
Sentinel超最大連接數
某準生產系統,測試運行一段時間後程序和命令行工具連接sentinel均報錯,報錯信息為:
jedis.exceptions.JedisDataException: ERR max number of clients reached
此時應用創建redis新連接由於sentinel已經無法響應而無法找到master的IP與端口,因此無法連接redis,並且此時如果發生redis宕機亦無法進行生產切換。
2. 問題初步排查過程
首先,通過netstat對sentinel所監聽端口26379進行連接數統計,此時連接則報錯。如下圖:

通過sentinel服務器端統計發現,redis sentinel 的連接中大部分都是來自於兩臺非同網段(中間有防火墻)的應用服務器連接(均為Established狀態),並且來自其的連接也大約半個小時後穩步增加一次,而同網段的應用服務器連接sentinel的連接數基本保持一致。排除了應用的特殊性(采用的jedis版本和封裝的工具類都是一樣的)後,初步判斷此問題與網絡有關,更詳細的說是連接數增加與防火墻切斷連接後的重連有關。
3. 問題查證過程
此問題分為兩個子問題: 1) 防火墻將TCP連接設置為無效時sentinel服務器為何沒有斷開連接,保持Established狀態? 2) 為何連接數還會不斷增加?
對於問題1) ,TCP在三次握手建立連接時OS會啟動一個Timer來進行倒計時,經過一個設定的時間(這個時間建立socket的程序可以設置,如果沒有設置則采用OS的參數tcp_keepalive_time,這個參數默認為7200s,即2小時)後這個連接還是沒有數據傳輸,它就會以一定間隔(程序可以設定,如果沒有設置則采用OS的參數tcp_keepalive_intvl,默認為75s)發出N(程序可以設定,如果沒有設置則采用OS的參數tcp_keepalive_probes,默認為9次)次Keep Alive包。TCP連接就是通過上述的過程,在沒有流量時是通過發送TCP Keep-Alive數據包,然後對方回應TCP Keep-Alive ACK來確定信道是否還在真實連接。通過查看Sentinel
對於防火墻,通過翻閱防火墻技術資料(詳見下列描述,摘自:《Junos Enterprise Switching: A Practical Guide to Junos Switches and Certification》),我司采用的Juniper防火墻對於沒有流量的TCP連接默認是30分鐘,30分鐘內沒有流量就會斷掉鏈路,而不會發送TCP Reset,同時在防火墻策略上並沒有開長連接,使用的即為此默認設置。

因此在防火墻每半個小時將連接置為無效時,sentinel同時又禁止了Keepalive(因為默認設置Keepalive為0,即disable發送Keepalive包)。應用服務器的jedis雖然開啟了keepalive,但是它發送的keepalive包由於防火墻已經將此鏈路標記為無效,而無法發送到sentinel端,而且jedis由於采用了OS默認參數,因此需要等待tcp_keepalive_time(2小時)後才啟動發送Keep Alive包進行探活的,在tcp_keepalive_time+tcp_keepalive_intvl*tcp_keepalive_probes=7895s=131.58分鐘後,jedis端才會認定這個連接斷掉而清理掉這個連接。簡單的說就是jedis會在很長一段時間後才會發keepalive包,並且這個包也是發不到sentinel上的,而sentinel本身也不會發送keepalive包,所以從sentinel這端看連接一直存在,而從jedis那端看7895s之後就會清理一次連接。這也解釋了為什麽防火墻將TCP連接斷開後,sentinel端的連接並沒有釋放。
對於問題2) ,翻閱jedis源代碼,jedis通過連接sentinel並pubsub來監聽集群事件,以確定是否發生了切換,並且拿到新的master 地址和端口。如果斷開則會5秒後嘗試重連(JedisSentinelPool.java)。
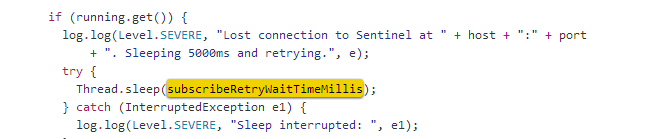
因此,這是導致連接數不斷上升的原因。 綜上,防火墻相對頻繁的斷開和服務器不斷重連導致在一個相對較短的時間內連接驟增,造成到達sentinel最大連接數,sentinel 的最大連接數在redis.h中定義,為10000:
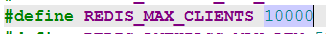
4. 問題解決過程
此系統由於訪問關系與網段規劃間的安全問題,必須跨越防火墻,因此試圖從配置角度解決此問題。
首先,聯系網絡相關同事,進行網絡變更,開啟從應用服務器到sentinel的鏈路相對的長連接,即無流量超時而斷開的時間設置為8小時。以此手段降低斷開頻率,以便緩解短時間內不斷重試連接造成的sentinel連接增長。
然後,通過閱讀redis源代碼(net.c),發現,sentinel也采用了redis 所有參數設置(通過config.c的函數void loadServerConfigFromString(char *config))。因此,通過設置redis 的下列兩個參數可以解決這個問題,第一個參數是TCP Keepalive參數,此參數默認為0,也就是不發送keepalive。也就是改變OS默認的tcp_keepalive_time參數(在Unix C的socket編程中TCP_KEEPIDLE參數對應OS 的tcp_keepalive_time參數)。

該參數的官方解釋為:
# TCP keepalive. # # If non-zero, use SO_KEEPALIVE to send TCP ACKs to clients in absence # of communication. This is useful for two reasons: # # 1) Detect dead peers. # 2) Take the connection alive from the point of view of network # equipment in the middle. # # On Linux, the specified value (in seconds) is the period used to send ACKs. # Note that to close the connection the double of the time is needed. # On other kernels the period depends on the kernel configuration. # # A reasonable value for this option is 60 seconds.
我們設置為tcp-keepalive 60,加快回收連接速度,從網絡斷開到連接清理時間縮短為60+75*9=12.25分鐘。
同時,通過設置maxclients為65536,增大sentinel最大連接數,使得在上述12.25分鐘即使有某種異常導致sentinel連接數增加也不至於到達最大限制。此參數的官方解釋為:
################################### LIMITS #################################### # Set the max number of connected clients at the same time. By default # this limit is set to 10000 clients, however if the Redis server is not # able to configure the process file limit to allow for the specified limit # the max number of allowed clients is set to the current file limit # minus 32 (as Redis reserves a few file descriptors for internal uses). # # Once the limit is reached Redis will close all the new connections sending # an error 'max number of clients reached'. # maxclients 10000
對於redis 的timeout參數,由於啟用這個參數有程序微小開銷(會調用redis.c中的int clientsCronHandleTimeout(redisClient *c, mstime_t now_ms)),決定保持默認為0,而通過上述參數使用OS進行連接斷開。
5. 問題解決結果
通過開發、網絡和數據庫團隊的協同努力,配置上述參數和修改防火墻策略後,手動增加sentinel進程,超過原默認最大連接數10000後sentinel可以正常訪問操作,並且通過tcpdump進行抓包,在指定時間內(1分鐘),就有KeepAlive包對每個sentinel TCP連接進行探活,經過觀察sentinel連接穩定,再未出現短時間內暴漲的情況。
6. 問題後續
在redis中默認不開啟keepalive就是為了盡可能減小網絡負載,榨幹網絡性能,盡可能達到redis的。在後續的程序運行中,如果發現網絡是瓶頸時(在相當長的一段時間內不會),可以加大sentinel的keepalive參數,減小keepalive數據包的傳輸,這個修改是不影響redis對外服務的。
參考文檔: http://www.tldp.org/HOWTO/html_single/TCP-Keepalive-HOWTO/
附錄:如何用TCPDUMP進行keep alive抓包
tcpdump -pni bond0 -v "src port 26379 and ( tcp[tcpflags] & tcp-ack != 0 and ( (ip[2:2] - ((ip[0]&0xf)<<2) ) - ((tcp[12]&0xf0)>>2) ) == 0 ) "
7. 問題再後續
我們後來在這個應用上發現一旦網絡有抖動,sentinel的連接增加就回大幅度增加,後來通過jmap查看sentinelpool的實例竟然多達200多個,也就是說這個就是程序的問題,在sentinelpool上不應該多次實例化,而是采用已有連接進行重連。

Sentinel超最大連接數