
盤點Kubernetes網絡問題的4種解決方案
一、Kubernetes + Flannel
Kubernetes的網絡模型假定了所有Pod都在一個可以直接連通的扁平的網絡空間中,這在GCE(Google Compute Engine)裏面是現成的網絡模型,Kubernetes假定這個網絡已經存在。而在私有雲裏搭建Kubernetes集群,就不能假定這個網絡已經存在了。我們需要自己實現這個網絡假設,將不同節點上的Docker容器之間的互相訪問先打通,然後運行Kubernetes。
Flannel是CoreOS團隊針對Kubernetes設計的一個網絡規劃服務,簡單來說,它的功能是讓集群中的不同節點主機創建的Docker容器都具有全集群唯一的虛擬IP地址。而且它還能在這些IP地址之間建立一個覆蓋網絡(Overlay Network),通過這個覆蓋網絡,將數據包原封不動地傳遞到目標容器內。
下面是一張它的網絡原理圖: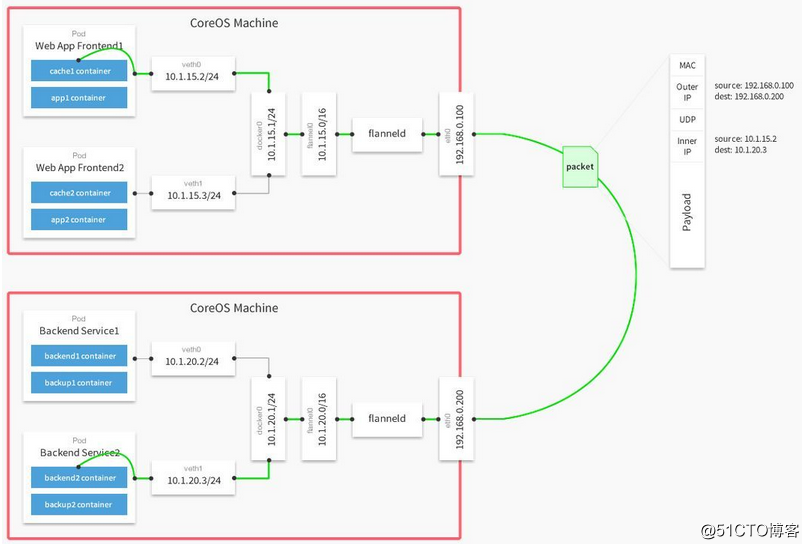
可以看到,Flannel首先創建了一個名為flannel0的網橋,而且這個網橋的一端連接docker0的網橋,另一端連接一個名為flanneld的服務進程。
Flanneld進程並不簡單,它首先上連etcd,利用etcd來管理可分配的IP地址段資源,同時監控etcd中每個Pod的實際地址,並在內存中建立了一個Pod節點路由表;然後下連docker0和物理網絡,使用內存中的Pod節點路由表,將docker0發給它的數據包包裝起來,利用物理網絡的連接將數據包投遞到目標flanneld上,從而完成pod到pod之間的直接的地址通信。
Flannel之間的底層通信協議的可選余地有很多,比如UDP、VXlan、AWS VPC等等。只要能通到對端的Flannel就可以了。源Flannel封包,目標Flannel解包,最終docker0看到的就是原始的數據,非常透明,根本感覺不到中間Flannel的存在。
Flannel的安裝配置網上講的很多,在這裏就不在贅述了。在這裏註意一點,就是flannel使用etcd作為數據庫,所以需要預先安裝好etcd。
下面說說幾個場景:
-
同一Pod內的網絡通信。在同一個Pod內的容器共享同一個網絡命名空間,共享同一個Linux協議棧。所以對於網絡的各類操作,就和它們在同一臺機器上一樣,它們可以用localhost地址直接訪問彼此的端口。其實這和傳統的一組普通程序運行的環境是完全一樣的,傳統的程序不需要針對網絡做特別的修改就可以移植了。這樣做的結果是簡單、安全和高效,也能減少將已經存在的程序從物理機或者虛擬機移植到容器下運行的難度。
-
Pod1到Pod2的網絡,分兩種情況。Pod1與Pod2不在同一臺主機與Pod1與Pod2在同一臺主機。
先說Pod1與Pod2不在同一臺主機。Pod的地址是與docker0在同一個網段的,但docker0網段與宿主機網卡是兩個完全不同的IP網段,並且不同Node之間的通信只能通過宿主機的物理網卡進行。將Pod的IP和所在Node的IP關聯起來,通過這個關聯讓Pod可以互相訪問。
Pod1與Pod2在同一臺主機。Pod1和Pod2在同一臺主機的話,由Docker0網橋直接轉發請求到Pod2,不需要經過Flannel。 -
Pod到Service的網絡。創建一個Service時,相應會創建一個指向這個Service的域名,域名規則為{服務名}.{namespace}.svc.{集群名稱}。之前Service IP的轉發由iptables和kube-proxy負責,目前基於性能考慮,全部為iptables維護和轉發。iptables則由kubelet維護。Service僅支持UDP和TCP協議,所以像ping的ICMP協議是用不了的,所以無法ping通Service IP。
-
Pod到外網。Pod向外網發送請求,查找路由表, 轉發數據包到宿主機的網卡,宿主網卡完成路由選擇後,iptables執行Masquerade,把源IP更改為宿主網卡的IP,然後向外網服務器發送請求。
- 集群外部訪問Pod或Service
由於Pod和Service是Kubernetes集群範圍內的虛擬概念,所以集群外的客戶端系統無法通過Pod的IP地址或者Service的虛擬IP地址和虛擬端口號訪問到它們。為了讓外部客戶端可以訪問這些服務,可以將Pod或Service的端口號映射到宿主機,以使得客戶端應用能夠通過物理機訪問容器應用。
總結:Flannel實現了對Kubernetes網絡的支持,但是它引入了多個網絡組件,在網絡通信時需要轉到flannel0網絡接口,再轉到用戶態的flanneld程序,到對端後還需要走這個過程的反過程,所以也會引入一些網絡的時延損耗。另外Flannel默認的底層通信協議是UDP。UDP本身是非可靠協議,雖然兩端的TCP實現了可靠傳輸,但在大流量、高並發應用場景下還需要反復調試,確保不會出現傳輸質量的問題。特別是對網絡依賴重的應用,需要評估對業務的影響。
二、基於Docker Libnetwork的網絡定制
容器跨主機的網絡通信,主要實現思路有兩種:二層VLAN網絡和Overlay網絡。
二層VLAN網絡的解決跨主機通信的思路是把原先的網絡架構改造為互通的大二層網絡,通過特定網絡設備直接路由,實現容器點到點的之間通信。
Overlay網絡是指在不改變現有網絡基礎設施的前提下,通過某種約定通信協議,把二層報文封裝在IP報文之上的新的數據格式。Libnetwork是Docker團隊將Docker的網絡功能從Docker核心代碼中分離出去,形成一個單獨的庫。 Libnetwork通過插件的形式為Docker提供網絡功能。 使得用戶可以根據自己的需求實現自己的Driver來提供不同的網絡功能。
Libnetwork所要實現的網絡模型基本是這樣的: 用戶可以創建一個或多個網絡(一個網絡就是一個網橋或者一個VLAN ),一個容器可以加入一個或多個網絡。 同一個網絡中容器可以通信,不同網絡中的容器隔離。這才是將網絡從docker分離出去的真正含義,即在創建容器之前,我們可以先創建網絡(即創建容器與創建網絡是分開的),然後決定讓容器加入哪個網絡。
Libnetwork實現了5種網絡模式:
1、 bridge:Docker默認的容器網絡驅動,Container通過一對veth pair鏈接到docker0網橋上,由Docker為容器動態分配IP及配置路由、防火墻等。
2、host:容器與主機共享同一Network Namespace。
3、 null:容器內網絡配置為空,需要用戶手動為容器配置網絡接口及路由。
4、 remote:Docker網絡插件的實現,Remote driver使得Libnetwork可以通過HTTP Resful API 對接第三方的網絡方案,類似於SocketPlane的SDN方案只要實現了約定的HTTP URL處理函數以及底層的網絡接口配置方法,就可以替代Docker原生的網絡實現。
5、 overlay:Docker原生的跨主機多子網網絡方案。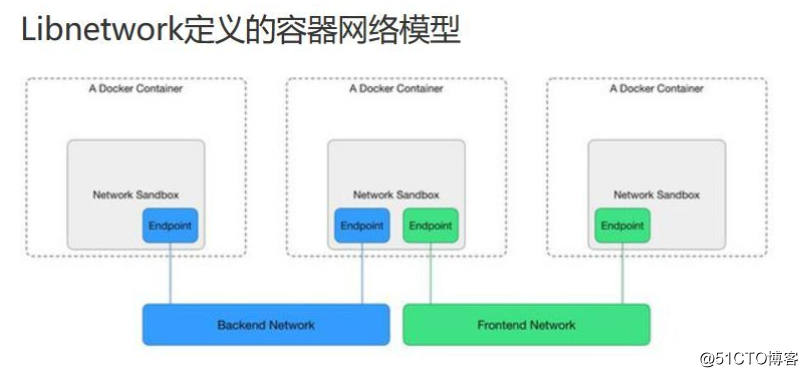
Docker自身的網絡功能比較簡單,不能滿足很多復雜的應用場景。因此,有很多開源項目用來改善Docker的網絡功能,如Pipework、Weave、SocketPlane等。
舉例:網絡配置工具Pipework
Pipework是一個簡單易用的Docker容器網絡配置工具。由200多行shell腳本實現。通過使用IP、brctl、ovs-vsctl等命令來為Docker容器配置自定義的網橋、網卡、路由等。有如下功能:
支持使用自定義的Linux Bridge、veth pair為容器提供通信。
支持使用MacVLAN設備將容器連接到本地網絡。
支持DHCP獲取容器的IP。
支持Open vSwitch。
支持VLAN劃分。Pipework簡化了在復雜場景下對容器連接的操作命令,為我們配置復雜的網絡拓撲提供了一個強有力的工具。對於一個基本應用而言,Docker的網絡模型已經很不錯了。然而,隨著雲計算和微服務的興起,我們不能永遠停留在使用基本應用的級別上,我們需要性能更好且更靈活的網絡功能。Pipework是個很好的網絡配置工具,但Pipework並不是一套解決方案,我們可以利用它提供的強大功能,根據自己的需求添加額外的功能,幫助我們構建自己的解決方案。
OVS跨主機多子網網絡方案
OVS的優勢是,作為開源虛擬交換機軟件,它相對成熟和穩定,而且支持各類網絡隧道協議,經過了OpenStack等項目的考驗。這個網上很多,就不再贅述了。
三、Kubernetes集成Calico
Calico是一個純3層的數據中心網絡方案,而且無縫集成像OpenStack這種IaaS雲架構,能夠提供可控的VM、容器、裸機之間的IP通信。
通過將整個互聯網的可擴展IP網絡原則壓縮到數據中心級別,Calico在每一個計算節點利用Linux Kernel實現了一個高效的vRouter來負責數據轉發,而每個vRouter通過BGP協議負責把自己上運行的workload的路由信息像整個Calico網絡內傳播——小規模部署可以直接互聯,大規模下可通過指定的BGP route reflector來完成。這樣保證最終所有的workload之間的數據流量都是通過IP路由的方式完成互聯的。
Calico節點組網可以直接利用數據中心的網絡結構(無論是L2或者L3),不需要額外的NAT,隧道或者Overlay Network。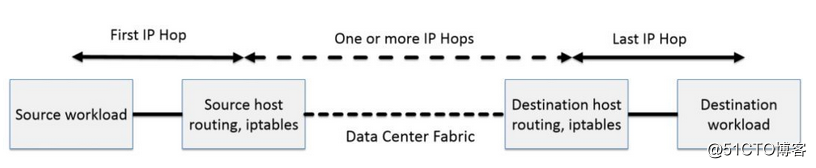
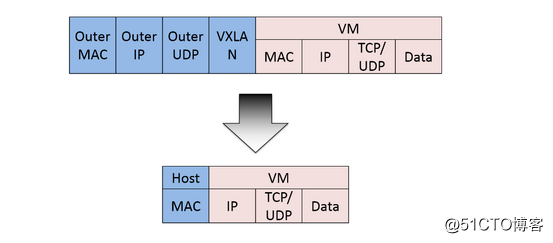
Calico基於iptables還提供了豐富而靈活的網絡Policy,保證通過各個節點上的ACLs來提供Workload的多租戶隔離、安全組以及其他可達性限制等功能。
Calico有兩種布署方案,一般集群都配有SSL證書和非證書的情況。
第一種無HTTPS連接etcd方案,HTTP模式部署即沒有證書,直接連接etcd
第二種HTTPS連接etcd集群方案,加載etcd https證書模式,有點麻煩總結:目前Kubernetes網絡最快的第一就是Calico,第二種稍慢Flannel,根據自己的網絡環境條件來定。
calico與flannel的對比:
下圖是從網上找到的各個開源網絡組件的性能對比,可以看出無論是帶寬還是網絡延遲,calico和主機的性能是差不多的,calico是明顯優於flannel的。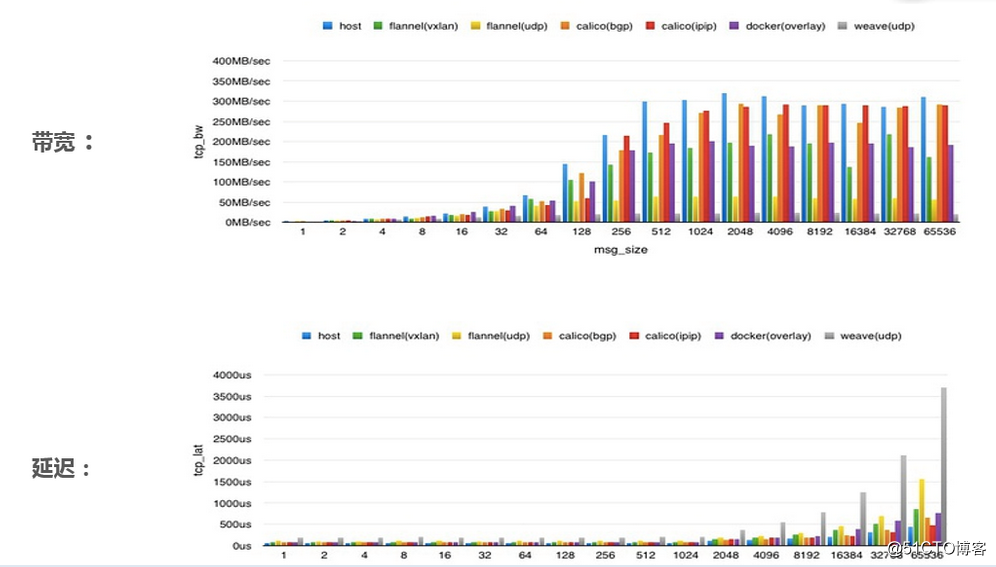
Calico作為一款針對企業級數據中心的虛擬網絡工具,借助BGP、路由表和iptables,實現了一個無需解包封包的三層網絡,並且有調試簡單的特點。雖然目前還有些小缺陷,比如stable版本還無法支持私有網絡,但希望在後面的版本中改進並會更加強大。
四、應用容器IP固定(參考網上資料)
Docker 1.9開始支持Contiv Netplugin,Contiv帶來的方便是用戶可以根據實例IP直接進行訪問。
Docker 1.10版本支持指定IP啟動容器,並且由於部分數據庫應用對實例IP固定有需求,有必要研究容器IP固定方案的設計。
在默認的Kubernetes + Contiv的網絡環境下,容器Pod的IP網絡連接是由Contiv Network Plugin來完成的,Contiv Master只實現了簡單的IP地址分配和回收,每次部署應用時,並不能保證Pod IP不變。所以可以考慮引入新的Pod層面的IPAM(IP地址管理插件),以保證同一個應用多次發生部署時,Pod IP始終是不變的。
作為Pod層面的IPAM,可以把這一功能直接集成在Kubernetes裏。Pod作為Kubernetes的最小調度單元,原有的Kubernetes Pod Registry(主要負責處理所有與Pod以及Pod subresource相關的請求:Pod的增刪改查,Pod的綁定及狀態更新,exec/attach/log等操作)並不支持在創建Pod時為Pod分配IP,Pod IP是通過獲取Pod Infra Container的IP來獲取的,而Pod Infra Container的IP即為Contiv動態分配得來的。
在原有Kubernetes代碼基礎上,修改Pod結構(在PodSpec中加入PodIP)並重寫了Pod Registry同時引入了兩個新的資源對象:
Pod IP Allocator:Pod IP Allocator是一個基於etcd的IP地址分配器,主要實現Pod IP的分配與回收。Pod IP Allocator通過位圖記錄IP地址的分配情況,並且將該位圖持久化到etcd;
Pod IP Recycler:Pod IP Recycler是一個基於etcd的IP地址回收站,也是實現PodConsistent IP的核心。Pod IP Recycler基於RC全名(namespace + RC name)記錄每一個應用曾經使用過的IP地址,並且在下一次部署的時候預先使用處於回收狀態的IP。Pod IP Recycler只會回收通過RC創建的Pod的IP,通過其他controller或者直接創建的Pod的IP並不會記錄,所以通過這種方式創建的Pod的IP並不會保持不變;同時Pod IP Recycle檢測每個已回收IP對象的TTL,目前設置的保留時間為一天。這裏對kubelet也需要進行改造,主要包括根據Pod Spec中指定IP進行相關的容器創建(docker run加入IP指定)以及Pod刪除時釋放IP操作。
Pod的創建在PaaS裏主要有兩種情形:
應用的第一次部署及擴容,這種情況主要是從IP pool中隨機分配;
應用的重新部署:在重新部署時,已經釋放的IP已根據RC全名存放於IP Recycle列表中,這裏優先從回收列表中獲取IP,從而達到IP固定的效果。另外為了防止IP固定方案中可能出現的問題,在Kubernetes中加入了額外的REST API:包括對已分配IP的查詢,手動分配/釋放IP。
容器IP固定方案已測試評估中,運行基本上沒問題,但穩定性有待提升。主要表現在有時不能在預期時間內停止舊Pod,從而無法釋放IP造成無法復用(初步原因是由於Docker偶爾的卡頓造成無法在規定時間內停止容器),可以手動去修復。但從長期考慮,IP固定方案還需要加強穩定性並根據具體需求進行優化。
總結:目前已有多種支持Kubernetes的網絡方案,比如Flannel、Calico、華為的Canal、Weave Net等。因為它們都實現了CNI規範,用戶無論選擇哪種方案,得到的網絡模型都一樣,即每個Pod都有獨立的 IP,可以直接通信。區別在於不同方案的底層實現不同,有的采用基於VXLAN的Overlay實現,有的則是Underlay,性能上有區別,再有就是是否支持Network Policy了。
盤點Kubernetes網絡問題的4種解決方案