
簡述數據庫事務並發機制
轉載自:https://blog.csdn.net/justloveyou_/article/details/70312810
摘要:
事務是最小的邏輯執行單元,也是數據庫並發控制的基本單位,其執行的結果必須使數據庫從一種一致性狀態變到另一種一致性狀態。事務具有四個重要特性,即原子性(Atomicity)、一致性(Consistency)、隔離性 (Isolation)和持久性 (Durability)。本文首先敘述了數據庫中事務的本質及其四大特性(ACID)的內涵,然後重點介紹了事務隔離性的動機和內涵,並介紹了數據庫為此所提供的事務隔離級別以及這些事務隔離級別能解決的事務並發問題。介於並發安全與並發效率的平衡,我們一般不會一味地提高事務隔離級別來保證事務並發安全性,而是通過結合其他機制(包括筆者提到的樂觀鎖和悲觀鎖機制)來解決數據庫事務並發問題。
版權聲明與致謝:
本文原創作者:書呆子Rico
作者博客地址:http://blog.csdn.net/justloveyou_/
本文關於臟讀、不可重復讀和幻讀的解釋舉例來源於博文《數據庫事務隔離級別》。
一. 事務概述
一般而言,用戶的每次請求都對應一個業務邏輯方法,並且每個業務邏輯方法往往具有邏輯上的原子性。此外,一個業務邏輯方法往往包括一系列數據庫原子訪問操作,並且這些數據庫原子訪問操作應該綁定成一個整體,即要麽全部執行,要麽全部不執行,通過這種方式我們可以保證數據庫的完整性。也就是說,事務是最小的邏輯執行單元,是數據庫維護數據一致性的基本單位。
總的來說,事務是一個不可分割操作序列,也是數據庫並發控制的基本單位,其執行的結果必須使數據庫從一種一致性狀態變到另一種一致性狀態。
(1). 原子性(Atomicity)
原子性是指事務包含的所有操作要麽全部成功,要麽全部失敗回滾。 因此,事務的操作如果成功就必須要完全應用到數據庫,如果操作失敗則不會對數據庫有任何影響,也就是說,事務是應用中不可再分的最小邏輯執行體。
(2). 一致性(Consistency)
一致性是指事務執行的結果必須使數據庫從一種一致性狀態變到另一種一致性狀態,也就是說,一個事務執行之前和執行之後數據庫都必須處於一致性狀態。拿轉賬來說,假設用戶A和用戶B兩者的錢加起來一共是5000,那麽不管A和B之間如何轉賬,轉幾次賬,事務結束後兩個用戶的錢相加起來應該還得是5000,這就是事務的一致性。
(3). 隔離性 (Isolation) — 與事務並發直接相關
隔離性是指並發執行的事務之間不能相互影響。也就是說,對於任意兩個並發的事務 T1 和 T2,在事務 T1 看來,T2 要麽在 T1 開始之前就已經結束,要麽在 T1 結束之後才開始,這樣每個事務都感覺不到有其他事務在並發地執行。關於事務的隔離性下文會重點探討。
(4). 持久性 (Durability)
持久性是指一個事務一旦被提交了,那麽對數據庫中的數據的改變就是永久性的,即便是在數據庫系統遇到故障的情況下也不會丟失提交事務的操作。換句換說,事務一旦提交,對數據庫所做的任何改變都要記錄到永久的存儲器中(通常就是保存到物理數據庫)。
二. 事務隔離性的內涵
以上介紹完了事務的基本概念及其四大特性(簡稱ACID),現在重點來說明下事務的隔離性。我們知道,當多個線程都開啟事務操作數據庫中的數據時,數據庫系統要能進行隔離操作以保證各個線程獲取數據的準確性。也就是說,事務的隔離性主要用於解決事務的並發安全問題,那麽事務的隔離性解決了哪些具體問題呢?
1、事務並發帶來的問題
(1). 臟讀
臟讀是指在一個事務處理過程中讀取了另一個事務未提交的數據。比如,當一個事務正在多次修改某個數據,而當這個事務對數據的修改還未提交時,這時一個並發的事務來訪問該數據,就會造成數據的臟讀。看下面的例子:
公司發工資了,領導把5000元打到singo的賬號上,但是該事務並未提交,而singo正好去查看賬戶,發現工資已經到賬,是5000元整,非常高興。可是不幸的是,領導發現發給singo的工資金額不對,是2000元,於是迅速回滾了事務,修改金額後,將事務提交,最後singo實際的工資只有2000元,singo空歡喜一場。
出現的上述情況就是我們所說的臟讀,即對於兩個並發的事務(事務A:領導給singo發工資、事務B:singo查詢工資賬戶),事務B讀取了事務A尚未提交的數據。特別地,當隔離級別設置為 Read Committed 時,就可以避免臟讀,但是仍可能會造成不可重復讀。特別地,大多數數據庫的默認級別就是Read committed,比如Sql Server , Oracle。
(2). 不可重復讀
不可重復讀是指:對於數據庫中的某個數據,一個事務範圍內多次查詢卻返回了不同的數據值,這是由於在查詢間隔該數據被另一個事務修改並提交了。例如,事務 T1 在讀取某一數據,而事務 T2 立馬修改了這個數據並且提交事務,當事務T1再次讀取該數據就得到了不同的結果,即發生了不可重復讀。不可重復讀和臟讀的區別是,臟讀是某一事務讀取了另一個事務未提交的臟數據,而不可重復讀則是讀取了前一事務提交的數據。看下面的例子:
singo拿著工資卡去消費,系統讀取到卡裏確實有2000元,而此時她的老婆也正好在網上轉賬,把singo工資卡的2000元轉到另一賬戶,並在singo之前提交了事務,當singo扣款時,系統檢查到singo的工資卡已經沒有錢,扣款失敗,singo十分納悶,明明卡裏有錢,為何……
上述情況就是我們所說的不可重復讀,即兩個並發的事務(事務A:singo消費、事務B:singo的老婆網上轉賬),事務A事先讀取了數據,事務B緊接著更新了數據並提交了事務,而事務A再次讀取該數據時,數據已經發生了改變。當隔離級別設置為Repeatable read時,可以避免不可重復讀。這時,當singo拿著工資卡去消費時,一旦系統開始讀取工資卡信息(即事務開始),singo的老婆就不可能對該記錄進行修改,也就是singo的老婆不能在此時轉賬。特別地,MySQL的默認隔離級別就是 Repeatable read。
(3). 幻讀
幻讀是事務非獨立執行時發生的一種現象,即在一個事務讀的過程中,另外一個事務可能插入了新數據記錄,影響了該事務讀的結果。例如,事務 T1 對一個表中所有的行的某個數據項執行了從“1”修改為“2”的操作,這時事務T2又對這個表中插入了一行數據項,而這個數據項的數值還是為“1”並且提交給數據庫。這時,操作事務 T1 的用戶如果再查看剛剛修改的數據,會發現還有一行沒有修改,其實這行是從事務T2中添加的,就好像產生幻覺一樣,這就是發生了幻讀。幻讀和不可重復讀都是讀取了另一條已經提交的事務(這點與臟讀不同),所不同的是不可重復讀查詢的都是同一個數據項,而幻讀針對的是數據記錄插入/刪除問題,二者關註的問題點不太相同。看下面的例子:
singo的老婆工作在銀行部門,她時常通過銀行內部系統查看singo的信用卡消費記錄。有一天,她正在查詢到singo當月信用卡的總消費金額為80元,而singo此時正好在外面胡吃海塞後在收銀臺買單,消費1000元,即新增了一條1000元的消費記錄並提交了事務,隨後singo的老婆將singo當月信用卡消費的明細打印到A4紙上,卻發現消費總額為1080元,singo的老婆很詫異,以為出現了幻覺,幻讀就這樣產生了。當隔離級別設置為Serializable(最高的事務隔離級別)時,不僅可以避免臟讀、不可重復讀,還可以避免幻讀。但同時代價也花費最高,性能很低,一般很少使用,因為在該級別下並發事務將串行執行。
2、小結
總的來說,事務的隔離性主要用於解決事務並發安全問題。上面提到的臟讀、不可重復讀和幻讀三個典型問題都是在事務並發的前提下發生的,不同的是三者的問題關註點略有不同。臟讀關註的是事務讀取了另一個事務未提交的數據;不可重復讀關註的是同一事務中對同一個數據項多次讀取的結果互不相同;幻讀更側重於數據記錄的插入/刪除問題,比如同一事務中對符合同一條件的數據記錄的多次查詢的結果互不相同。更進一步地說,不可重復讀關註的是數據的更新帶來的問題,幻讀關註的是數據的增刪帶來的問題。
三. 數據庫的事務隔離級別
不同數據庫的事務隔離級別不盡相同。比如我們在上一節提到,MySQL數據庫支持下面的四種隔離級別,並且默認為 Repeatable read 級別;而在Oracle數據庫中,只支持Serializable 級別和 Read committed 這兩種級別,並且默認為 Read committed 級別。MySQL數據庫為我們提供了四種隔離級別,分別為:
- Serializable (串行化):最高級別,可避免臟讀、不可重復讀、幻讀的發生;
- Repeatable read (可重復讀):可避免臟讀、不可重復讀的發生;
- Read committed (讀已提交):可避免臟讀的發生;
-
Read uncommitted (讀未提交):最低級別,任何情況都無法保證。
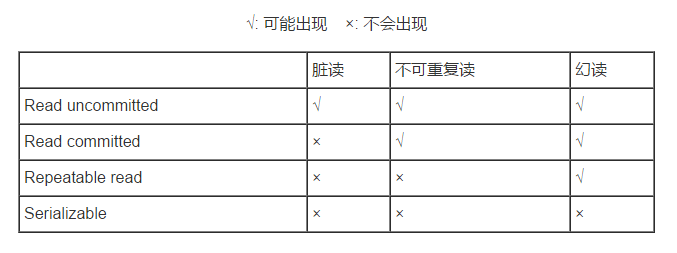
從上圖中可以看出,以上四種隔離級別中最高的是 Serializable級別,最低的是 Read uncommitted級別。當然,隔離級別越高,事務並發就越安全,但執行效率也就越低。比如,Serializable 這樣的級別就是以鎖表的方式(類似於Java多線程中的鎖)保證並發事務的串行執行,但這時執行效率也降到了最低,所以,選用何種隔離級別實質上是一種並發安全與並發效率的平衡,應該根據實際情況而定。特別地,在MySQL數據庫中,默認的事務隔離級別為 Repeatable read(可重復讀),下面我們看看如何在MySQL數據庫中操作事務的隔離級別。
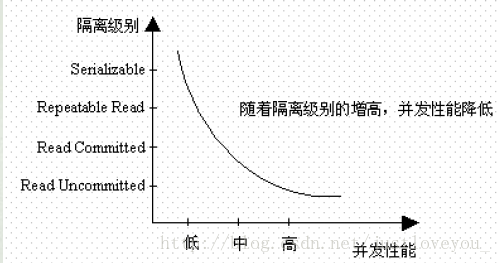
1). MySQL默認事務隔離級別查看
在MySQL數據庫中,我們可以通過以下方式查看當前事務的隔離級別:
select @@tx_isolation;- 1
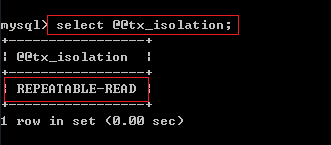
2). MySQL事務隔離級別修改
在MySQL數據庫中,我們可以分別通過以下兩種方式設置事務的隔離級別,分別為:
set [glogal | session] transaction isolation level 隔離級別名稱;
或
set tx_isolation=‘隔離級別名稱‘;- 1
- 2
- 3
3). 使用JDBC對設置數據庫事務的隔離級別
設置數據庫的隔離級別一定要是在開啟事務之前。特別地,使用JDBC對數據庫的事務設置隔離級別時,我們應該在調用Connection對象的setAutoCommit(false)方法之前調用Connection對象的setTransactionIsolation(level)去設置當前鏈接的隔離級別如下所示:

至於參數level,可以使用Connection接口的字段,如以下代碼所示:

特別地,通過這種方式設置事務隔離級別只對當前鏈接有效。對於使用MySQL命令窗口而言,一個窗口就相當於一個鏈接,當前窗口設置的隔離級別只對當前窗口中的事務有效;對於JDBC操作數據庫來說,一個Connection對象相當於一個鏈接,而對於Connection對象設置的隔離級別只對該Connection對象有效,與其他鏈接Connection對象無關。
四. 數據庫並發控制
也許大家已經聽說過,鎖分兩種,一個叫 悲觀鎖,一種稱之為 樂觀鎖。事實上,無論是悲觀鎖還是樂觀鎖,都是人們定義出來的概念,是一種解決問題的思想。因此,不僅僅在數據庫系統中有樂觀鎖和悲觀鎖的概念,像memcache、hibernate、tair等都有類似的概念。比如,在線程並發處理中, Synchronized內置鎖 就是悲觀鎖的一種,也稱之為 獨占鎖,加了synchronized關鍵字的代碼基本上就只能以單線程的形式去執行了,它會導致其他需要該資源的線程掛起,直到前面的線程執行完畢釋放所資源;而 樂觀鎖是一種更高效的機制,它的原理就是每次不加鎖去執行某項操作,如果發生沖突則失敗並重試,直到成功為止,其實本質上不算鎖,所以很多地方也稱之為 自旋。
在解決數據庫的事務並發訪問問題時,雖然將事務串形化可以保證數據在多事務並發處理下不存在數據不一致的問題,但串行執行使得數據庫的處理性能大幅度地下降,常常是我們接受不了的。所以,一般來說,我們常常結合事務隔離級別和其它並發機制來保證事務的並發,以此來兼顧事務並發的效率與安全性。事實上,大多數數據庫的隔離級別都會設置為 Read Committed(只能讀取其他事務已提交的數據),然後由應用程序使用樂觀鎖/悲觀鎖機制來解決其他事務並發問題,比如不可重復讀問題。特別地,樂觀並發控制(樂觀鎖)和悲觀並發控制(悲觀鎖)是並發控制主要采用的技術手段。
特別地,樂觀鎖的理念是:假設不會發生並發沖突,只在提交操作時檢查是否違反數據完整性;而悲觀鎖的理念是假定會發生並發沖突,屏蔽一切可能違反數據完整性的操作。針對於不同的業務場景,應該選用不同的並發控制方式。所以,不要把樂觀並發控制和悲觀並發控制狹義的理解為DBMS中的概念,更不要把他們和數據中提供的鎖機制(行鎖、表鎖、排他鎖、共享鎖)混為一談。需要指出的是,在DBMS中,悲觀鎖正是利用數據庫本身提供的鎖機制來實現的。
Ps:更多關於 synchronized 關鍵字 的介紹, 請移步我的博文《Java 並發:內置鎖 Synchronized》。
1、樂觀鎖
樂觀鎖,雖然名字中帶“鎖”,但是樂觀鎖並不鎖住任何東西,而是在提交事務時檢查這條記錄是否被其他事務進行了修改:如果沒有,則提交;否則,進行回滾。相對於悲觀鎖,在對數據庫進行處理的時候,樂觀鎖並不會使用數據庫提供的鎖機制。如果並發的可能性並不大,那麽樂觀鎖定策略帶來的性能消耗是非常小的。樂觀鎖采用的實現方式一般是記錄數據版本。
數據版本是為數據增加的一個版本標識。當讀取數據時,將版本標識的值一同讀出,數據每更新一次同時對版本標識進行更新。當我們提交更新的時候,判斷數據庫表對應記錄的當前版本信息與第一次取出來的版本標識進行比對,如果數據庫表當前版本號與第一次取出來的版本標識值相等,則予以更新,否則認為是過期數據。一般地,實現數據版本有兩種方式,一種是使用版本號,另一種是使用時間戳。
2、悲觀鎖
悲觀鎖,正如其名,它指的是對數據被外界修改持保守(悲觀)態度,因此,在整個數據處理過程中,將數據處於鎖定狀態。悲觀鎖的實現往往依靠數據庫提供的鎖機制,也只有數據庫層提供的鎖機制才能真正保證數據訪問的排他性,否則即使在本系統中實現了加鎖機制,也無法保證外部系統不會修改數據。悲觀並發控制主要用於數據爭用激烈的環境,以及發生並發沖突時使用鎖保護數據的成本要低於回滾事務的成本的環境中。和樂觀鎖相比,悲觀鎖則是一把真正的鎖了,它通過SQL語句“select for update”鎖住select出的那批數據,這時如果其他事務來更新這批數據時會等待。
悲觀並發控制實際上是“先取鎖再訪問”的保守策略,為數據處理的安全提供了保證。但是在效率方面,處理加鎖的機制會讓數據庫產生額外的開銷,還有增加產生死鎖的機會;另外,在只讀型事務處理中由於不會產生沖突,也沒必要使用鎖,這樣做只能增加系統負載;還有會降低了並行性,一個事務如果鎖定了某行數據,其他事務就必須等待該事務處理完才可以處理那行數據。
3、小結
悲觀鎖和樂觀鎖都是一種解決並發控制問題的思想。特別地,在數據庫並發控制方面,悲觀鎖與樂觀鎖有以下幾點區別:
-
思想:在事務並發環境中,樂觀鎖假設不會發生並發沖突,因此只在提交操作時檢查是否違反數據完整性;而悲觀鎖假定會發生並發沖突,會屏蔽一切可能違反數據完整性的操作。
-
實現:悲觀鎖是利用數據庫本身提供的鎖機制來實現的;而樂觀鎖則是通過記錄數據版本實現的;
-
應用場景:悲觀鎖主要用於數據爭用激烈的環境或者發生並發沖突時使用鎖保護數據的成本要低於回滾事務的成本的環境中;而樂觀鎖主要應用於並發可能性並不太大、數據競爭不激烈的環境中,這時樂觀鎖帶來的性能消耗是非常小的;
-
臟讀: 樂觀鎖不能解決臟讀問題,而悲觀鎖則可以。
總的來說,悲觀鎖相對樂觀鎖更安全一些,但是開銷也更大,甚至可能出現數據庫死鎖的情況,建議只在樂觀鎖無法工作時才使用。
五. 更多
更多關於 synchronized 關鍵字 的介紹, 請移步我的博文《Java 並發:內置鎖 Synchronized》。
更多關於 Java 並發編程 方面的內容,請關註我的專欄 《Java 並發編程學習筆記》。本專欄全面記錄了Java並發編程的相關知識,並結合操作系統、Java內存模型和相關源碼對並發編程的原理、技術、設計、底層實現進行深入分析和總結,並持續跟進並發相關技術。
引用
數據庫事務的四大特性以及事務的隔離級別
數據庫事務隔離級別
深入理解樂觀鎖與悲觀鎖
簡述數據庫事務並發機制