
MongoShake——基於MongoDB的跨數據中心的數據復制平臺
背景
在當前的數據庫系統生態中,大部分系統都支持多個節點實例間的數據同步機制,如Mysql Master/Slave主從同步,Redis AOF主從同步等,MongoDB更是支持3節點及以上的副本集同步,上述機制很好的支撐了一個邏輯單元的數據冗余高可用。
跨邏輯單元,甚至跨單元、跨數據中心的數據同步,在業務層有時候就顯得很重要,它使得同城多機房的負載均衡,多機房的互備,甚至是異地多數據中心容災和多活成為可能。由於目前MongoDB副本集內置的主從同步對於這種業務場景有較大的局限性,為此,我們開發了MongoShake系統,可以應用在實例間復制,機房間、跨數據中心復制,滿足災備和多活需求。
另外,數據備份是作為MongoShake核心但不是唯一的功能。MongoShake作為一個平臺型服務,用戶可以通過對接MongoShake,實現數據的訂閱消費來滿足不同的業務場景。
簡介
MongoShake是一個以golang語言進行編寫的通用的平臺型服務,通過讀取MongoDB集群的Oplog操作日誌,對MongoDB的數據進行復制,後續通過操作日誌實現特定需求。日誌可以提供很多場景化的應用,為此,我們在設計時就考慮了把MongoShake做成通用的平臺型服務。通過操作日誌,我們提供日誌數據訂閱消費PUB/SUB功能,可通過SDK、Kafka、MetaQ等方式靈活對接以適應不同場景(如日誌訂閱、數據中心同步、Cache異步淘汰等)。集群數據同步是其中核心應用場景,通過抓取oplog後進行回放達到同步目的,實現災備和多活的業務場景。
應用場景舉例
1. MongoDB集群間數據的異步復制,免去業務雙寫開銷。
2. MongoDB集群間數據的鏡像備份(當前1.0開源版本支持受限)
3. 日誌離線分析
4. 日誌訂閱
5. 數據路由。根據業務需求,結合日誌訂閱和過濾機制,可以獲取關註的數據,達到數據路由的功能。
6. Cache同步。日誌分析的結果,知道哪些Cache可以被淘汰,哪些Cache可以進行預加載,反向推動Cache的更新。
7. 基於日誌的集群監控
功能介紹
MongoShake從源庫抓取oplog數據,然後發送到各個不同的tunnel通道。現有通道類型有:
1. Direct:直接寫入目的MongoDB
2. RPC:通過net/rpc方式連接
3. TCP:通過tcp方式連接
4. File:通過文件方式對接
5. Kafka:通過Kafka方式對接
6. Mock:用於測試,不寫入tunnel,拋棄所有數據
消費者可以通過對接tunnel通道獲取關註的數據,例如對接Direct通道直接寫入目的MongoDB,或者對接RPC進行同步數據傳輸等。此外,用戶還可以自己創建自己的API進行靈活接入。下面2張圖給出了基本的架構和數據流。
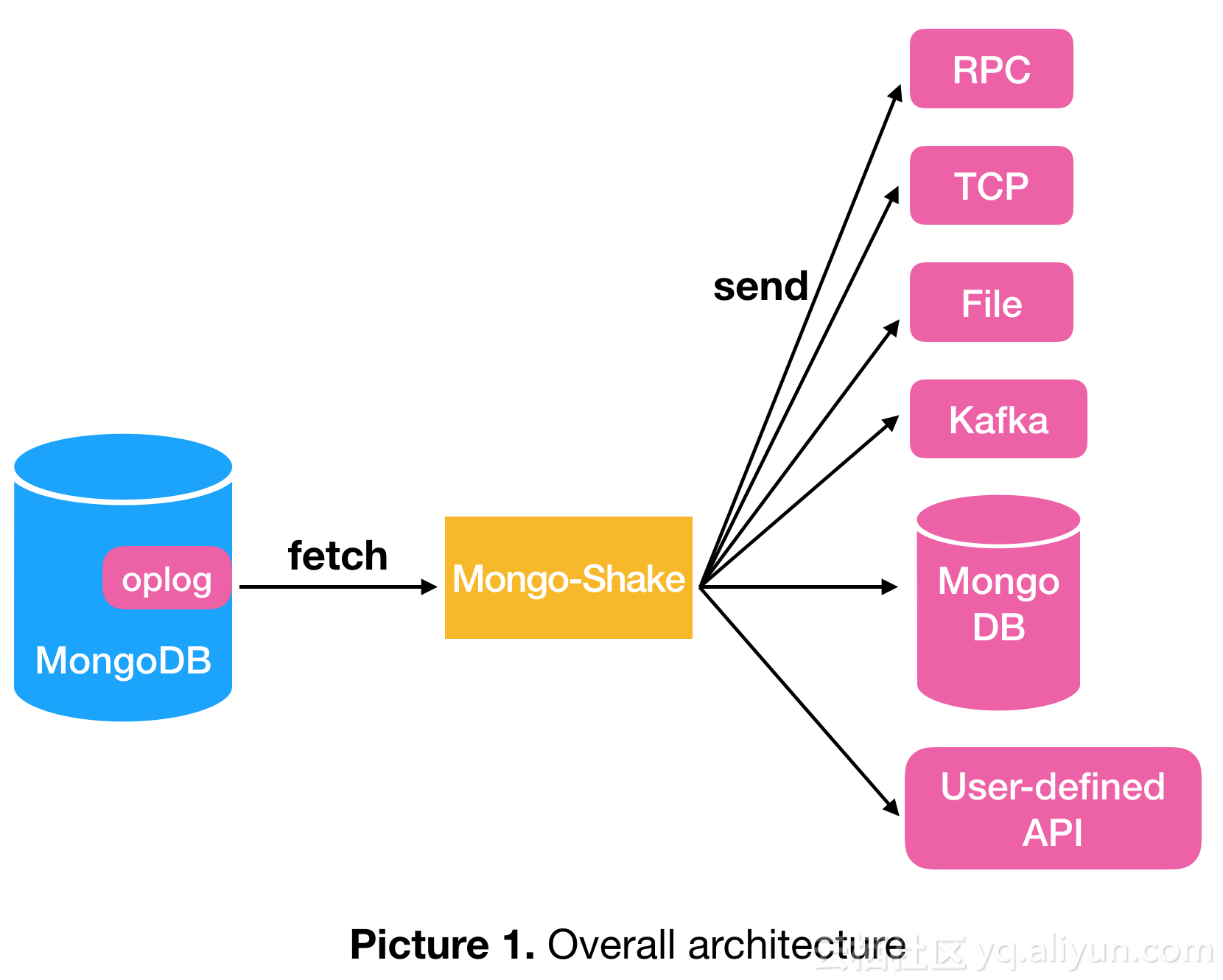
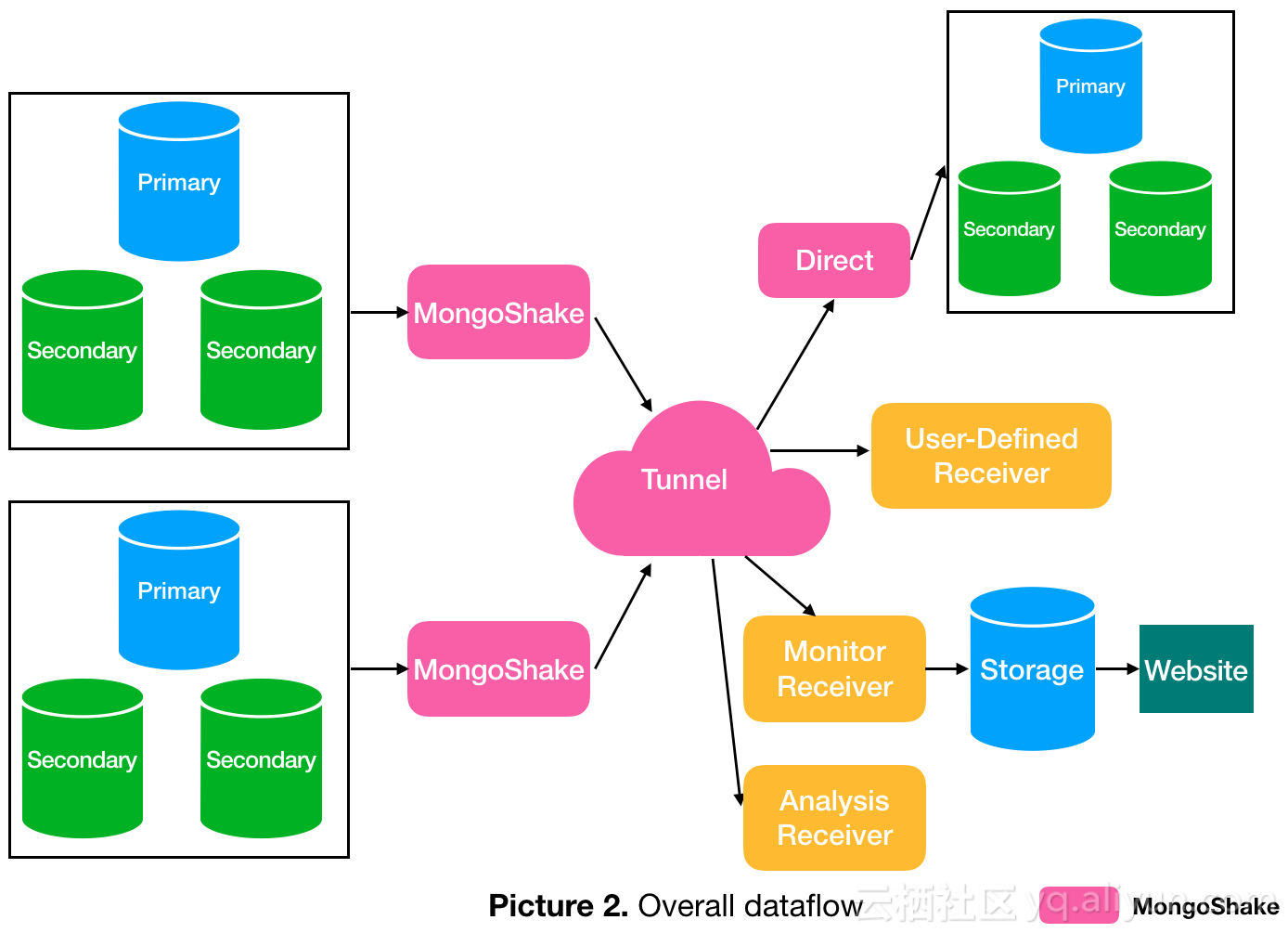
MongoShake對接的源數據庫支持單個mongod,replica set和sharding三種模式。目的數據庫支持mongod和mongos。如果源端數據庫為replica set,我們建議對接備庫以減少主庫的壓力;如果為sharding模式,那麽每個shard都將對接到MongoShake並進行並行抓取。對於目的庫來說,可以對接多個mongos,不同的數據將會哈希後寫入不同的mongos。
並行復制
MongoShake提供了並行復制的能力,復制的粒度選項(shard_key)可以為:id,collection或者auto,不同的文檔或表可能進入不同的哈希隊列並發執行。id表示按文檔進行哈希;collection表示按表哈希;auto表示自動配置,如果有表存在唯一鍵,則退化為collection,否則則等價於id。
HA方案
MongoShake定期將同步上下文進行存儲,存儲對象可以為第三方API(註冊中心)或者源庫。目前的上下文內容為“已經成功同步的oplog時間戳”。在這種情況下,當服務切換或者重啟後,通過對接該API或者數據庫,新服務能夠繼續提供服務。
此外,MongoShake還提供了Hypervisor機制用於在服務掛掉的時候,將服務重新拉起。
過濾
提供黑名單和白名單機制選擇性同步db和collection。
壓縮
支持oplog在發送前進行壓縮,目前支持的壓縮格式有gzip, zlib, 或deflate。
Gid
一個數據庫的數據可能會包含不同來源:自己產生的和從別處復制的數據。如果沒有相應的措施,可能會導致數據的環形復制,比如A的數據復制到B,又被從B復制到A,導致服務產生風暴被打掛了。或者從B回寫入A時因為唯一鍵約束寫入失敗。從而導致服務的不穩定。
在阿裏雲上的MongoDB版本中,我們提供了防止環形復制的功能。其主要原理是,通過修改MongoDB內核,在oplog中打入gid標識當前數據庫信息,並在復制過程中通過op_command命令攜帶gid信息,那麽每條數據都有來源信息。如果只需要當前數據庫產生的數據,那麽只抓取gid等於該數據庫id的oplog即可。所以,在環形復制的場景下,MongoShake從A數據庫抓取gid等於id_A(A的gid)的數據,從B數據庫抓取gid等於id_B(B的gid)的數據即可解決這個問題。
說明:由於MongoDB內核gid部分的修改尚未開源,所以開源版本下此功能受限,但在阿裏雲MongoDB版本已支持。這也是為什麽我們前面提到的“MongoDB集群間數據的鏡像備份”在目前開源版本下功能受限的原因。
Checkpoint
MongShake采用了ACK機制確保oplog成功回放,如果失敗將會引發重傳,傳輸重傳的過程類似於TCP的滑動窗口機制。這主要是為了保證應用層可靠性而設計的,比如解壓縮失敗等等。為了更好的進行說明,我們先來定義幾個名詞:
LSN(Log Sequence Number),表示已經傳輸的最新的oplog序號。
LSN_ACK(Acked Log Sequence Number),表示已經收到ack確認的最大LSN,即寫入tunnel成功的LSN。
LSN_CKPT(Checkpoint Log Sequence Number),表示已經做了checkpoint的LSN,即已經持久化的LSN。
LSN、LSN_ACK和LSN_CKPT的值均來自於Oplog的時間戳ts字段,其中隱含約束是:LSN_CKPT<=LSN_ACK<=LSN。
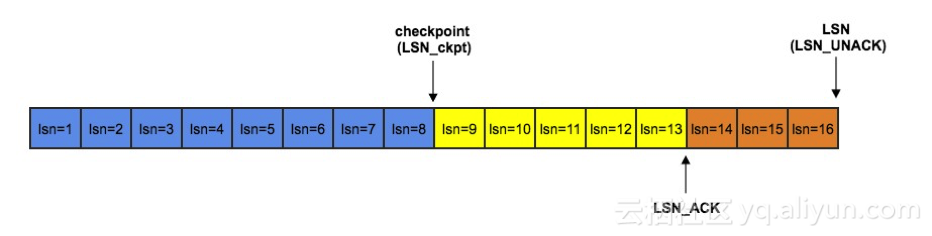
如上圖所示,LSN=16表示已經傳輸了16條oplog,如果沒有重傳的話,下次將傳輸LSN=17;LSN_ACK=13表示前13條都已經收到確認,如果需要重傳,最早將從LSN=14開始;LSN_CKPT=8表示已經持久化checkpoint=8。持久化的意義在於,如果此時MongoShake掛掉重啟後,源數據庫的oplog將從LSN_CKPT位置開始讀取而不是從頭LSN=1開始讀。因為oplog DML的冪等性,同一數據多次傳輸不會產生問題。但對於DDL,重傳可能會導致錯誤。
排障和限速
MongoShake對外提供Restful API,提供實時查看進程內部各隊列數據的同步情況,便於問題排查。另外,還提供限速功能,方便用戶進行實時控制,減輕數據庫壓力。
沖突檢測
目前MongoShake支持表級別(collection)和文檔級別(id)的並發,id級別的並發需要db沒有唯一索引約束,而表級別並發在表數量小或者有些表分布非常不均勻的情況下性能不佳。所以在表級別並發情況下,需要既能均勻分布的並發,又能解決表內唯一鍵沖突的情況。為此,如果tunnel類型是direct時候,我們提供了寫入前的沖突檢測功能。
目前索引類型僅支持唯一索引,不支持前綴索引、稀疏索引、TTL索引等其他索引。
沖突檢測功能的前提需要滿足兩個前提約束條件:
1. MongoShake認為同步的MongoDB Schema是一致的,也不會監聽Oplog的System.indexes表的改動
2. 沖突索引以Oplog中記錄的為準,不以當前MongoDB中索引作為參考。
另外,MongoShake在同步過程中對索引的操作可能會引發異常情況:
1. 正在創建索引。如果是後臺建索引,這段時間的寫請求是看不到該索引的,但內部對該索引可見,同時可能會導致內存使用率會過高。如果是前臺建索引,所有用戶請求是阻塞的,如果阻塞時間過久,將會引發重傳。
2. 如果目的庫存在的唯一索引在源庫沒有,造成數據不一致,不進行處理。
3. oplog產生後,源庫才增加或刪除了唯一索引,重傳可能導致索引的增刪存在問題,我們也不進行處理。
為了支持沖突檢測功能,我們修改了MongoDB內核,使得oplog中帶入uk字段,標識涉及到的唯一索引信息,如:
{ "ts" : Timestamp(1484805725, 2), "t" : NumberLong(3), "h" : NumberLong("-6270930433887838315"), "v" : 2, "op" : "u", "ns" : "benchmark.sbtest10", "o" : { "_id" : 1, "uid" : 1111, "other.sid":"22222", "mid":8907298448, "bid":123 } "o2" : {"_id" : 1} "uk" : { "uid": "1110"
"mid^bid": [8907298448, 123] "other.sid_1": "22221"
}
}uk下面的key表示唯一鍵的列名,key用“^”連接的表示聯合索引,上面記錄中存在3個唯一索引:uid、mid和bid的聯合索引、other.sid_1。value在增刪改下具有不同意義:如果是增加操作,則value為空;如果是刪除或者修改操作,則記錄刪除或修改前的值。
具體處理流程如下:將連續的k個oplog打包成一個batch,流水式分析每個batch之內的依賴,劃分成段。如果存在沖突,則根據依賴和時序關系,將batch切分成多個段;如果不存在沖突,則劃分成一個段。然後對段內進行並發寫入,段與段之間順序寫入。段內並發的意思是多個並發線程同時對段內數據執行寫操作,但同一個段內的同一個id必須保證有序;段之間保證順序執行:只有前面一個段全部執行完畢,才會執行後續段的寫入。
如果一個batch中,存在不同的id的oplog同時操作同一個唯一鍵,則認為這些oplog存在時序關系,也叫依賴關系。我們必須將存在依賴關系的oplog拆分到2個段中。
MongoShake中處理存在依賴關系的方式有2種:
(1) 插入barrier
通過插入barrier將batch進行拆分,每個段內進行並發。舉個例子,如下圖所示:
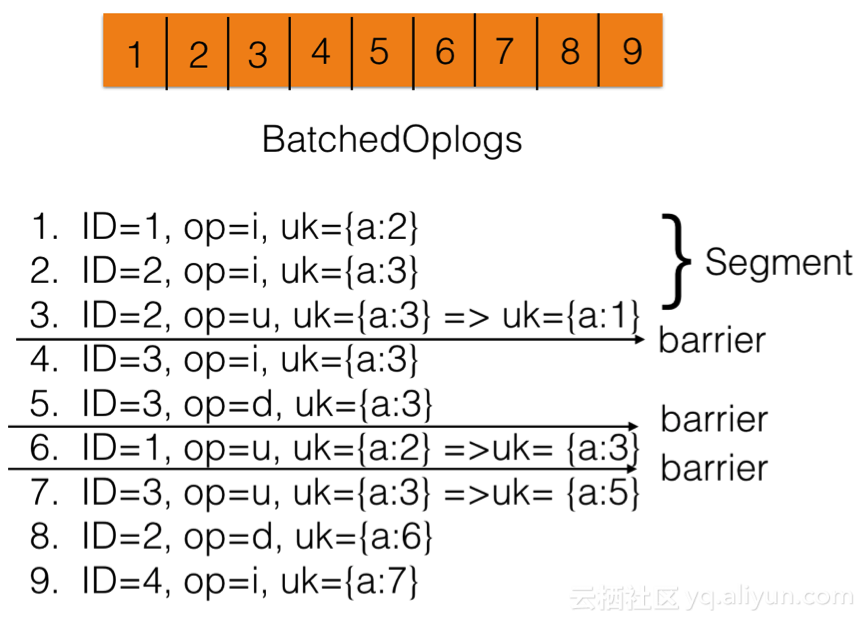
ID表示文檔id,op表示操作,i為插入,u為更新,d為刪除,uk表示該文檔下的所有唯一鍵, uk={a:3} => uk={a:1}表示將唯一鍵的值從a=3改為a=1,a為唯一鍵。
在開始的時候,batch中有9條oplog,通過分析uk關系對其進行拆分,比如第3條和第4條,在id不一致的情況下操作了同一個uk={a:3},那麽第3條和第4條之間需要插入barrier(修改前或者修改後無論哪個相同都算沖突),同理第5條和第6條,第6條和第7條。同一個id操作同一個uk是允許的在一個段內是允許的,所以第2條和第3條可以分到同一個段中。拆分後,段內根據id進行並發,同一個id仍然保持有序:比如第一個段中的第1條和第2,3條可以進行並發,但是第2條和第3條需要順序執行。
(2) 根據關系依賴圖進行拆分
每條oplog對應一個時間序號N,那麽每個序號N都可能存在一個M使得:
如果M和N操作了同一個唯一索引的相同值,且M序號小於N,則構建M到N的一條有向邊。
如果M和N的文檔ID相同且M序號小於N,則同樣構建M到N的一條有向邊。
由於依賴按時間有序,所以一定不存在環。
所以這個圖就變成了一個有向無環圖,每次根據拓撲排序算法並發寫入入度為0(沒有入邊)的點即可,對於入度非0的點等待入度變為0後再寫入,即等待前序結點執行完畢後再執行寫入。
下圖給出了一個例子:一共有10個oplog結點,一個橫線表示文檔ID相同,右圖箭頭方向表示存在唯一鍵沖突的依賴關系。那麽,該圖一共分為4次執行:並發處理寫入1,2,4,5,然後是3,6,8,其次是7,10,最後是9。
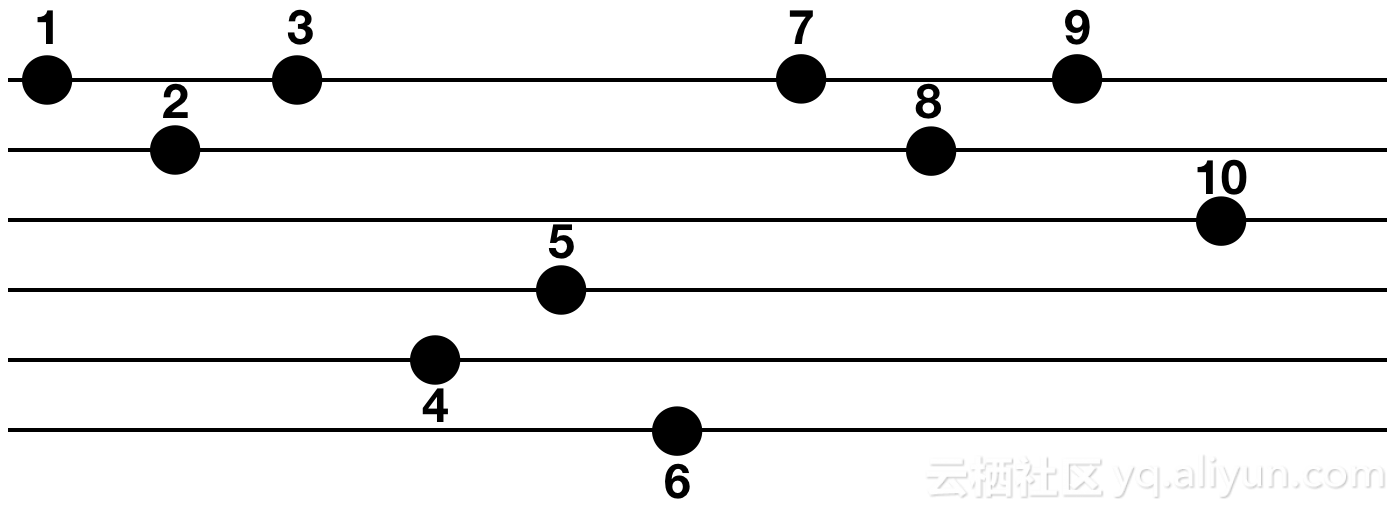
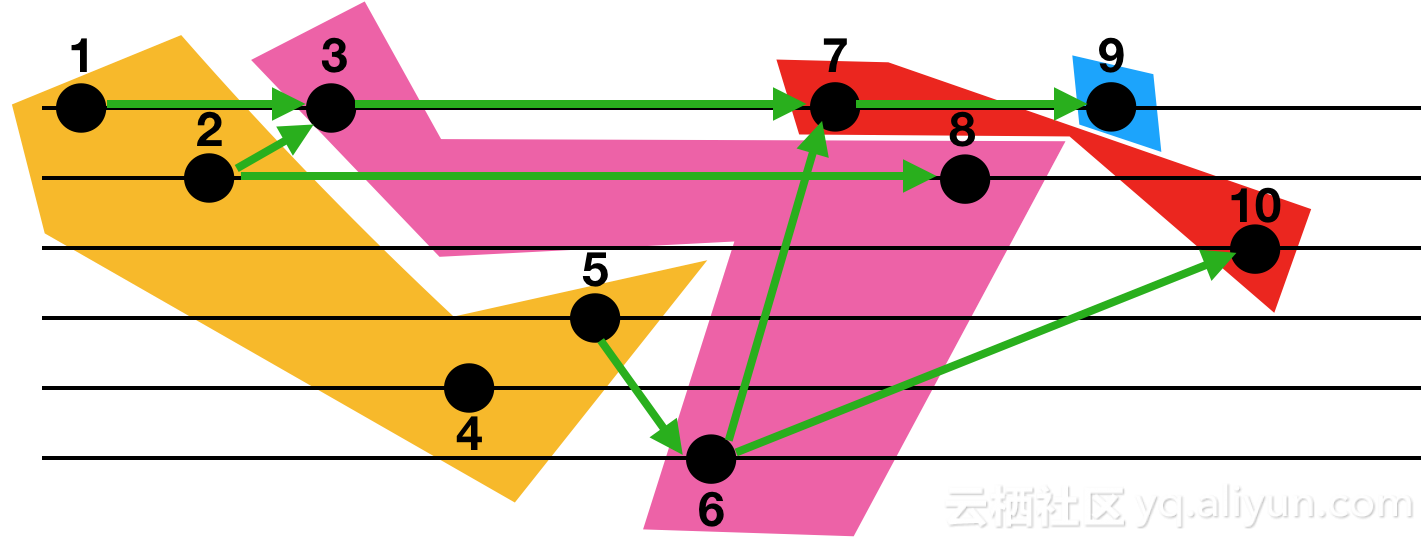
說明:由於MongoDB中沖突檢測uk部分的修改尚未開源,所以開源版本下此功能受限,但在阿裏雲MongoDB版本已支持。
架構和數據流
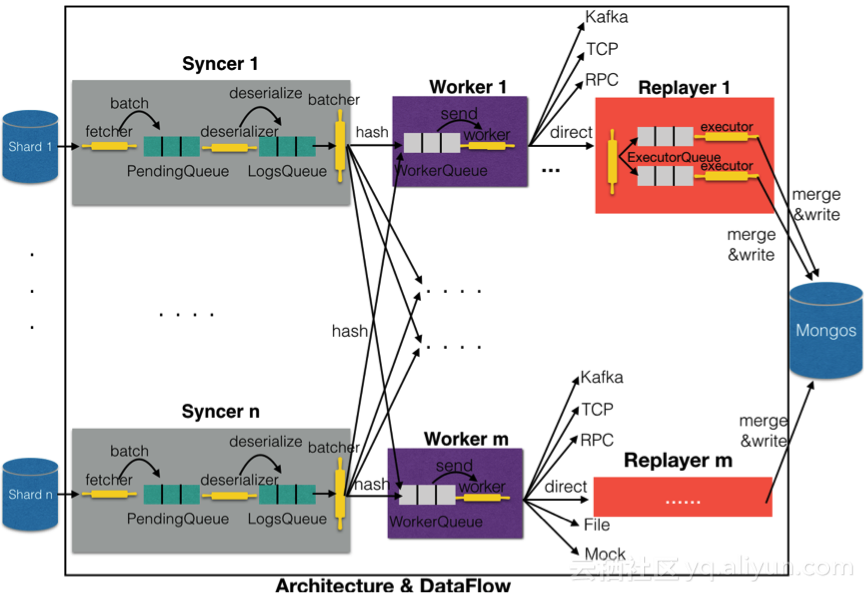
上圖展示了MongoShake內部架構和數據流細節。總體來說,整個MongoShake可以大體分為3大部分:Syncer、Worker和Replayer,其中Replayer只用於tunnel類型為direct的情況。
Syncer負責從源數據庫拉取數據,如果源是Mongod或者ReplicaSet,那麽Syncer只有1個,如果是Sharding模式,那麽需要有多個Syncer與Shard一一對應。在Syncer內部,首先fetcher用mgo.v2庫從源庫中抓取數據然後batch打包後放入PendingQueue隊列,deserializer線程從PendingQueue中抓取數據進行解序列化處理。Batcher將從LogsQueue中抓取的數據進行重新組織,將前往同一個Worker的數據聚集在一起,然後hash發送到對應Worker隊列。
Worker主要功能就是從WorkerQueue中抓取數據,然後進行發送,由於采用ack機制,所以會內部維持幾個隊列,分別為未發送隊列和已發送隊列,前者存儲未發送的數據,後者存儲發送但是沒有收到ack確認的數據。發送後,未發送隊列的數據會轉移到已發送隊列;收到了對端的ack回復,已發送隊列中seq小於ack的數據將會被刪除,從而保證了可靠性。
Worker可以對接不同的Tunnel通道,滿足用戶不同的需求。如果通道類型是direct,那麽將會對接Replayer進行直接寫入目的MongoDB操作,Worker與Replayer一一對應。首先,Replayer將收到的數據根據沖突檢測規則分發到不同的ExecutorQueue,然後executor從隊列中抓取進行並發寫入。為了保證寫入的高效性,MongoShake在寫入前還會對相鄰的相同Operation和相同Namespace的Oplog進行合並。
用戶使用案例
高德地圖 App是國內首屈一指的地圖及導航應用,阿裏雲MongoDB數據庫服務為該應用提供了部分功能的存儲支撐,存儲億級別數據。現在高德地圖使用國內雙中心的策略,通過地理位置等信息路由最近中心提升服務質量,業務方(高德地圖)通過用戶路由到三個城市數據中心,如下圖所示,機房數據之間無依賴計算。
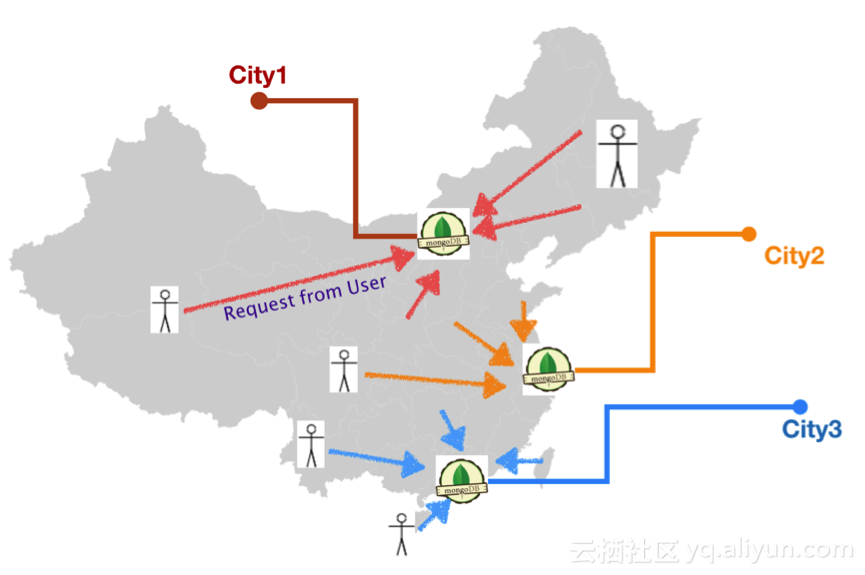
這三個城市地理上從北到南橫跨了整個中國 ,這對多數據中心如何做好復制、容災提出了挑戰,如果某個地域的機房、網絡出現問題,可以平滑的將流量切換到另一個地方,做到用戶幾乎無感知?
目前我們的策略是,拓撲采用機房兩兩互聯方式,每個機房的數據都將同步到另外兩個機房。然後通過高德的路由層,將用戶請求路由到不同的數據中心,讀寫均發送在同一個數據中心,保證一定的事務性。然後再通過MongoShake,雙向異步復制兩個數據中心的數據,這樣保證每個數據中心都有全量的數據(保證最終一致性) 。任意機房出現問題,另兩個機房中的一個可以通過切換後提供讀寫服務。下圖展示了城市1和城市2機房的同步情況。
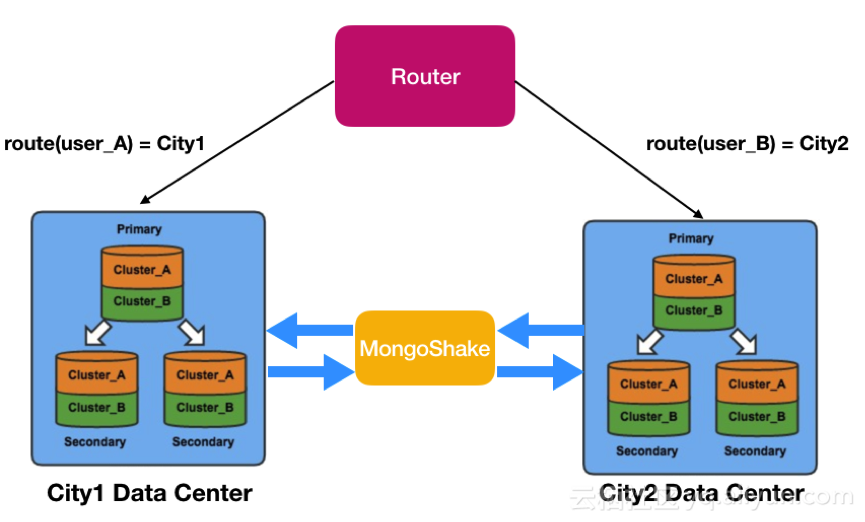
遇到某個單元不能訪問的問題,通過MongoShake對外開放的Restful管理接口,可以獲得各個機房的同步偏移量和時間戳,通過判斷采集和寫入值即可判斷異步復制是否在某個時間點已經完成。再配合業務方的DNS切流,切走單元流量並保證原有單元的請求在新單元是可以讀寫的,如下圖所示。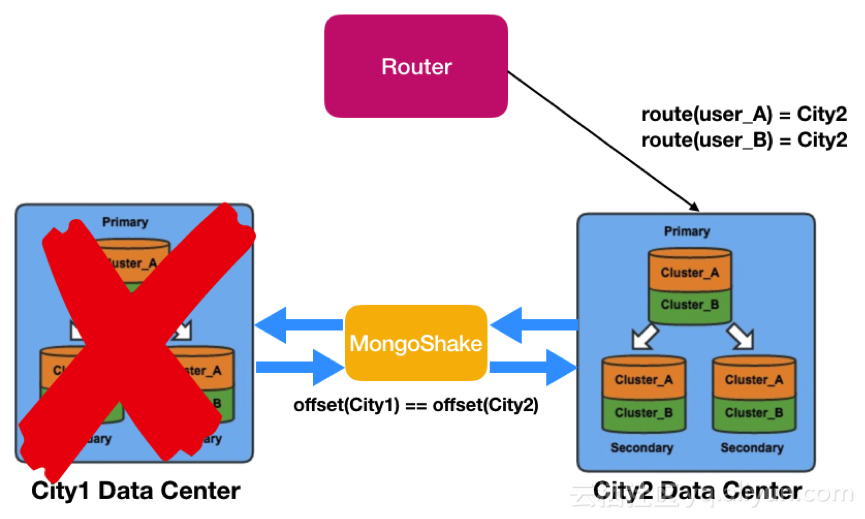
性能測試數據
具體測試數據請參考性能測試文檔。
後續
MongoShake將會長期維護,大版本和小版本將會進行持續叠代。歡迎提問留言以及加入一起進行開源開發。
原文鏈接
MongoShake——基於MongoDB的跨數據中心的數據復制平臺