
螞蟻技術專家:一篇文章帶你學習分布式事務
分布式事務是企業集成中的一個技術難點,也是每一個分布式系統架構中都會涉及到的一個東西,特別是在這幾年越來越火的微服務架構中,幾乎可以說是無法避免,本文就圍繞分布式事務各方面與大家進行介紹。
一. 事務
1.1 什麽是事務
數據庫事務(簡稱:事務,Transaction)是指數據庫執行過程中的一個邏輯單位,由一個有限的數據庫操作序列構成。
事務擁有以下四個特性,習慣上被稱為ACID特性:
原子性(Atomicity):事務作為一個整體被執行,包含在其中的對數據庫的操作要麽全部被執行,要麽都不執行。
一致性(Consistency):事務應確保數據庫的狀態從一個一致狀態轉變為另一個一致狀態。一致狀態是指數據庫中的數據應滿足完整性約束。除此之外,一致性還有另外一層語義,就是事務的中間狀態不能被觀察到(這層語義也有說應該屬於原子性)。
隔離性(Isolation):多個事務並發執行時,一個事務的執行不應影響其他事務的執行,如同只有這一個操作在被數據庫所執行一樣。
持久性(Durability):已被提交的事務對數據庫的修改應該永久保存在數據庫中。在事務結束時,此操作將不可逆轉。
1.2 本地事務
起初,事務僅限於對單一數據庫資源的訪問控制:
架構服務化以後,事務的概念延伸到了服務中。倘若將一個單一的服務操作作為一個事務,那麽整個服務操作只能涉及一個單一的數據庫資源:
這類基於單個服務單一數據庫資源訪問的事務,被稱為本地事務(Local Transaction)。
二. 分布式事務應用架構
本地事務主要限制在單個會話內,不涉及多個數據庫資源。但是在基於SOA(Service-Oriented Architecture,面向服務架構)的分布式應用環境下,越來越多的應用要求對多個數據庫資源,多個服務的訪問都能納入到同一個事務當中,分布式事務應運而生。
最早的分布式事務應用架構很簡單,不涉及服務間的訪問調用,僅僅是服務內操作涉及到對多個數據庫資源的訪問。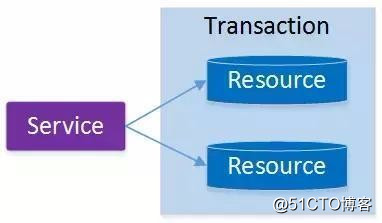
當一個服務操作訪問不同的數據庫資源,又希望對它們的訪問具有事務特性時,就需要采用分布式事務來協調所有的事務參與者。
對於上面介紹的分布式事務應用架構,盡管一個服務操作會訪問多個數據庫資源,但是畢竟整個事務還是控制在單一服務的內部。如果一個服務操作需要調用另外一個服務,這時的事務就需要跨越多個服務了。在這種情況下,起始於某個服務的事務在調用另外一個服務的時候,需要以某種機制流轉到另外一個服務,從而使被調用的服務訪問的資源也自動加入到該事務當中來。下圖反映了這樣一個跨越多個服務的分布式事務: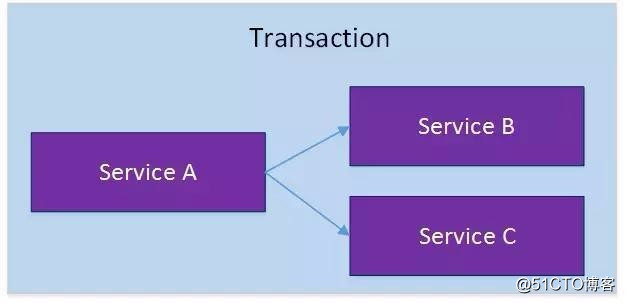
如果將上面這兩種場景(一個服務可以調用多個數據庫資源,也可以調用其他服務)結合在一起,對此進行延伸,整個分布式事務的參與者將會組成如下圖所示的樹形拓撲結構。在一個跨服務的分布式事務中,事務的發起者和提交均系同一個,它可以是整個調用的客戶端,也可以是客戶端最先調用的那個服務。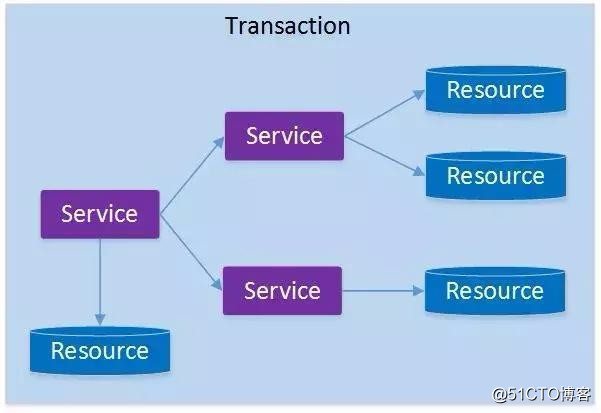
較之基於單一數據庫資源訪問的本地事務,分布式事務的應用架構更為復雜。在不同的分布式應用架構下,實現一個分布式事務要考慮的問題並不完全一樣,比如對多資源的協調、事務的跨服務傳播等,實現機制也是復雜多變。盡管有這麽多工程細節需要考慮,但分布式事務最核心的還是其 ACID 特性。因此,想要了解一個分布式事務,就先從了解它是怎麽實現事務 ACID 特性開始。
下文將從兩個最常見的分布式事務模型入手,著重分析分布式事務的基礎共通點,即如何保證分布式事務的 ACID 特性。
三. 常見分布式事務模型 ACID 實現分析
3.1 X/Open XA 協議
最早的分布式事務模型是 X/Open 國際聯盟提出的 X/Open Distributed Transaction Processing(DTP)模型,也就是大家常說的 X/Open XA 協議,簡稱XA 協議。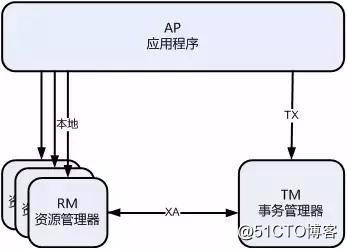
DTP 模型中包含一個全局事務管理器(TM,Transaction Manager)和多個資源管理器(RM,Resource Manager)。全局事務管理器負責管理全局事務狀態與參與的資源,協同資源一起提交或回滾;資源管理器則負責具體的資源操作。
XA 協議描述了 TM 與 RM 之間的接口,允許多個資源在同一分布式事務中訪問。
基於 DTP 模型的分布式事務流程大致如下: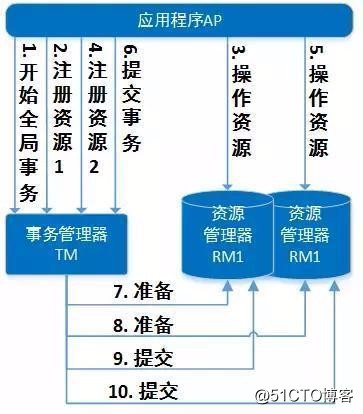
1.應用程序(AP,Application)向 TM 申請開始一個全局事務。
2.針對要操作的 RM,AP 會先向 TM 註冊(TM 負責記錄 AP 操作過哪些 RM,即分支事務),TM 通過 XA 接口函數通知相應 RM 開啟分布式事務的子事務,接著 AP 就可以對該 RM 管理的資源進行操作。
3.當 AP 對所有 RM 操作完畢後,AP 根據執行情況通知 TM 提交或回滾該全局事務,TM 通過 XA 接口函數通知各 RM 完成操作。TM 會先要求各個 RM 做預提交,所有 RM 返回成功後,再要求各 RM 做正式提交,XA 協議要求,一旦 RM 預提交成功,則後續的正式提交也必須能成功;如果任意一個 RM 預提交失敗,則 TM 通知各 RM 回滾。
4.所有 RM 提交或回滾完成後,全局事務結束。
3.1.1 原子性
XA 協議使用 2PC(Two Phase Commit,兩階段提交)原子提交協議來保證分布式事務原子性。
兩階段提交是指將提交過程分為兩個階段,即準備階段(投票階段)和提交階段(執行階段):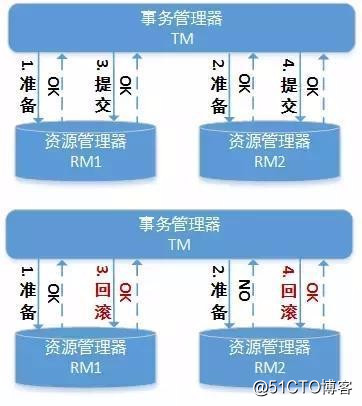
準備階段:
TM 向每個 RM 發送準備消息。如果 RM 的本地事務操作執行成功,則返回成功;如果 RM 的本地事務操作執行失敗,則返回失敗。
提交階段
如果 TM 收到了所有 RM 回復的成功消息,則向每個 RM 發送提交消息;否則發送回滾消息;RM 根據 TM 的指令執行提交或者回滾本地事務操作,釋放所有事務處理過程中使用的鎖資源。
3.1.2 隔離性
XA 協議中沒有描述如何實現分布式事務的隔離性,但是 XA 協議要求DTP 模型中的每個 RM 都要實現本地事務,也就是說,基於 XA 協議實現的分布式事務的隔離性是由每個 RM 本地事務的隔離性來保證的,當一個分布式事務的所有子事務都是隔離的,那麽這個分布式事務天然的就實現了隔離性。
以 MySQL 來舉例,MySQL 使用 2PL(Two-Phase Locking,兩階段鎖)機制來控制本地事務的並發,保證隔離性。2PL 與 2PC 類似,也是將鎖操作分為加鎖和解鎖兩個階段,並且保證兩個階段完全不相交。加鎖階段,只加鎖,不放鎖。解鎖階段,只放鎖,不加鎖。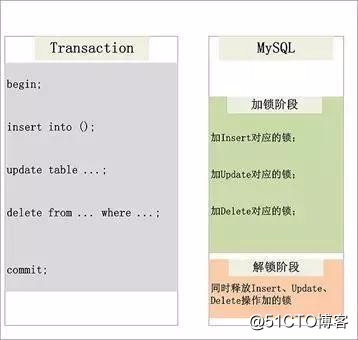
如上圖所示,在一個本地事務中,每執行一條更新操作之前,都會先獲取對應的鎖資源,只有獲取鎖資源成功才會執行該操作,並且一旦獲取了鎖資源就會持有該鎖資源直到本事務執行結束。
MySQL 通過這種 2PL 機制,可以保證在本地事務執行過程中,其他並發事務不能操作相同資源,從而實現了事務隔離。
3.1.3 一致性
前面提到一致性有兩層語義,一層是確保事務執行結束後,數據庫從一個一致狀態轉變為另一個一致狀態。另一層語義是事務執行過程中的中間狀態不能被觀察到。
前一層語義的實現很簡單,通過原子性、隔離性以及 RM 自身一致性的實現就可以保證。至於後一層語義,我們先來看看單個 RM 上的本地事務是怎麽實現的。還是以 MySQL 舉例,MySQL 通過 MVCC(Multi Version Concurrency Control,多版本並發控制)機制,為每個一致性狀態生成快照(Snapshot),每個事務看到的都是各Snapshot對應的一致性狀態,從而也就保證了本地事務的中間狀態不會被觀察到。
雖然單個 RM 上實現了Snapshot,但是在分布式應用架構下,會遇到什麽問題呢?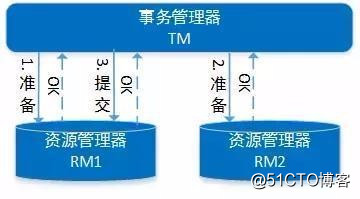
如上圖所示,在 RM1 的本地子事務提交完畢到 RM2 的本地子事務提交完畢之間,只能讀到 RM1 上子事務執行的內容,讀不到 RM2 上的子事務。也就是說,雖然在單個 RM 上的本地事務是一致的,但是從全局來看,一個全局事務執行過程的中間狀態被觀察到了,全局一致性就被破壞了。
XA 協議並沒有定義怎麽實現全局的 Snapshot,像 MySQL 官方文檔裏就建議使用串行化的隔離級別來保證分布式事務一致性: “As with nondistributed transactions, SERIALIZABLE may be preferred if your applications are sensitive to read phenomena. REPEATABLE READ may not be sufficient for distributed transactions.”(對於分布式事務來說,可重復讀隔離級別不足以保證事務一致性,如果你的程序有全局一致性讀要求,可以考慮串行化隔離級別.)
當然,由於串行化隔離級別的性能較差,所以很多分布式數據庫都自己實現了分布式 MVCC 機制來提供全局的一致性讀。一個基本思路是用一個集中式或者邏輯上單調遞增的東西來控制生成全局 Snapshot,每個事務或者每條 SQL 執行時都去獲取一次,從而實現不同隔離級別下的一致性。比如 Google 的 Spanner 就是用 TrueTime 來控制訪問全局 Snapshot。
3.1.4 小結
XA 協議通常實現在數據庫資源層,直接作用於資源管理器上。因此,基於 XA 協議實現的分布式事務產品,無論是分布式數據庫,還是分布式事務框架,對業務幾乎都沒有侵入,就像使用普通數據庫一樣。
XA 協議嚴格保障事務 ACID 特性,能夠滿足所有業務領域的功能需求,但是,這同樣是一把雙刃劍。
由於隔離性的互斥要求,在事務執行過程中,所有的資源都被鎖定,只適用於執行時間確定的短事務。同時,整個事務期間都是獨占數據,對於熱點數據的並發性能可能會很低,實現了分布式 MVCC 或樂觀鎖(optimistic locking)以後,性能可能會有所提升。
同時,為了保障一致性,要求所有 RM 同等可信、可靠,要求故障恢復機制可靠、快速,在網絡故障隔離的情況下,服務基本不可用。
3.2 TCC 模型
TCC(Try-Confirm-Cancel)分布式事務模型相對於 XA 等傳統模型,其特征在於它不依賴資源管理器(RM)對分布式事務的支持,而是通過對業務邏輯的分解來實現分布式事務。
TCC 模型認為對於業務系統中一個特定的業務邏輯,其對外提供服務時,必須接受一些不確定性,即對業務邏輯初步操作的調用僅是一個臨時性操作,調用它的主業務服務保留了後續的取消權。如果主業務服務認為全局事務應該回滾,它會要求取消之前的臨時性操作,這就對應從業務服務的取消操作。而當主業務服務認為全局事務應該提交時,它會放棄之前臨時性操作的取消權,這對應從業務服務的確認操作。每一個初步操作,最終都會被確認或取消。
因此,針對一個具體的業務服務,TCC 分布式事務模型需要業務系統提供三段業務邏輯:
初步操作 Try:完成所有業務檢查,預留必須的業務資源。
確認操作 Confirm:真正執行的業務邏輯,不作任何業務檢查,只使用 Try 階段預留的業務資源。因此,只要 Try 操作成功,Confirm 必須能成功。另外,Confirm 操作需滿足冪等性,保證一筆分布式事務有且只能成功一次。
取消操作 Cancel:釋放 Try 階段預留的業務資源。同樣的,Cancel 操作也需要滿足冪等性。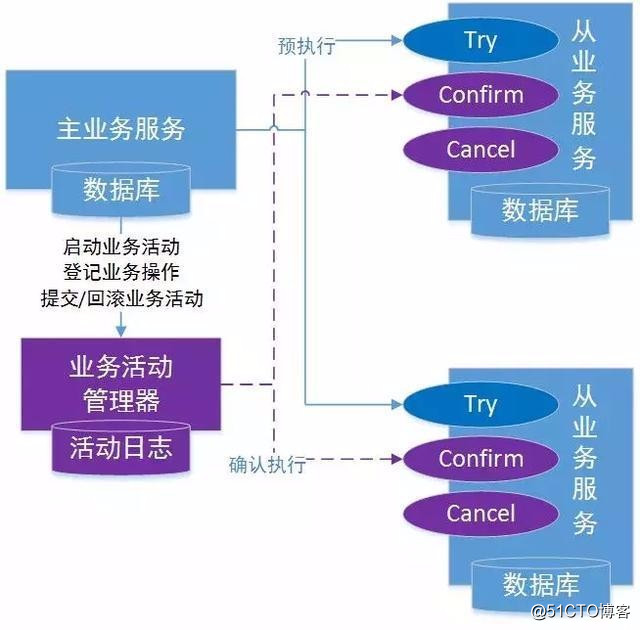
TCC 分布式事務模型包括三部分:
主業務服務:主業務服務為整個業務活動的發起方,服務的編排者,負責發起並完成整個業務活動。
從業務服務:從業務服務是整個業務活動的參與方,負責提供 TCC 業務操作,實現初步操作(Try)、確認操作(Confirm)、取消操作(Cancel)三個接口,供主業務服務調用。
業務活動管理器:業務活動管理器管理控制整個業務活動,包括記錄維護 TCC 全局事務的事務狀態和每個從業務服務的子事務狀態,並在業務活動提交時調用所有從業務服務的 Confirm 操作,在業務活動取消時調用所有從業務服務的 Cancel 操作。
一個完整的 TCC 分布式事務流程如下:
主業務服務首先開啟本地事務;
主業務服務向業務活動管理器申請啟動分布式事務主業務活動;
然後針對要調用的從業務服務,主業務活動先向業務活動管理器註冊從業務活動,然後調用從業務服務的 Try 接口;
當所有從業務服務的 Try 接口調用成功,主業務服務提交本地事務;若調用失敗,主業務服務回滾本地事務;
若主業務服務提交本地事務,則 TCC 模型分別調用所有從業務服務的 Confirm 接口;若主業務服務回滾本地事務,則分別調用 Cancel 接口;
所有從業務服務的 Confirm 或 Cancel 操作完成後,全局事務結束。
3.2.1 原子性
TCC 模型也使用 2PC 原子提交協議來保證事務原子性。Try 操作對應2PC 的一階段準備(Prepare);Confirm 對應 2PC 的二階段提交(Commit),Cancel 對應 2PC 的二階段回滾(Rollback),可以說 TCC 就是應用層的 2PC。
3.2.2 隔離性
TCC 分布式事務模型僅提供兩階段原子提交協議,保證分布式事務原子性。事務的隔離交給業務邏輯來實現。
隔離的本質是控制並發,防止並發事務操作相同資源而引起的結果錯亂。
舉個例子,比如金融行業裏管理用戶資金,當用戶發起交易時,一般會先檢查用戶資金,如果資金充足,則扣除相應交易金額,增加賣家資金,完成交易。如果沒有事務隔離,用戶同時發起兩筆交易,兩筆交易的檢查都認為資金充足,實際上卻只夠支付一筆交易,結果兩筆交易都支付成功,導致資損。
可以發現,並發控制是業務邏輯執行正確的保證,但是像兩階段鎖這樣的並發訪問控制技術要求一直持有數據庫資源鎖直到整個事務執行結束,特別是在分布式事務架構下,要求持有鎖到分布式事務第二階段執行結束,也就是說,分布式事務會加長資源鎖的持有時間,導致並發性能進一步下降。
因此,TCC 模型的隔離性思想就是通過業務的改造,在第一階段結束之後,從底層數據庫資源層面的加鎖過渡為上層業務層面的加鎖,從而釋放底層數據庫鎖資源,放寬分布式事務鎖協議,提高業務並發性能。
還是以上面的例子舉例:
第一階段:檢查用戶資金,如果資金充足,凍結用戶本次交易資金,這筆資金被業務隔離,不允許除本事務之外的其它並發事務動用。
第二階段:扣除第一階段預凍結的用戶資金,增加賣家資金,完成交易。 采用業務加鎖的方式,隔離用戶凍結資金,在第一階段結束後直接釋放底層資源鎖,該用戶和賣家的其他交易都可以立刻並發執行,而不用等到整個分布式事務結束,可以獲得更高的並發交易能力。
3.2.3 一致性
再來看看 TCC 分布式事務模型下的一致性實現。與 XA 協議實現一致性第一層語義類似,通過原子性保證事務的原子提交、業務隔離性控制事務的並發訪問,實現分布式事務的一致性狀態轉變。
至於第二層語義:事務的中間狀態不能被觀察到。我們來看看,在 SOA分布式應用環境下是否是必須的。
還是以賬務服務舉例。轉賬業務(用戶 A ? 用戶 B),由交易服務和賬務服務組成分布式事務,交易服務作為主業務服務,賬務服務作為從業務服務,賬務服務的 Try 操作預凍結用戶 A 的資金;Commit 操作扣除用戶 A 的預凍結資金,增加用戶 B 的可用資金;Cancel 操作解凍用戶 A 的預凍結資金。
當賬務服務執行完 Try 階段後,交易主業務就可以 Commit 了,然後由TCC 框架調用賬務的 Commit 階段。在賬務 Commit 階段還沒執行結束的時候,用戶 A 可以查詢到自己的余額已扣除,但是,此時用戶 B 的可用資金還沒增加。
從系統的角度來看,確實有問題與不確定性。在第一階段執行結束到第二階段執行結束之間,有一段時間的延時,在這段時間內,看似任何用戶都不享有這筆資產。
但是,從用戶的角度來考慮這個問題的話,這個時間間隔可能就無所謂或者根本就不存在。特別是當這個時間間隔僅僅是幾秒鐘,對於具體溝通資產轉移的用戶來講,這個過程是隱蔽的或確實可以接受的,且保證了結果的最終一致性。
當然,對於這樣的系統,如果確實需要查看系統的某個一致性狀態,可以采用額外的方法實現。
一般來講,服務之間的一致性比服務內部的一致性要更加容易弱化,這也是為什麽 XA 等直接在資源層面上實現通用分布式事務的模型會註重一致性的保證,而當上升到服務層面,服務與服務之間已經實現了功能的劃分,邏輯的解耦,也就更容易弱化一致性,這就是 SOA 架構下 BASE 理論的最終一致性思想。
BASE 理論是指 BA(Basic Availability,基本業務可用性);S(Soft state,柔性狀態);E(Eventual consistency,最終一致性)。該理論認為為了可用性、性能與降級服務的需要,可以適當降低一點一致性的要求,即“基本可用,最終一致”。
業內通常把嚴格遵循 ACID 的事務稱為剛性事務;而基於 BASE 思想實現的事務稱為柔性事務。柔性事務並不是完全放棄了 ACID,僅僅是放寬了一致性要求:事務完成後的一致性嚴格遵循,事務中的一致性可適當放寬;
3.2.4 小結
TCC 分布式事務模型的業務實現特性決定了其可以跨 DB、跨服務實現資源管理,將對不同的 DB 訪問、不同的業務操作通過 TCC 模型協調為一個原子操作,解決了分布式應用架構場景下的事務問題。
TCC 模型通過 2PC 原子提交協議保證分布式事務的的原子性,把資源層的隔離性上升到業務層,交給業務邏輯來實現。TCC 的每個操作對於資源層來說,就是單個本地事務的使用,操作結束則本地事務結束,規避了資源層在 2PC 和 2PL 下對資源占用導致的性能低下問題。
同時,TCC 模型也可以根據業務需要,做一些定制化的功能,比如交易異步化實現削峰填谷等。
但是,業務接入 TCC 模型需要拆分業務邏輯成兩個階段,並實現 Try、Confirm、Cancel 三個接口,定制化程度高,開發成本高。
四. 總結
本文首先介紹了典型的分布式事務的架構場景。分布式事務剛開始是為解決單服務多數據庫資源的場景而誕生的。隨著技術的發展,特別是 SOA 分布式應用架構以及微服務時代的到來,服務變成了基本業務單元。因此,又產生了跨服務的分布式事務需求。然後從 XA 和 TCC 兩種常用的分布式事務模型入手,介紹了其實現機制,著重分析了各模型是如何實現分布式事務 ACID 特性的。
螞蟻技術專家:一篇文章帶你學習分布式事務