
Batch Normalization原理
Batch Normalization導讀
博客轉載自:https://blog.csdn.net/malefactor/article/details/51476961
作者: 張俊林
為什麽深度神經網絡隨著網絡深度加深,訓練起來越困難,收斂越來越慢?這是個在DL領域很接近本質的好問題。很多論文都是解決這個問題的,比如ReLU激活函數,再比如Residual Network,BN本質上也是解釋並從某個不同的角度來解決這個問題的。
|“Internal Covariate Shift”問題從論文名字可以看出,BN是用來解決“InternalCovariate Shift”問題的,那麽首先得理解什麽是“Internal Covariate Shift”?
論文首先說明Mini-Batch SGD相對於One Example SGD的兩個優勢:梯度更新方向更準確;並行計算速度快;(本文作者:為啥要說這些?因為BatchNorm是基於Mini-Batch SGD的,所以先誇下Mini-Batch SGD,當然也是大實話);
然後吐槽下SGD訓練的缺點:超參數調起來很麻煩。(本文作者:作者隱含意思是用我大BN就能解決很多SGD的缺點:用了大BN,媽媽再也不用擔心我的調參能力啦)
接著引入covariate shift的概念:如果ML系統實例集合<X,Y>中的輸入值X的分布老是變,這不符合IID假設啊,那您怎麽讓我穩定的學規律啊,這不得引入遷移學習才能搞定嗎,我們的ML系統還得去學習怎麽迎合這種分布變化啊。
對於深度學習這種包含很多隱層的網絡結構,在訓練過程中,因為各層參數老在變,所以每個隱層都會面臨covariate shift的問題,也就是在訓練過程中,隱層的輸入分布老是變來變去,這就是所謂的“Internal Covariate Shift”,Internal指的是深層網絡的隱層,是發生在網絡內部的事情,而不是covariate shift問題只發生在輸入層。
然後提出了BatchNorm的基本思想:能不能讓每個隱層節點的激活輸入分布固定下來呢?這樣就避免了“Internal Covariate Shift”問題了。
BN不是憑空拍腦袋拍出來的好點子,它是有啟發來源的:之前的研究表明如果在圖像處理中對輸入圖像進行白化(Whiten)操作的話——所謂白化,就是對輸入數據分布變換到0均值,單位方差的正態分布——那麽神經網絡會較快收斂,那麽BN作者就開始推論了:圖像是深度神經網絡的輸入層,做白化能加快收斂,那麽其實對於深度網絡來說,其中某個隱層的神經元是下一層的輸入,意思是其實深度神經網絡的每一個隱層都是輸入層,不過是相對下一層來說而已,那麽能不能對每個隱層都做白化呢?這就是啟發BN產生的原初想法,而BN也確實就是這麽做的,可以理解為對深層神經網絡每個隱層神經元的激活值做簡化版本的白化操作。
|BatchNorm的本質思想
BN的基本思想其實相當直觀:因為深層神經網絡在做非線性變換前的激活輸入值(就是那個x=WU+B,U是輸入)隨著網絡深度加深或者在訓練過程中,其分布逐漸發生偏移或者變動,之所以訓練收斂慢,一般是整體分布逐漸往非線性函數的取值區間的上下限兩端靠近(對於Sigmoid函數來說,意味著激活輸入值WU+B是大的負值或正值),所以這導致後向傳播時低層神經網絡的梯度消失,這是訓練深層神經網絡收斂越來越慢的本質原因,而BN就是通過一定的規範化手段,把每層神經網絡任意神經元這個輸入值的分布強行拉回到均值為0方差為1的標準正太分布而不是蘿莉分布(哦,是正態分布),其實就是把越來越偏的分布強制拉回比較標準的分布,這樣使得激活輸入值落在非線性函數對輸入比較敏感的區域,這樣輸入的小變化就會導致損失函數較大的變化,意思是這樣讓梯度變大,避免梯度消失問題產生,而且梯度變大意味著學習收斂速度快,能大大加快訓練速度。
THAT’S IT。其實一句話就是:對於每個隱層神經元,把逐漸向非線性函數映射後向取值區間極限飽和區靠攏的輸入分布強制拉回到均值為0方差為1的比較標準的正態分布,使得非線性變換函數的輸入值落入對輸入比較敏感的區域,以此避免梯度消失問題。因為梯度一直都能保持比較大的狀態,所以很明顯對神經網絡的參數調整效率比較高,就是變動大,就是說向損失函數最優值邁動的步子大,也就是說收斂地快。NB說到底就是這麽個機制,方法很簡單,道理很深刻。
上面說得還是顯得抽象,下面更形象地表達下這種調整到底代表什麽含義。
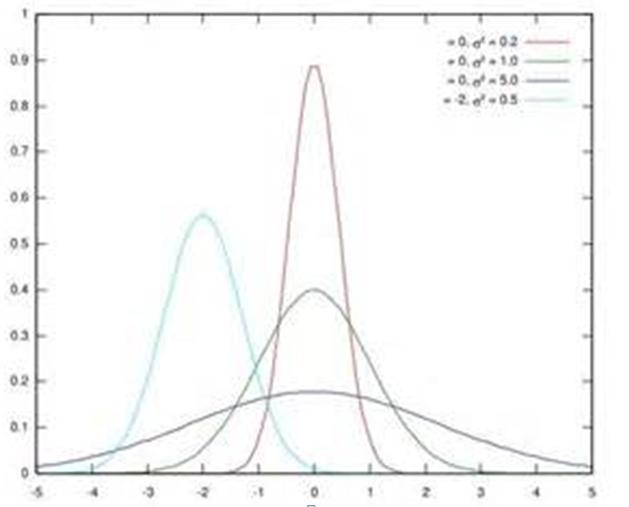
圖1. 幾個正態分布
假設某個隱層神經元原先的激活輸入x取值符合正態分布,正態分布均值是-2,方差是0.5,對應上圖中最左端的淺藍色曲線,通過BN後轉換為均值為0,方差是1的正態分布(對應上圖中的深藍色圖形),意味著什麽,意味著輸入x的取值正態分布整體右移2(均值的變化),圖形曲線更平緩了(方差增大的變化)。這個圖的意思是,BN其實就是把每個隱層神經元的激活輸入分布從偏離均值為0方差為1的正態分布通過平移均值壓縮或者擴大曲線尖銳程度,調整為均值為0方差為1的正態分布。
那麽把激活輸入x調整到這個正態分布有什麽用?
首先我們看下均值為0,方差為1的標準正態分布代表什麽含義:
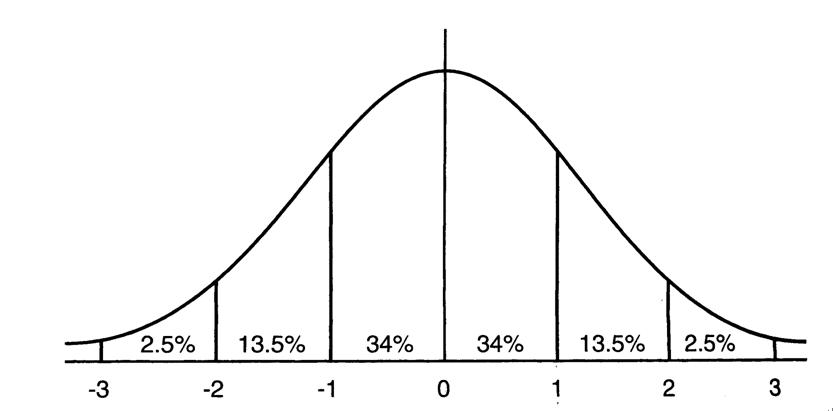
圖2.均值為0方差為1的標準正態分布圖
這意味著在一個標準差範圍內,也就是說64%的概率x其值落在[-1,1]的範圍內,在兩個標準差範圍內,也就是說95%的概率x其值落在了[-2,2]的範圍內。那麽這又意味著什麽?我們知道,激活值x=WU+B,U是真正的輸入,x是某個神經元的激活值,假設非線性函數是sigmoid,那麽看下sigmoid(x)其圖形:
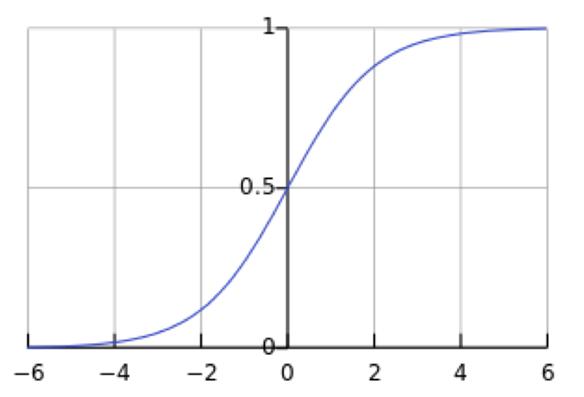
圖3. Sigmoid(x)
及sigmoid(x)的導數為:G’=f(x)*(1-f(x)),因為f(x)=sigmoid(x)在0到1之間,所以G’在0到0.25之間,其對應的圖如下:
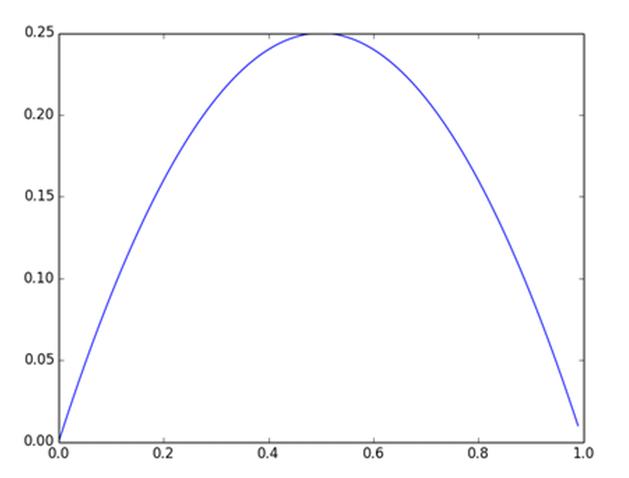
圖4. Sigmoid(x)導數圖(導數圖x軸的範圍有誤,應該是負無窮到正無窮)
假設沒有經過BN調整前x的原先正態分布均值是-6,方差是1,那麽意味著95%的值落在了[-8,-4]之間,那麽對應的Sigmoid(x)函數的值明顯接近於0,這是典型的梯度飽和區,在這個區域裏梯度變化很慢,為什麽是梯度飽和區?請看下sigmoid(x)如果取值接近0或者接近於1的時候對應導數函數取值,接近於0,意味著梯度變化很小甚至消失。而假設經過BN後,均值是0,方差是1,那麽意味著95%的x值落在了[-2,2]區間內,很明顯這一段是sigmoid(x)函數接近於線性變換的區域,意味著x的小變化會導致非線性函數值較大的變化,也即是梯度變化較大,對應導數函數圖中明顯大於0的區域,就是梯度非飽和區。
從上面幾個圖應該看出來BN在幹什麽了吧?其實就是把隱層神經元激活輸入x=WU+B從變化不拘一格的正態分布通過BN操作拉回到了均值為0,方差為1的正態分布,即原始正態分布中心左移或者右移到以0為均值,拉伸或者縮減形態形成以1為方差的圖形。什麽意思?就是說經過BN後,目前大部分Activation的值落入非線性函數的線性區內,其對應的導數遠離導數飽和區,這樣來加速訓練收斂過程。
但是很明顯,看到這裏,稍微了解神經網絡的讀者一般會提出一個疑問:如果都通過BN,那麽不就跟把非線性函數替換成線性函數效果相同了?這意味著什麽?我們知道,如果是多層的線性函數變換其實這個深層是沒有意義的,因為多層線性網絡跟一層線性網絡是等價的。這意味著網絡的表達能力下降了,這也意味著深度的意義就沒有了。所以BN為了保證非線性的獲得,對變換後的滿足均值為0方差為1的x又進行了scale加上shift操作(y=scale*x+shift),每個神經元增加了兩個參數scale和shift參數,這兩個參數是通過訓練學習到的,意思是通過scale和shift把這個值從標準正態分布左移或者由移一點並長胖一點或者變瘦一點,每個實例挪動的程度不一樣,這樣等價於非線性函數的值從正中心周圍的線性區往非線性區動了動。核心思想應該是想找到一個線性和非線性的較好平衡點,既能享受非線性的較強表達能力的好處,又避免太靠非線性區兩頭使得網絡收斂速度太慢。當然,這是我的理解,論文作者並未明確這樣說。但是很明顯這裏的scale和shift操作是會有爭議的,因為按照論文作者論文裏寫的理想狀態,就會又通過scale和shift操作把變換後的x調整回未變換的狀態,那不是饒了一圈又繞回去原始的“Internal Covariate Shift”問題裏去了嗎,感覺論文作者並未能夠清楚地解釋scale和shift操作的理論原因。
|訓練階段如何做BatchNorm
上面是對BN的抽象分析和解釋,具體在Mini-Batch SGD下做BN怎麽做?其實論文裏面這塊寫得很清楚也容易理解。為了保證這篇文章完整性,這裏簡單說明下。
假設對於一個深層神經網絡來說,其中兩層結構如下:
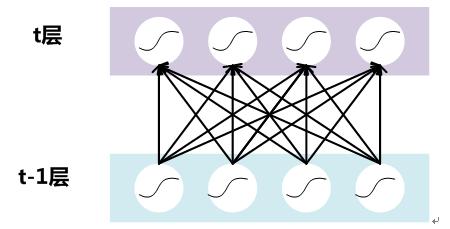
圖5. DNN其中兩層
要對每個隱層神經元的激活值做BN,可以想象成每個隱層又加上了一層BN操作層,它位於X=WU+B激活值獲得之後,非線性函數變換之前,其圖示如下:
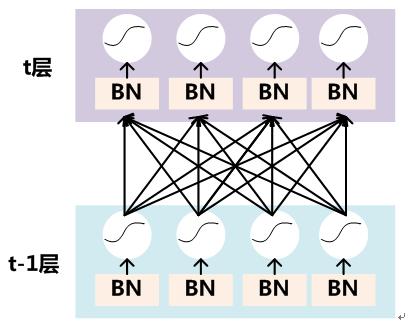
圖6. BN操作
對於Mini-Batch SGD來說,一次訓練過程裏面包含m個訓練實例,其具體BN操作就是對於隱層內每個神經元的激活值來說,進行如下變換:
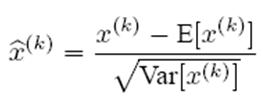
要註意,這裏t層某個神經元的x(k)不是指原始輸入,就是說不是t-1層每個神經元的輸出,而是t層這個神經元的激活x=WU+B,這裏的U才是t-1層神經元的輸出。
變換的意思是:某個神經元對應的原始的激活x通過減去mini-Batch內m個實例獲得的m個激活x求得的均值E(x)並除以求得的方差Var(x)來進行轉換。
上文說過經過這個變換後某個神經元的激活x形成了均值為0,方差為1的正態分布,目的是把值往後續要進行的非線性變換的線性區拉動,增大導數值,增強反向傳播信息流動性,加快訓練收斂速度。但是這樣會導致網絡表達能力下降,為了防止這一點,每個神經元增加兩個調節參數(scale和shift),這兩個參數是通過訓練來學習到的,用來對變換後的激活反變換,使得網絡表達能力增強,即對變換後的激活進行如下的scale和shift操作,這其實是變換的反操作:
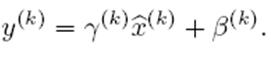
BN其具體操作流程,如論文中描述的一樣:

過程非常清楚,就是上述公式的流程化描述,這裏不解釋了,直接應該能看懂。
|BatchNorm的推理過程
BN在訓練的時候可以根據Mini-Batch裏的若幹訓練實例進行激活數值調整,但是在推理(inference)的過程中,很明顯輸入就只有一個實例,看不到Mini-Batch其它實例,那麽這時候怎麽對輸入做BN呢?因為很明顯一個實例是沒法算實例集合求出的均值和方差的。這可如何是好?這可如何是好?這可如何是好?
既然沒有從Mini-Batch數據裏可以得到的統計量,那就想其它辦法來獲得這個統計量,就是均值和方差。可以用從所有訓練實例中獲得的統計量來代替Mini-Batch裏面m個訓練實例獲得的均值和方差統計量,因為本來就打算用全局的統計量,只是因為計算量等太大所以才會用Mini-Batch這種簡化方式的,那麽在推理的時候直接用全局統計量即可。
決定了獲得統計量的數據範圍,那麽接下來的問題是如何獲得均值和方差的問題。很簡單,因為每次做Mini-Batch訓練時,都會有那個Mini-Batch裏m個訓練實例獲得的均值和方差,現在要全局統計量,只要把每個Mini-Batch的均值和方差統計量記住,然後對這些均值和方差求其對應的數學期望即可得出全局統計量,即:
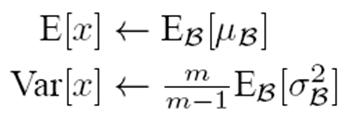
有了均值和方差,每個隱層神經元也已經有對應訓練好的Scaling參數和Shift參數,就可以在推導的時候對每個神經元的激活數據計算NB進行變換了,在推理過程中進行NB采取如下方式:
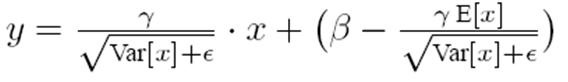
這個公式其實和訓練時

是等價的,通過簡單的合並計算推導就可以得出這個結論。那麽為啥要寫成這個變換形式呢?我猜作者這麽寫的意思是:在實際運行的時候,按照這種變體形式可以減少計算量,為啥呢?因為對於每個隱層節點來說:

都是固定值,這樣這兩個值可以事先算好存起來,在推理的時候直接用就行了,這樣比原始的公式每一步驟都現算少了除法的運算過程,乍一看也沒少多少計算量,但是如果隱層節點個數多的話節省的計算量就比較多了。
|BatchNorm的好處
BatchNorm為什麽NB呢,關鍵還是效果好。不僅僅極大提升了訓練速度,收斂過程大大加快,還能增加分類效果,一種解釋是這是類似於Dropout的一種防止過擬合的正則化表達方式,所以不用Dropout也能達到相當的效果。另外調參過程也簡單多了,對於初始化要求沒那麽高,而且可以使用大的學習率等。總而言之,經過這麽簡單的變換,帶來的好處多得很,這也是為何現在BN這麽快流行起來的原因。
tensorflow代碼:
https://github.com/yongyehuang/Tensorflow-Tutorial/tree/master/models/m01_batch_normalization
1.mnist_cnn.py
# -*- coding:utf-8 -*- """網絡結構定義。 關於 tf.layers.batch_normalization() 的理解參考: [tensorflow中batch normalization的用法](https://www.cnblogs.com/hrlnw/p/7227447.html) """ from __future__ import print_function, division, absolute_import import tensorflow as tf class Model(object): def __init__(self, settings): self.model_name = settings.model_name self.img_size = settings.img_size self.n_channel = settings.n_channel self.n_class = settings.n_class self.drop_rate = settings.drop_rate self.global_step = tf.Variable(0, trainable=False, name=‘Global_Step‘) self.learning_rate = tf.train.exponential_decay(settings.learning_rate, self.global_step, settings.decay_step, settings.decay_rate, staircase=True) self.conv_weight_initializer = tf.contrib.layers.xavier_initializer(uniform=True) self.conv_biases_initializer = tf.zeros_initializer() # 最後一個全連接層的初始化 self.fc_weight_initializer = tf.truncated_normal_initializer(0.0, 0.005) self.fc_biases_initializer = tf.constant_initializer(0.1) # placeholders with tf.name_scope(‘Inputs‘): self.X_inputs = tf.placeholder(tf.float32, [None, self.img_size, self.img_size, self.n_channel], name=‘X_inputs‘) self.y_inputs = tf.placeholder(tf.int64, [None], name=‘y_input‘) self.logits_train = self.inference(is_training=True, reuse=False) self.logits_test = self.inference(is_training=False, reuse=True) # 預測結果 self.pred_lables = tf.argmax(self.logits_test, axis=1) self.pred_probas = tf.nn.softmax(self.logits_test) self.test_loss = tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits( labels=tf.cast(self.y_inputs, dtype=tf.int32), logits=self.logits_test)) self.test_acc = tf.reduce_mean(tf.cast(tf.equal(self.pred_lables, self.y_inputs), tf.float32)) # 訓練結果 self.train_lables = tf.argmax(self.logits_train, axis=1) self.train_loss = tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits( labels=tf.cast(self.y_inputs, dtype=tf.int32), logits=self.logits_train)) self.train_acc = tf.reduce_mean(tf.cast(tf.equal(self.train_lables, self.y_inputs), tf.float32)) self.optimizer = tf.train.AdamOptimizer(learning_rate=self.learning_rate) update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS) """ **註意:** 下面一定要使用這樣的方式來寫。 with tf.control_dependencies(update_ops) 這句話的意思是當運行下面的內容(train_op) 時,一定先執行 update_ops 的所有操作。 這裏的 update_ops 在這裏主要是更新 BN 層的滑動平均值和滑動方差。 除了 BN 層外,還有 center loss 中也采用這樣的方式,在 center loss 中,update_ops 操作主要更新類中心向量。 因為之前在 center loss 犯過沒更新 center 的錯誤,所以印象非常深刻。 """ with tf.control_dependencies(update_ops): # 這句話的意思是當運行下面的內容(train_op) 時,一定先執行 update_ops 的所有操作 self.train_op = self.optimizer.minimize(self.train_loss, global_step=self.global_step) def inference(self, is_training, reuse=False): """帶 BN 層的CNN """ with tf.variable_scope(‘cnn‘, reuse=reuse): # 第一個卷積層 + BN + max_pooling conv1 = tf.layers.conv2d(self.X_inputs, filters=32, kernel_size=5, strides=1, padding=‘same‘, kernel_initializer=self.conv_weight_initializer, name=‘conv1‘) bn1 = tf.layers.batch_normalization(conv1, training=is_training, name=‘bn1‘) bn1 = tf.nn.relu(bn1) # 一般都是先經過 BN 層再加激活函數的 pool1 = tf.layers.max_pooling2d(bn1, pool_size=2, strides=2, padding=‘same‘, name=‘pool1‘) # 第二個卷積層 + BN + max_pooling conv2 = tf.layers.conv2d(pool1, filters=64, kernel_size=5, strides=1, padding=‘same‘, kernel_initializer=self.conv_weight_initializer, name=‘conv2‘) bn2 = tf.layers.batch_normalization(conv2, training=is_training, name=‘bn2‘) bn2 = tf.nn.relu(bn2) # 一般都是先經過 BN 層再加激活函數的 pool2 = tf.layers.max_pooling2d(bn2, pool_size=2, strides=2, padding=‘same‘, name=‘pool2‘) # 全連接,使用卷積來實現 _, k_height, k_width, k_depth = pool2.get_shape().as_list() fc1 = tf.layers.conv2d(pool2, filters=1024, kernel_size=k_height, name=‘fc1‘) bn3 = tf.layers.batch_normalization(fc1, training=is_training, name=‘bn3‘) bn3 = tf.nn.relu(bn3) # dropout, 如果 is_training = False 就不會執行 dropout fc1_drop = tf.layers.dropout(bn3, rate=self.drop_rate, training=is_training) # 最後的輸出層 flatten_layer = tf.layers.flatten(fc1_drop) out = tf.layers.dense(flatten_layer, units=self.n_class) return out def inference2(self, is_training, reuse=False): """不帶 BN 層的 CNN。""" with tf.variable_scope(‘cnn‘, reuse=reuse): # 第一個卷積層 + BN + max_pooling conv1 = tf.layers.conv2d(self.X_inputs, filters=32, kernel_size=5, strides=1, padding=‘same‘, activation=tf.nn.relu, kernel_initializer=self.conv_weight_initializer, name=‘conv1‘) pool1 = tf.layers.max_pooling2d(conv1, pool_size=2, strides=2, padding=‘same‘, name=‘pool1‘) # 第二個卷積層 + BN + max_pooling conv2 = tf.layers.conv2d(pool1, filters=64, kernel_size=5, strides=1, padding=‘same‘, activation=tf.nn.relu, kernel_initializer=self.conv_weight_initializer, name=‘conv2‘) pool2 = tf.layers.max_pooling2d(conv2, pool_size=2, strides=2, padding=‘same‘, name=‘pool2‘) # 全連接,使用卷積來實現 _, k_height, k_width, k_depth = pool2.get_shape().as_list() fc1 = tf.layers.conv2d(pool2, filters=1024, kernel_size=k_height, activation=tf.nn.relu, name=‘fc1‘) # dropout, 如果 is_training = False 就不會執行 dropout fc1_drop = tf.layers.dropout(fc1, rate=self.drop_rate, training=is_training) # 最後的輸出層 flatten_layer = tf.layers.flatten(fc1_drop) out = tf.layers.dense(flatten_layer, units=self.n_class) return out
2.train.py
# -*- coding:utf-8 -*- from __future__ import print_function, division, absolute_import import tensorflow as tf import os import time from mnist_cnn import Model class Settings(object): def __init__(self): self.model_name = ‘mnist_cnn‘ self.img_size = 28 self.n_channel = 1 self.n_class = 10 self.drop_rate = 0.5 self.learning_rate = 0.001 self.decay_step = 2000 self.decay_rate = 0.5 self.training_steps = 10000 # 耗時 90s self.batch_size = 100 self.summary_path = ‘summary/‘ + self.model_name + ‘/‘ self.ckpt_path = ‘ckpt/‘ + self.model_name + ‘/‘ if not os.path.exists(self.summary_path): os.makedirs(self.summary_path) if not os.path.exists(self.ckpt_path): os.makedirs(self.ckpt_path) def main(): """模型訓練。""" from tensorflow.examples.tutorials.mnist import input_data mnist = input_data.read_data_sets("../../data/MNIST_data", one_hot=False) print(mnist.test.labels.shape) print(mnist.train.labels.shape) my_setting = Settings() with tf.variable_scope(my_setting.model_name): model = Model(my_setting) # 模型要保存的變量 var_list = tf.trainable_variables() if model.global_step not in var_list: var_list.append(model.global_step) # 添加 BN 層的均值和方差 global_vars = tf.global_variables() bn_moving_vars = [v for v in global_vars if ‘moving_mean‘ in v.name] bn_moving_vars += [v for v in global_vars if ‘moving_variance‘ in v.name] var_list += bn_moving_vars # 創建Saver saver = tf.train.Saver(var_list=var_list) config = tf.ConfigProto() config.gpu_options.allow_growth = True with tf.Session(config=config) as sess: print("initializing variables.") sess.run(tf.global_variables_initializer()) sess.run(tf.local_variables_initializer()) if os.path.exists(my_setting.ckpt_path + ‘checkpoint‘): print("restore checkpoint.") saver.restore(sess, tf.train.latest_checkpoint(my_setting.ckpt_path)) tic = time.time() for step in range(my_setting.training_steps): if 0 == step % 100: X_batch, y_batch = mnist.train.next_batch(my_setting.batch_size, shuffle=True) X_batch = X_batch.reshape([-1, 28, 28, 1]) _, g_step, train_loss, train_acc = sess.run( [model.train_op, model.global_step, model.train_loss, model.train_acc], feed_dict={model.X_inputs: X_batch, model.y_inputs: y_batch}) X_batch, y_batch = mnist.test.next_batch(my_setting.batch_size, shuffle=True) X_batch = X_batch.reshape([-1, 28, 28, 1]) test_loss, test_acc = sess.run([model.test_loss, model.test_acc], feed_dict={model.X_inputs: X_batch, model.y_inputs: y_batch}) print( "Global_step={:.2f}, train_loss={:.2f}, train_acc={:.2f}; test_loss={:.2f}, test_acc={:.2f}; pass {:.2f}s".format( g_step, train_loss, train_acc, test_loss, test_acc, time.time() - tic )) else: X_batch, y_batch = mnist.train.next_batch(my_setting.batch_size, shuffle=True) X_batch = X_batch.reshape([-1, 28, 28, 1]) sess.run([model.train_op], feed_dict={model.X_inputs: X_batch, model.y_inputs: y_batch}) if 0 == (step + 1) % 1000: path = saver.save(sess, os.path.join(my_setting.ckpt_path, ‘model.ckpt‘), global_step=sess.run(model.global_step)) print("Save model to {} ".format(path)) if __name__ == ‘__main__‘: main()
3.predict.py
# -*- coding:utf-8 -*- from __future__ import print_function, division, absolute_import import tensorflow as tf import numpy as np import os import time from mnist_cnn import Model class Settings(object): def __init__(self): self.model_name = ‘mnist_cnn‘ self.img_size = 28 self.n_channel = 1 self.n_class = 10 self.drop_rate = 0.5 self.learning_rate = 0.001 self.decay_step = 2000 self.decay_rate = 0.5 self.training_steps = 10000 self.batch_size = 100 self.summary_path = ‘summary/‘ + self.model_name + ‘/‘ self.ckpt_path = ‘ckpt/‘ + self.model_name + ‘/‘ if not os.path.exists(self.summary_path): os.makedirs(self.summary_path) if not os.path.exists(self.ckpt_path): os.makedirs(self.ckpt_path) def main(): """模型訓練。""" from tensorflow.examples.tutorials.mnist import input_data mnist = input_data.read_data_sets("../../data/MNIST_data", one_hot=False) print(mnist.test.labels.shape) print(mnist.train.labels.shape) my_setting = Settings() with tf.variable_scope(my_setting.model_name): model = Model(my_setting) # 模型要保存的變量 var_list = tf.trainable_variables() if model.global_step not in var_list: var_list.append(model.global_step) # 添加 BN 層的均值和方差 global_vars = tf.global_variables() bn_moving_vars = [v for v in global_vars if ‘moving_mean‘ in v.name] bn_moving_vars += [v for v in global_vars if ‘moving_variance‘ in v.name] var_list += bn_moving_vars # 創建Saver saver = tf.train.Saver(var_list=var_list) config = tf.ConfigProto() config.gpu_options.allow_growth = True with tf.Session(config=config) as sess: if not os.path.exists(my_setting.ckpt_path + ‘checkpoint‘): print("There is no checkpoit, please check out.") exit() saver.restore(sess, tf.train.latest_checkpoint(my_setting.ckpt_path)) tic = time.time() n_batch = len(mnist.test.labels) // my_setting.batch_size predict_labels = list() true_labels = list() for step in range(n_batch): X_batch, y_batch = mnist.test.next_batch(my_setting.batch_size, shuffle=False) X_batch = X_batch.reshape([-1, 28, 28, 1]) pred_label, test_loss, test_acc = sess.run([model.pred_lables, model.test_loss, model.test_acc], feed_dict={model.X_inputs: X_batch, model.y_inputs: y_batch}) predict_labels.append(pred_label) true_labels.append(y_batch) predict_labels = np.hstack(predict_labels) true_labels = np.hstack(true_labels) acc = np.sum(predict_labels == true_labels) / len(true_labels) print("Test sample number = {}, acc = {:.4f}, pass {:.2f}s".format(len(true_labels), acc, time.time() - tic)) if __name__ == ‘__main__‘: main()
Batch Normalization原理