
遷移學習(Transfer Learning)
深度學習中在計算機視覺任務和自然語言處理任務中將預訓練的模型作為新模型的起點是一種常用的方法,通常這些預訓練的模型在開發神經網絡的時候已經消耗了巨大的時間資源和計算資源,遷移學習可以將已習得的強大技能遷移到相關的的問題上。
什麽是遷移學習?
遷移學習(Transfer Learning)是一種機器學習方法,是把一個領域(源領域)的知識,遷移到另外一個領域(目標領域),使得目標領域能夠取得更好的學習效果。
通常,源領域數據量充足,而目標領域數據量較小,這種場景就很適合做遷移學習,例如我們我們要對一個任務進行分類,但是此任務中數據不充足(目標域),然而卻又大量的相關的訓練數據(源域),但是此訓練數據與所需進行的分類任務中的測試數據特征分布不同(例如語音情感識別中,一種語言的語音數據充足,然而所需進行分類任務的情感數據卻極度缺乏),在這種情況下如果可以采用合適的遷移學習方法則可以大大提高樣本不充足任務的分類識別結果。
為什麽需要進行遷移學習?
1. 目標域數據量較小或者數據的標簽很難獲取,可以通過數據量充足或者容易獲取標簽且和該任務相似的任務(源域)來遷移學習。
2. 從頭建立模型復雜且耗時,通過遷移學習可以加快學習效率。
如何使用遷移學習?
可以在自己預測模型問題上使用遷移學習,常用的2個方法:
1. 開發模型的方法 - 自主訓練源模型並將模型遷移應用到其他類似目標任務
(1)選擇源任務。你必須選擇一個具有豐富數據的相關的預測建模問題,原任務和目標任務的輸入數據、輸出數據以及從輸入數據和輸出數據之間的映射中學到的概念之間有某種關系。
(2)開發源模型。然後,你必須為第一個任務開發一個精巧的模型。這個模型一定要比普通的模型更好,以保證一些特征學習可以被執行。
(3)重用模型。然後,適用於源任務的模型可以被作為目標任務的學習起點。這可能將會涉及到全部或者部分使用第一個模型,這依賴於所用的建模技術。
(4)調整模型。模型可以在目標數據集中的輸入-輸出對上選擇性地進行微調,以讓它適應目標任務。
2. 預訓練模型方法 - 基於別人(權威研究機構)發布的模型遷移到自己的目標任務 (常用)
(1)選擇源模型。一個預訓練的源模型是從可用模型中挑選出來的。很多研究機構都發布了基於超大數據集的模型,這些都可以作為源模型的備選者。
(2)重用模型。選擇的預訓練模型可以作為用於第二個任務的模型的學習起點。這可能涉及到全部或者部分使用與訓練模型,取決於所用的模型訓練技術。
(3)調整模型。模型可以在目標數據集中的輸入-輸出對上選擇性地進行微調,以讓它適應目標任務。
其中,第2種類型的遷移學習在深度學習領域比較常用。比如 基於ImageNet的圖片分類任務,根據google已經訓練好的Inception_v3模型,完全可以遷移到自己的圖片分類任務中,比如自定義識別綠蘿和吊蘭,只需添加少量的有關綠蘿和吊蘭的圖片(不能太少!最好各40張以上),就可以很快的訓練出自己的模型,識別準確率95%以上。(只是舉個最簡單的例子,實際中,“坑”還是有的。。)
傳統的機器學習與遷移學習有什麽不同呢?
在機器學習的監督學習場景中,如果我們要針對一些任務和域 A 訓練一個模型,我們會假設被提供了針對同一個域和任務的標簽數據。如下圖所示,其中我們的模型 A 在訓練數據和測試數據中的域和任務都是一樣的。
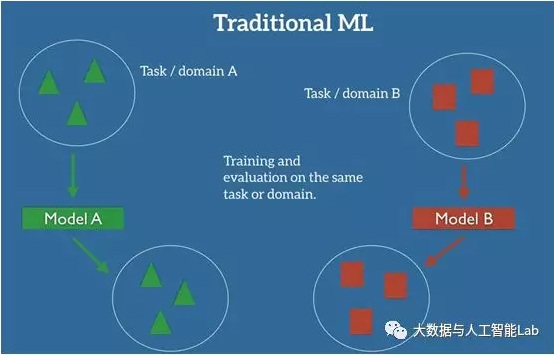
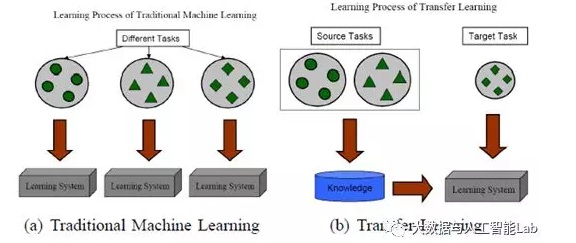
即使是跟遷移學習比較相似的多任務學習,多任務學習是對目標域和源域進行共同學習,而遷移學習主要是對通過對源域的學習解決目標域的識別任務。下圖就展示了傳統的機器學習方法與遷移學習的區別:
什麽適合遷移?
在一些學習任務中有一些特征是個體所特有的,這些特征不可以遷移。而有些特征是在所有的個體中具有貢獻的,這些可以進行遷移。
有些時候如果遷移的不合適則會導致負遷移,例如當源域和目標域的任務毫不相關時有可能會導致負遷移。
遷移學習的分類
根據 Sinno Jialin Pan 和 Qiang Yang 在 TKDE 2010 上的文章,可將遷移學習算法,根據所要遷移的知識表示形式(即 “what to transfer”),分為四大類:
- 基於實例的遷移學習(instance-based transfer learning):源領域(source domain)中的數據(data)的某一部分可以通過reweighting的方法重用,用於target domain的學習。
- 基於特征表示的遷移學習(feature-representation transfer learning):通過source domain學習一個好的(good)的特征表示,把知識通過特征的形式進行編碼,並從suorce domain傳遞到target domain,提升target domain任務效果。
- 基於參數(模型)的遷移學習(parameter-transfer learning):target domain和source domian的任務之間共享相同的模型參數(model parameters)或者是服從相同的先驗分布(prior distribution)。
- 基於關系知識遷移學習(relational-knowledge transfer learning):相關領域之間的知識遷移,假設source domain和target domain中,數據(data)之間聯系關系是相同的。
前三類遷移學習方式都要求數據(data)獨立同分布假設。同時,四類遷移學習方式都要求選擇的source domain與target domain相關,
具體描述如下(按照遷移學習基本方法):
(1)基於實例的遷移學習方法
在源域中找到與目標域相似的數據,把這個數據的權值進行調整,使得新的數據與目標域的數據進行匹配。然後進行訓練學習,得到適用於目標域的模型。這樣的方法優點是方法簡單,實現容易。缺點在於權重的選擇與相似度的度量依賴經驗,且源域與目標域的數據分布往往不同。

(2)基於特征的遷移學習方法
當源域和目標域含有一些共同的交叉特征時,我們可以通過特征變換,將源域和目標域的特征變換到相同空間,使得該空間中源域數據與目標域數據具有相同分布的數據分布,然後進行傳統的機器學習。優點是對大多數方法適用,效果較好。缺點在於難於求解,容易發生過適配。

需要註意的的是基於特征的遷移學習方法和基於實例的遷移學習方法的不同是基於特征的遷移學習需要進行特征變換來使得源域和目標域數據到到同一特征空間,而基於實例的遷移學習只是從實際數據中進行選擇來得到與目標域相似的部分數據,然後直接學習。
(3)基於模型的遷移學習方法
源域和目標域共享模型參數,也就是將之前在源域中通過大量數據訓練好的模型應用到目標域上進行預測。基於模型的遷移學習方法比較直接,這樣的方法優點是可以充分利用模型之間存在的相似性。缺點在於模型參數不易收斂。
舉個例子:比如利用上千萬的圖象來訓練好一個圖象識別的系統,當我們遇到一個新的圖象領域問題的時候,就不用再去找幾千萬個圖象來訓練了,只需把原來訓練好的模型遷移到新的領域,在新的領域往往只需幾萬張圖片就夠,同樣可以得到很高的精度。

(4)基於關系的遷移學習方法
當兩個域是相似的時候,那麽它們之間會共享某種相似關系,將源域中學習到的邏輯網絡關系應用到目標域上來進行遷移,比方說生物病毒傳播規律到計算機病毒傳播規律的遷移。這部分的研究工作比較少。典型方法就是mapping的方法

下圖來總結以上的知識(可以看成歸納式遷移學習是最廣泛應用的):

另外,如果按特征空間,可分為:
同構遷移學習(Homogeneous TL): 源域和目標域的特征維度相同分布不同
異構遷移學習(Heterogeneous TL):源域和目標域的特征空間不同
下圖作為遷移學習分類的一個梳理:

遷移學習的應用
用於情感分類,圖像分類,命名實體識別,WiFi信號定位,自動化設計,中文到英文翻譯等問題。
遷移學習的價值
- 復用現有知識域數據,已有的大量工作不至於完全丟棄;
- 不需要再去花費巨大代價去重新采集和標定龐大的新數據集,也有可能數據根本無法獲取;
- 對於快速出現的新領域,能夠快速遷移和應用,體現時效性優勢。
整理參考鏈接如下:
http://cs231n.github.io/transfer-learning/
http://yosinski.com/transfer
https://my.oschina.net/u/876354/blog/1614883
http://baijiahao.baidu.com/s?id=1590903538875880299&wfr=spider&for=pc
http://www.ijiandao.com/2b/baijia/86640.html
遷移學習(Transfer Learning)