
MySQL底層索引剖析

1:Mysql索引是什麽
mysql索引: 是一種幫助mysql高效的獲取數據的數據結構,這些數據結構以某種方式引用數據,這種結構就是索引。可簡單理解為排好序的快速查找數據結構。如果要查“mysql”這個單詞,我們肯定需要定位到m字母,然後從下往下找到y字母,再找到剩下的sql。
1.1:索引分類
單值索引:一個索引包含1個列 create index idx_XX on table(f1) 一個表可以建多個。 唯一索引: 索引列的值必須唯一,但允許有空值 create unique index idx_XX on table(f1) 復合索引: 一個索引包含多個列 如:create index idx_XX on table(f1,f2,..)
1.2:索引結構
BTree Hash索引 full-text全文索引:
1.3:什麽情況建立索引
主鍵自動建立唯一索引 頻繁作為查詢條件的字段因該創建索引 查詢中與其他表關聯的字段,外鍵關系建立索引 頻繁更新的字段不適合建立索引 where條件裏用不到的字段不建立索引 單鍵/復合索引的選擇(高並發下傾向復合) 查詢中排序的字段因建立索引 查詢中統計或分組字段
1.4:什麽情況建不建立索引
頻繁增刪改的表 表記錄太少 數據重復且分布平均的表字段。(重復太多索引意義不大)
2:Mysql索引為什麽要用B+Tree實現
2.1:B+樹在數據庫索引中的應用
目前大部分數據庫系統及文件系統都采用B-Tree或其變種B+Tree作為索引結構
1)在數據庫索引的應用
在數據庫索引的應用中,B+樹按照下列方式進行組織 :
① 葉結點的組織方式 。B+樹的查找鍵 是數據文件的主鍵 ,且索引是稠密的。也就是說 ,葉結點 中為數據文件的第一個記錄設有一個鍵、指針對 ,該數據文件可以按主鍵排序,也可以不按主鍵排序 ;數據文件按主鍵排序,且 B +樹是稀疏索引 , 在葉結點中為數據文件的每一個塊設有一個鍵、指針對 ;數據文件不按鍵屬性排序 ,且該屬性是 B +樹 的查找鍵 , 葉結點中為數據文件裏出現的每個屬性K設有一個鍵 、 指針對 , 其中指針執行排序鍵值為 K的 記錄中的第一個。
② 非葉結點 的組織方式。B+樹 中的非葉結點形成 了葉結點上的一個多級稀疏索引。 每個非葉結點中至少有ceil( m/2 ) 個指針 , 至多有 m 個指針 。
2)B+樹索引的插入和刪除
①在向數據庫中插入新的數據時,同時也需要向數據庫索引中插入相應的索引鍵值 ,則需要向 B+樹 中插入新的鍵值。即上面我們提到的B-樹插入算法。
②當從數據庫中刪除數據時,同時也需要從數據庫索引中刪除相應的索引鍵值 ,則需要從 B+樹 中刪 除該鍵值 。即B-樹刪除算法
2.2: 索引在數據庫中的作用
在數據庫系統的使用過程當中,數據的查詢是使用最頻繁的一種數據操作。
最基本的查詢算法當然是順序查找(linear search),遍歷表然後逐行匹配行值是否等於待查找的關鍵字,其時間復雜度為O(n)。但時間復雜度為O(n)的算法規模小的表,負載輕的數據庫,也能有好的性能。 但是數據增大的時候,時間復雜度為O(n)的算法顯然是糟糕的,性能就很快下降了。
好在計算機科學的發展提供了很多更優秀的查找算法,例如二分查找(binary search)、二叉樹查找(binary tree search)等。如果稍微分析一下會發現,每種查找算法都只能應用於特定的數據結構之上,例如二分查找要求被檢索數據有序,而二叉樹查找只能應用於二叉查找樹上,但是數據本身的組織結構不可能完全滿足各種數據結構(例如,理論上不可能同時將兩列都按順序進行組織),所以,在數據之外,數據庫系統還維護著滿足特定查找算法的數據結構,這些數據結構以某種方式引用(指向)數據,這樣就可以在這些數據結構上實現高級查找算法。這種數據結構,就是索引。
索引是對數據庫表 中一個或多個列的值進行排序的結構。與在表 中搜索所有的行相比,索引用指針 指向存儲在表中指定列的數據值,然後根據指定的次序排列這些指針,有助於更快地獲取信息。通常情 況下 ,只有當經常查詢索引列中的數據時 ,才需要在表上創建索引。索引將占用磁盤空間,並且影響數 據更新的速度。但是在多數情況下 ,索引所帶來的數據檢索速度優勢大大超過它的不足之處。
2.3:為什麽使用B-Tree(B+Tree)
1.文件很大,不可能全部存儲在內存中,故要存儲到磁盤上
2.索引的結構組織要盡量減少查找過程中磁盤I/O的存取次數(為什麽使用B-/+Tree,還跟磁盤存取原理有關。)
3.局部性原理與磁盤預讀,預讀的長度一般為頁(page)的整倍數,(在許多操作系統中,頁得大小通常為4k)
4.數據庫系統巧妙利用了磁盤預讀原理,將一個節點的大小設為等於一個頁,這樣每個節點只需要一次I/O就可以完全載入,(由於節點中有兩個數組,所以地址連續)。而紅黑樹這種結構,h明顯要深的多。由於邏輯上很近的節點(父子)物理上可能很遠,無法利用局部性
二叉查找樹進化品種的紅黑樹等數據結構也可以用來實現索引,但是文件系統及數據庫系統普遍采用B-/+Tree作為索引結構。
一般來說,索引本身也很大,不可能全部存儲在內存中,因此索引往往以索引文件的形式存儲的磁盤上。這樣的話,索引查找過程中就要產生磁盤I/O消耗,相對於內存存取,I/O存取的消耗要高幾個數量級,所以評價一個數據結構作為索引的優劣最重要的指標就是在查找過程中磁盤I/O操作次數的漸進復雜度。換句話說,索引的結構組織要盡量減少查找過程中磁盤I/O的存取次數。為什麽使用B-/+Tree,還跟磁盤存取原理有關。
局部性原理與磁盤預讀
由於存儲介質的特性,磁盤本身存取就比主存慢很多,再加上機械運動耗費,磁盤的存取速度往往是主存的幾百分分之一,因此為了提高效率,要盡量減少磁盤I/O。為了達到這個目的,磁盤往往不是嚴格按需讀取,而是每次都會預讀,即使只需要一個字節,磁盤也會從這個位置開始,順序向後讀取一定長度的數據放入內存。這樣做的理論依據是計算機科學中著名的局部性原理:
當一個數據被用到時,其附近的數據也通常會馬上被使用。
程序運行期間所需要的數據通常比較集中。
由於磁盤順序讀取的效率很高(不需要尋道時間,只需很少的旋轉時間),因此對於具有局部性的程序來說,預讀可以提高I/O效率。
預讀的長度一般為頁(page)的整倍數。頁是計算機管理存儲器的邏輯塊,硬件及操作系統往往將主存和磁盤存儲區分割為連續的大小相等的塊,每個存儲塊稱為一頁(在許多操作系統中,頁得大小通常為4k),主存和磁盤以頁為單位交換數據。當程序要讀取的數據不在主存中時,會觸發一個缺頁異常,此時系統會向磁盤發出讀盤信號,磁盤會找到數據的起始位置並向後連續讀取一頁或幾頁載入內存中,然後異常返回,程序繼續運行。
我們上面分析B-/+Tree檢索一次最多需要訪問節點:
h =
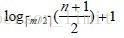
數據庫系統巧妙利用了磁盤預讀原理,將一個節點的大小設為等於一個頁,這樣每個節點只需要一次I/O就可以完全載入。為了達到這個目的,在實際實現B- Tree還需要使用如下技巧:
每次新建節點時,直接申請一個頁的空間,這樣就保證一個節點物理上也存儲在一個頁裏,加之計算機存儲分配都是按頁對齊的,就實現了一個node只需一次I/O。
B-Tree中一次檢索最多需要h-1次I/O(根節點常駐內存),漸進復雜度為O(h)=O(logmN)。一般實際應用中,m是非常大的數字,通常超過100,因此h非常小(通常不超過3)。
綜上所述,用B-Tree作為索引結構效率是非常高的。
而紅黑樹這種結構, h 明顯要深的多。由於邏輯上很近的節點(父子)物理上可能很遠,無法利用局部性,所以紅黑樹的I/O漸進復雜度也為O(h),效率明顯比B-Tree差很多。
3:Mysql索引如何實現
1)主鍵索引:
MyISAM引擎使用B+Tree作為索引結構,葉節點的data域存放的是數據記錄的地址。下圖是MyISAM主鍵索引的原理圖:
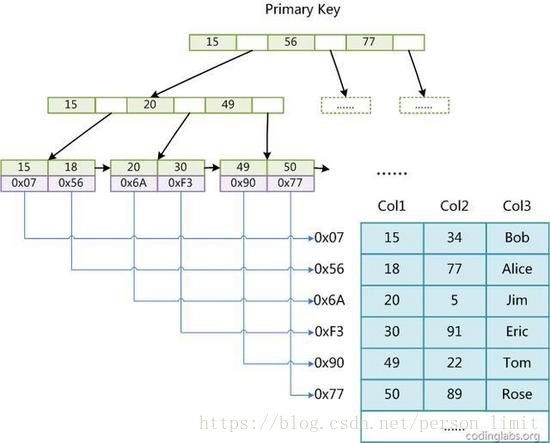
這裏設表一共有三列,假設我們以Col1為主鍵,圖myisam1是一個MyISAM表的主索引(Primary key)示意。可以看出MyISAM的索引文件僅僅保存數據記錄的地址。
2)輔助索引(Secondary key)
在MyISAM中,主索引和輔助索引(Secondary key)在結構上沒有任何區別,只是主索引要求key是唯一的,而輔助索引的key可以重復。 如果我們在Col2上建立一個輔助索引,則此索引的結構如下圖所示:
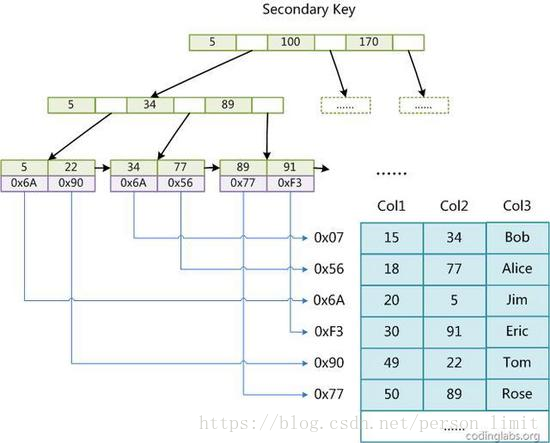
同樣也是一顆B+Tree,data域保存數據記錄的地址。因此,MyISAM中索引檢索的算法為首先按照B+Tree搜索算法搜索索引,如果指定的Key存在,則取出其data域的值,然後以data域的值為地址,讀取相應數據記錄 。
MyISAM的索引方式也叫做“非聚集”的,之所以這麽稱呼是為了與InnoDB的聚集索引區分。
4:InnoDB索引實現
雖然InnoDB也使用B+Tree作為索引結構,但具體實現方式卻與MyISAM截然不同。
第一個重大區別是InnoDB的數據文件本身就是索引文件。從上文知道,MyISAM索引文件和數據文件是分離的,索引文件僅保存數據記錄的地址。而在InnoDB中,表數據文件本身就是按B+Tree組織的一個索引結構,這棵樹的葉節點data域保存了完整的數據記錄。這個索引的key是數據表的主鍵,因此InnoDB表數據文件本身就是主索引。
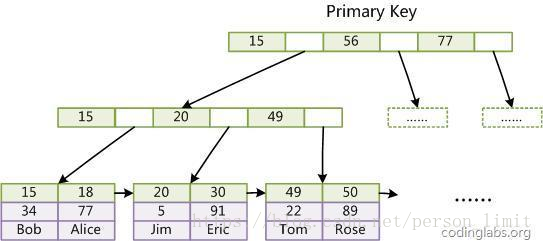
上圖是InnoDB主索引(同時也是數據文件)的示意圖,可以看到葉節點包含了完整的數據記錄。這種索引叫做聚集索引。因為InnoDB的數據文件本身要按主鍵聚集,所以InnoDB要求表必須有主鍵(MyISAM可以沒有),如果沒有顯式指定,則MySQL系統會自動選擇一個可以唯一標識數據記錄的列作為主鍵,如果不存在這種列,則MySQL自動為InnoDB表生成一個隱含字段作為主鍵,這個字段長度為6個字節,類型為長×××。
第二個與MyISAM索引的不同是InnoDB的輔助索引data域存儲相應記錄主鍵的值而不是地址。換句話說,InnoDB的所有輔助索引都引用主鍵作為data域。例如,下圖為定義在Col3上的一個輔助索引:
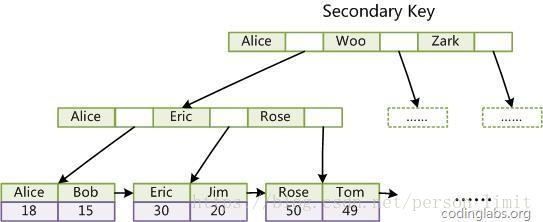
這裏以英文字符的ASCII碼作為比較準則。聚集索引這種實現方式使得按主鍵的搜索十分高效,但是輔助索引搜索需要檢索兩遍索引:首先檢索輔助索引獲得主鍵,然後用主鍵到主索引中檢索獲得記錄。
了解不同存儲引擎的索引實現方式對於正確使用和優化索引都非常有幫助,例如知道了InnoDB的索引實現後,就很容易明白為什麽不建議使用過長的字段作為主鍵,因為所有輔助索引都引用主索引,過長的主索引會令輔助索引變得過大。再例如,用非單調的字段作為主鍵在InnoDB中不是個好主意,因為InnoDB數據文件本身是一顆B+Tree,非單調的主鍵會造成在插入新記錄時數據文件為了維持B+Tree的特性而頻繁的分裂調整,十分低效,而使用自增字段作為主鍵則是一個很好的選擇。
5:程序員進階方法
以上是我總結出的Mysql索引底層數據結構剖析,但在此,我還想給大家一種學習方法,讓大家不單單在理論有所收獲,還能在工作實踐中收獲更多。我推薦的這種方法。
不管你是面對目前流行的技術不知從何下手,需要突破技術瓶頸的可以學。
不管你是在公司待久了,過得很安逸,但跳槽時面試碰壁。需要在短時間內進修、跳槽拿高薪的可以學。
不管你是沒有工作經驗,但基礎非常紮實,對java工作機制,常用設計思想,常用java開發框架掌握熟練的,可以學。(小白就不要學了,先學好基礎)
不管你是覺得自己很牛B,一般需求都能搞定。但是所學的知識點沒有系統化,很難在技術領域繼續突破的可以學。
在此我向大家推薦一個交流學習群:650385180(加群可以學習程序員進階方法) 裏面會分享一些資深架構師錄制的視頻錄像:有Spring,MyBatis,Netty源碼分析,高並發、高性能、分布式、微服務架構的原理,JVM性能優化這些成為架構師必備的知識體系。還能領取免費的學習資源,目前受益良多,下面的高清知識腦圖也會在群的共享區裏面免費分享出來。

MySQL底層索引剖析