
CNN基礎框架簡介
- 卷積神經網絡簡介
卷積神經網絡是多層感知機的變種,由生物學家休博爾和維瑟爾在早期關於貓視覺皮層的研究發展而來。視覺皮層的細胞存在一個復雜的構造,這些細胞對視覺輸入空間的子區域非常敏感,我們稱之為感受野。
通常神經認知機包含特征提取的采樣元和抗變形的卷積元,采樣元中涉及兩個重要參數,即感受野與閾值參數,前者確定輸入連接的數目,後者控制對特征子模式的反應程度。卷積神經網絡可以看作神經認知機的推廣。
- 卷積神經網絡的特點
卷積神經網絡成功的關鍵在於它采用了局部連接(傳統神經網絡中每個神經元與圖片上每個像素相連接)和權值共享(卷積過程中卷積核的權重不變)的方式,一方面減少了權值的數量使得網絡易於優化,另一方面降低了過擬合的風險。
CNN的特征提取層參數是通過訓練數據學習得到的,所以其避免了人工特征提取,而是從訓練數據中進行學習;同一特征圖的神經元共享權值,減少了網絡參數,這也是卷積神經網絡相對於全連接網絡的一大優勢。
CNN一般采用卷積層與采樣層交替設置,即一層卷積層接一層采樣層,采樣層後接一層卷積層……,這樣卷積層提取出特征,再進行組合形成更抽象的特征,最後形成對圖片對象的特征描述。
下采樣層(Down-Pooling)也稱池化層,一般包含平均池化和最大池化。最大池化(Pooling)采樣,它是一種非線性降采樣方法,其在計算機視覺中的價值主要體現在兩個方面:(1)它減小了來自上層隱藏層的計算復雜度;(2)這些池化單元具有平移不變性;由於增強了對位移的魯棒性,因此是一個高效的降低數據維度的采樣方法。
- CNN的演變史

CNN的演化路徑可以總結為以下幾個方向:
1.從LeNet到Alex-Net
2.網絡結構加深
3.加強卷積功能
4.從分類到檢測
5.新增功能模塊
- LeNet

作為CNN的開端,LeNet包含了卷積層,池化層,全連接層,這些都是現代CNN網絡的基本組件。
輸入尺寸:32*32
卷積層:3個
降采樣層:2個
全連接層:1個
輸出:10個類別(數字0~9的概率)
Inuput(32*32)
輸入圖像Size為32*32,比mnist數據庫中最大的字幕(28*28)還大,這樣做的目的是希望潛在的明顯特征能夠出現在最高層特征監測子感受野的中心
C1,C3,C5(卷積層)
卷積運算可以理解為濾波操作(參考Stanford CS131),通過卷積運算,可以使原信號特征增強,並且降低噪聲。
S2,S4(池化層)
池化層,也稱下采樣層,是為了降低網絡訓練參數及模型的過擬合程度,通常有Max-Pooling和Mean-Pooling兩種方式。
- AlexNet(https://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf)
深度學習的鼻祖Hinton(http://study.163.com/course/introduction.htm?courseId=1003842018)和他的學生Alex Krizhevsky 在2012年ImageNet Challenge使用的模型,刷新了Image Classification的記錄,從此深度學習進入了一個新時代;
AlexNet的網絡結構如下圖所示,總共包含8層,其中前5層為卷積層,後3層為全連接層,輸入為1000個分類,一個完整的卷積層通常包含一層convolution,一層Rectified Linear Units,一層max-pooling,一層normalization,AlexNet完整的網絡模型如圖1所示,為了加快訓練,使用了2個GPU;

圖1 AlexNet網絡模型
Conv1對應的數據流圖如下,AlexNet首先256*256*3的RGB圖像進行數據增強,對於輸入的圖像隨機提取224*224*3,並對數據進行horizontal reflections變換,使得數據集增大了2048倍,隨後經過預處理變為227*227*3的訓練數據;
使用96個11*11的卷積核進行卷積運算(每個GPU 48個卷積核),步長為4,對應的輸出尺寸為(227+2*0-11)/4+1=55,隨後使用3*3的池化層進行下采樣,步長為2,對應的輸出尺寸為(55+2*0-3)/2+1=27;
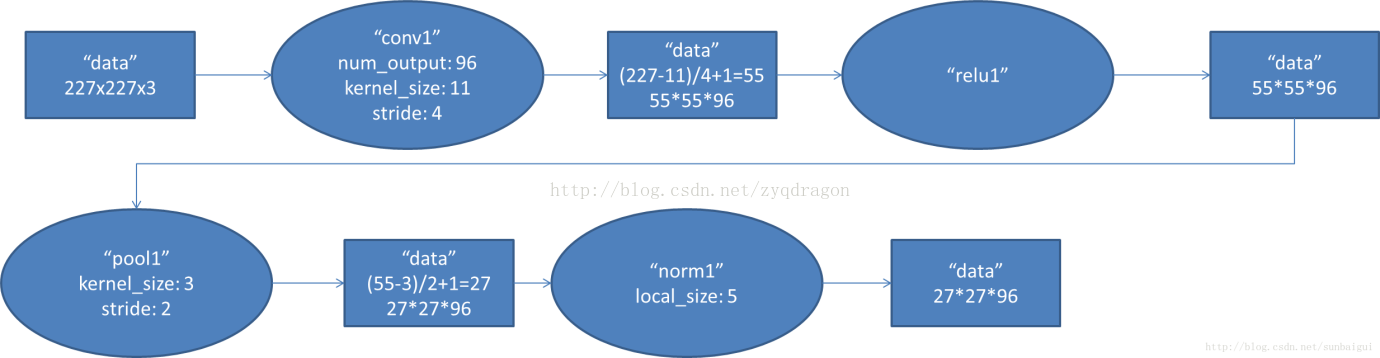
圖2 Conv1數據流圖
Conv2對應的數據流圖如下

圖3 Conv2數據流圖
Conv3對應的數據流圖如下

圖4 Conv3數據流圖
Conv4對應的數據流圖如下

圖5 Conv4數據流圖
Conv5對應的數據流圖如下

圖6 Conv5數據流圖
Fc6對應的數據流圖如下

圖7 Fc6數據流圖
Fc7對應的數據流圖如下

圖8 Fc7數據流圖
Fc8對應的數據流圖

圖9 Fc8數據流圖
- VGGNet(https://arxiv.org/pdf/1409.1556.pdf)
- GoogLeNet Inception V1(https://www.cv-foundation.org/openaccess/content_cvpr_2015/papers/Szegedy_Going_Deeper_With_2015_CVPR_paper.pdf)
一般來說,提升網絡性能最直接的辦法就是增加網絡深度和寬度,也意味著巨量的參數,但是巨量參數容易產生過擬合同時也大大增加了計算量。2014年《Going deeper with convolutions》一文中提出解決這兩個問題的根本方法是將全連接甚至一般的卷積都轉化為稀疏連接。另一方面有文獻指出,對於大規模稀疏的神經網路,可以通過分析激活值的統計特性和對高度相關的輸出進行聚類來逐層構建出一個最優網絡。這點表明臃腫的稀疏網絡可能被不失性能地簡化。
所以優化的目標就變成了:既能保持網絡結構的稀疏性,又能利用密集矩陣的高計算性能。據此論文提出了Inception的結構來實現此目的。

對於上圖作如下說明:
1.采用不同大小的卷積核意味著不同大小的感受野,最後拼接意味著不同尺度特征的融合;
2.選擇卷積核大小為1、3、5,同時設定步長stride=1,並設定padding=0、1、2,那麽卷積之後便可以得到相同的尺寸,方便拼接在一起。
3.pooling在減少計算參數量並降低過擬合的風險,因此在Inception中也引用了pooling;
4.網絡越到後面,特征越抽象,並且每個特征所涉及的感受野也更大了,同時隨著層數的增加,3*3和5*5卷積的比例也相應的增加;
5.使用5*5的卷積核仍然會帶來巨大的計算量,為此,文章借鑒NIN,采用1*1的卷積核進行降維;
改進後的GoogLeNet框架如下圖所示:

GoogLeNet整體連接圖如下圖所示

對上圖作如下說明:
1.網絡最後采用了average pooling 替代全連接層,事實證明可以將Top1 accuracy提高0.6%。但是,實際在最後還是加了一個全連接層,主要是為了方便後續finetune;
2.雖然移除了全連接,但是網絡中依然使用了Dropout;
3.為了避免梯度彌散,網絡額外增加了2個輔助的softmax用於向前傳導梯度。
- GoogLeNet Inception V2
經過實驗得到的準則:
1.避免表達瓶頸,特別是在網絡靠前的地方。信息流向前傳播過程中不能經過高度壓縮的層。
2.高維特征更容易處理。高維特征更易區分,會加快訓練。
3.可以在低緯嵌入上進行空間匯聚而無需擔心丟失很多信息。
4.平衡網絡的寬度與深度
大尺寸的卷積核可以帶來更大的感受野,但也意味著更多的參數,比如5*5卷積核是3*3卷積核的2.78倍。為此,作者提出可以用兩個連續的3*3卷積層(stride=1)組成的小網絡來代替單個的5*5卷積層。
參考文獻
https://blog.csdn.net/shuzfan/article/details/50738394
http://blog.csdn.net/cyh_24/article/details/51440344
https://blog.csdn.net/sunbaigui/article/details/39938097
http://www.cnblogs.com/gongxijun/p/6027747.html
http://blog.sina.com.cn/s/blog_6a8198dc0102v9yu.html
CNN基礎框架簡介