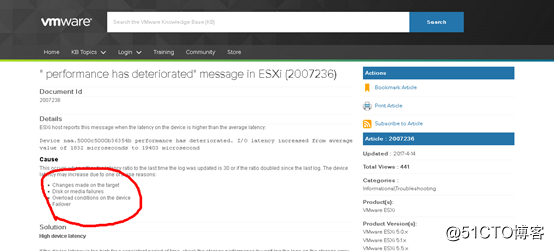
? 根據VMware官網相關資料介紹,出現響應延遲的主要原因有4種:A,硬件被改變了;B,磁盤介質有錯誤;C,出現高負載;D,容錯機制生效。在我們的環境下,唯一的可能性是B,即磁盤介質有錯誤或C,即由於某個磁盤介質出錯引起陣列中的容錯磁盤進行代償的容錯機制;
https://kb.vmware.com/s/article/2007236?language=en_US
? 為了證實我們的判斷,我們有針對系統對磁盤陣列子系統的請求情況進行進一步排查,磁盤陣列子系統("naa.600112f6300064380000004703f9c01f"即本機的磁盤陣列子系統)的請求出現1082次失敗。
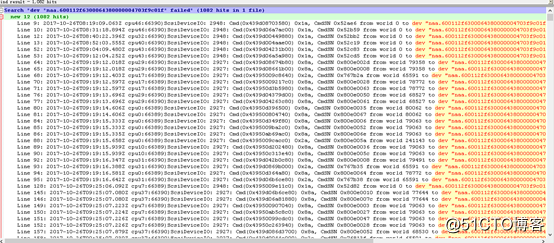
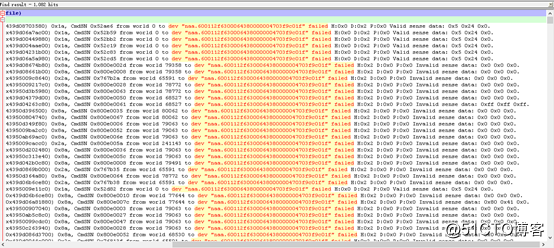
其中:磁盤陣列子系統返回H:0x2或D:0x2表示RAID卡或磁盤子系統沒有準備好,出現沒有準備好的原因可能有兩種:A,此時磁盤負荷較重;B,磁盤介質有錯誤。
經過對上述排查資料進行綜合分析,我們得出如下初步結論:
磁盤陣列子系統工作不穩定可能是造成近期系統間斷無法訪問的主要原因;
緊接著我們將如上結論反饋至服務器供應商,聯系到供應商後答復為可能是raid卡驅動對vmware不兼容造成的故障,新版本已經修復該問題。經過一系列的協商,我們在約定的時間停掉生產系統對raid卡驅動按照供應商的要求進行了一次升級。
第二天,我們將系統從新上線,當看到網頁出現時候我們充滿著澎湃和期望。
當系統穩定運行了幾天之後,本以為皆大歡喜我們終於解決了該問題,系統有一次宕機了。。。
我們又回到了原點,沒有線索沒有思緒,我們向供應商反饋可能硬件存在問題,但是由於種種原因供應商並不接受和承認我們的說法。
於是我們不得不從新分析vmwere日誌,在這之間我們向客戶請求購買官方技術支持或者更換戴爾服務器,客戶都以預算為由拒絕了。
緊接著又是一系列的壓力和排查!!!
我們懷疑過內存負載過大導致的該問題,於是將生產數臺虛機遷移到客戶測試環境上,由內存64G已使用60G降到已使用45G進行觀察,故障依舊。。。。
這時候我們突然想到,虛擬機是由kvm的qcow2鏡像轉至成vmdk鏡像的,會不會和這有關,於是我們開始對虛機的加載日誌進行分析。
在這之中我們發現了一個詭異的信息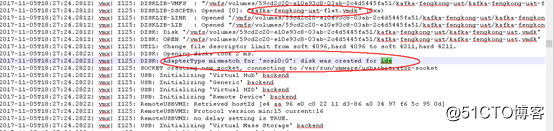
虛擬機磁盤的接口定義為“ide“,而不是VMwareESX上定義的“SCSI“接口,即接口定義不匹配。
原因是由於所有虛擬機磁盤文件都是從公司內部的KVM虛擬機文件移植過來,在創建虛機的時候選擇了默認的接口格式ide。
根據官方資料,ESXI 6.5版本並不支持IDE模式的接口,我們仿佛找到了突破口,緊接著我們網上搜索資料進行修改
http://blog.sina.com.cn/s/blog_7120c0be0101exol.html
根據上面鏈接的教程,我們對虛機進行了修改並且經過測試,該修改對虛機無影響,於是我們在夜裏對生產虛機進行了修改。
事與願違,希望越大失望越大。經過一周的測試,故障依舊。。。
最終的解決辦法:
幸運的是,虛擬機宕機後有很大的幾率會馬上重新啟動起來,nginx我們用keepalived做了高可用,並且通過腳本和zabbix進行監控和故障轉移。即使宕機,對生產並沒有很直觀的影響。數據庫虛機也會重啟,但是從來都是在夜裏,因為夜裏做大量的數據處理。
最終總結:
到目前為止該故障還會偶爾的出現,我們並沒有找到根本原因,其他服務的機器也會宕機(所有服務器都有負載均衡或者高可用),但是不如nginx和mysql頻繁。
我們最終懷疑的兩個方向:1,硬盤問題 2,鏡像轉制問題
但是如上的懷疑也是猜測,我們無法找到有力的證據證明,並且也沒有權利要求更換硬件。
最最終總結:
我們在切換虛機硬盤接口格式的時候,由於快照問題,又發生了重大的生產事故,一系列的小偏差導致了最終的結果“重要生產數據丟失”。不過最終我們拯救了回來,這件事也是我運維生涯中的一次大事記了。這個故事我將會寫在另外的文章裏。
rc.local在某些特殊情況下並不靠譜不靠譜不靠譜,重要的事情說三遍,在未知原因宕機的時候,我們發現rc.local中的命令並沒有被執行,但是在正常啟動或者重啟的時候又可以正常執行裏面的啟動命令。最終我們將服務都修改為用chkconfig來管理。
記生產服務器頻繁死機重大事故