
深入理解Java對象的創建過程:類的初始化與實例化
轉載自:https://blog.csdn.net/justloveyou_/article/details/72466416
摘要:
在Java中,一個對象在可以被使用之前必須要被正確地初始化,這一點是Java規範規定的。在實例化一個對象時,JVM首先會檢查相關類型是否已經加載並初始化,如果沒有,則JVM立即進行加載並調用類構造器完成類的初始化。在類初始化過程中或初始化完畢後,根據具體情況才會去對類進行實例化。本文試圖對JVM執行類初始化和實例化的過程做一個詳細深入地介紹,以便從Java虛擬機的角度清晰解剖一個Java對象的創建過程。
版權聲明:
本文原創作者:書呆子Rico
作者博客地址:http://blog.csdn.net/justloveyou_/
友情提示:
一個Java對象的創建過程往往包括 類初始化 和 類實例化 兩個階段。本文的姊妹篇《 JVM類加載機制概述:加載時機與加載過程》主要介紹了類的初始化時機和初始化過程,本文在此基礎上,進一步闡述了一個Java對象創建的真實過程。
一、Java對象創建時機
我們知道,一個對象在可以被使用之前必須要被正確地實例化。在Java代碼中,有很多行為可以引起對象的創建,最為直觀的一種就是使用new關鍵字來調用一個類的構造函數顯式地創建對象,這種方式在Java規範中被稱為 : 由執行類實例創建表達式而引起的對象創建。除此之外,我們還可以使用反射機制(Class類的newInstance方法、使用Constructor類的newInstance方法)、使用Clone方法、使用反序列化等方式創建對象。下面筆者分別對此進行一一介紹:
1). 使用new關鍵字創建對象
這是我們最常見的也是最簡單的創建對象的方式,通過這種方式我們可以調用任意的構造函數(無參的和有參的)去創建對象。比如:
Student student = new Student();2). 使用Class類的newInstance方法(反射機制)
我們也可以通過Java的反射機制使用Class類的newInstance方法來創建對象,事實上,這個newInstance方法調用無參的構造器創建對象,比如:
Student student2 = (Student)Class.forName("Student類全限定名").newInstance();
或者:
Student stu = Student.class.newInstance();
3). 使用Constructor類的newInstance方法(反射機制)
java.lang.relect.Constructor類裏也有一個newInstance方法可以創建對象,該方法和Class類中的newInstance方法很像,但是相比之下,Constructor類的newInstance方法更加強大些,我們可以通過這個newInstance方法調用有參數的和私有的構造函數,比如:
public class Student {
private int id;
public Student(Integer id) {
this.id = id;
}
public static void main(String[] args) throws Exception {
Constructor<Student> constructor = Student.class
.getConstructor(Integer.class);
Student stu3 = constructor.newInstance(123);
}
}使用newInstance方法的這兩種方式創建對象使用的就是Java的反射機制,事實上Class的newInstance方法內部調用的也是Constructor的newInstance方法。
4). 使用Clone方法創建對象
無論何時我們調用一個對象的clone方法,JVM都會幫我們創建一個新的、一樣的對象,特別需要說明的是,用clone方法創建對象的過程中並不會調用任何構造函數。關於如何使用clone方法以及淺克隆/深克隆機制,筆者已經在博文《 Java String 綜述(下篇)》做了詳細的說明。簡單而言,要想使用clone方法,我們就必須先實現Cloneable接口並實現其定義的clone方法,這也是原型模式的應用。比如:
public class Student implements Cloneable{
private int id;
public Student(Integer id) {
this.id = id;
}
@Override
protected Object clone() throws CloneNotSupportedException {
// TODO Auto-generated method stub
return super.clone();
}
public static void main(String[] args) throws Exception {
Constructor<Student> constructor = Student.class
.getConstructor(Integer.class);
Student stu3 = constructor.newInstance(123);
Student stu4 = (Student) stu3.clone();
}
}5). 使用(反)序列化機制創建對象
當我們反序列化一個對象時,JVM會給我們創建一個單獨的對象,在此過程中,JVM並不會調用任何構造函數。為了反序列化一個對象,我們需要讓我們的類實現Serializable接口,比如:
public class Student implements Cloneable, Serializable {
private int id;
public Student(Integer id) {
this.id = id;
}
@Override
public String toString() {
return "Student [id=" + id + "]";
}
public static void main(String[] args) throws Exception {
Constructor<Student> constructor = Student.class
.getConstructor(Integer.class);
Student stu3 = constructor.newInstance(123);
// 寫對象
ObjectOutputStream output = new ObjectOutputStream(
new FileOutputStream("student.bin"));
output.writeObject(stu3);
output.close();
// 讀對象
ObjectInputStream input = new ObjectInputStream(new FileInputStream(
"student.bin"));
Student stu5 = (Student) input.readObject();
System.out.println(stu5);
}
}6). 完整實例
public class Student implements Cloneable, Serializable {
private int id;
public Student() {
}
public Student(Integer id) {
this.id = id;
}
@Override
protected Object clone() throws CloneNotSupportedException {
// TODO Auto-generated method stub
return super.clone();
}
@Override
public String toString() {
return "Student [id=" + id + "]";
}
public static void main(String[] args) throws Exception {
System.out.println("使用new關鍵字創建對象:");
Student stu1 = new Student(123);
System.out.println(stu1);
System.out.println("\n---------------------------\n");
System.out.println("使用Class類的newInstance方法創建對象:");
Student stu2 = Student.class.newInstance(); //對應類必須具有無參構造方法,且只有這一種創建方式
System.out.println(stu2);
System.out.println("\n---------------------------\n");
System.out.println("使用Constructor類的newInstance方法創建對象:");
Constructor<Student> constructor = Student.class
.getConstructor(Integer.class); // 調用有參構造方法
Student stu3 = constructor.newInstance(123);
System.out.println(stu3);
System.out.println("\n---------------------------\n");
System.out.println("使用Clone方法創建對象:");
Student stu4 = (Student) stu3.clone();
System.out.println(stu4);
System.out.println("\n---------------------------\n");
System.out.println("使用(反)序列化機制創建對象:");
// 寫對象
ObjectOutputStream output = new ObjectOutputStream(
new FileOutputStream("student.bin"));
output.writeObject(stu4);
output.close();
// 讀取對象
ObjectInputStream input = new ObjectInputStream(new FileInputStream(
"student.bin"));
Student stu5 = (Student) input.readObject();
System.out.println(stu5);
}
}/* Output:
使用new關鍵字創建對象:
Student [id=123]
---------------------------
使用Class類的newInstance方法創建對象:
Student [id=0]
---------------------------
使用Constructor類的newInstance方法創建對象:
Student [id=123]
---------------------------
使用Clone方法創建對象:
Student [id=123]
---------------------------
使用(反)序列化機制創建對象:
Student [id=123]
*///:~從Java虛擬機層面看,除了使用new關鍵字創建對象的方式外,其他方式全部都是通過轉變為invokevirtual指令直接創建對象的。
二. Java 對象的創建過程
當一個對象被創建時,虛擬機就會為其分配內存來存放對象自己的實例變量及其從父類繼承過來的實例變量(即使這些從超類繼承過來的實例變量有可能被隱藏也會被分配空間)。在為這些實例變量分配內存的同時,這些實例變量也會被賦予默認值(零值)。在內存分配完成之後,Java虛擬機就會開始對新創建的對象按照程序猿的意誌進行初始化。在Java對象初始化過程中,主要涉及三種執行對象初始化的結構,分別是 實例變量初始化、實例代碼塊初始化 以及 構造函數初始化。
1、實例變量初始化與實例代碼塊初始化
我們在定義(聲明)實例變量的同時,還可以直接對實例變量進行賦值或者使用實例代碼塊對其進行賦值。如果我們以這兩種方式為實例變量進行初始化,那麽它們將在構造函數執行之前完成這些初始化操作。實際上,如果我們對實例變量直接賦值或者使用實例代碼塊賦值,那麽編譯器會將其中的代碼放到類的構造函數中去,並且這些代碼會被放在對超類構造函數的調用語句之後(還記得嗎?Java要求構造函數的第一條語句必須是超類構造函數的調用語句),構造函數本身的代碼之前。例如:
public class InstanceVariableInitializer {
private int i = 1;
private int j = i + 1;
public InstanceVariableInitializer(int var){
System.out.println(i);
System.out.println(j);
this.i = var;
System.out.println(i);
System.out.println(j);
}
{ // 實例代碼塊
j += 3;
}
public static void main(String[] args) {
new InstanceVariableInitializer(8);
}
}/* Output:
1
5
8
5
*///:~上面的例子正好印證了上面的結論。特別需要註意的是,Java是按照編程順序來執行實例變量初始化器和實例初始化器中的代碼的,並且不允許順序靠前的實例代碼塊初始化在其後面定義的實例變量,比如:
public class InstanceInitializer {
{
j = i;
}
private int i = 1;
private int j;
}
public class InstanceInitializer {
private int j = i;
private int i = 1;
} 上面的這些代碼都是無法通過編譯的,編譯器會抱怨說我們使用了一個未經定義的變量。之所以要這麽做是為了保證一個變量在被使用之前已經被正確地初始化。但是我們仍然有辦法繞過這種檢查,比如:
public class InstanceInitializer {
private int j = getI();
private int i = 1;
public InstanceInitializer() {
i = 2;
}
private int getI() {
return i;
}
public static void main(String[] args) {
InstanceInitializer ii = new InstanceInitializer();
System.out.println(ii.j);
}
} 如果我們執行上面這段代碼,那麽會發現打印的結果是0。因此我們可以確信,變量j被賦予了i的默認值0,這一動作發生在實例變量i初始化之前和構造函數調用之前。
2、構造函數初始化
我們可以從上文知道,實例變量初始化與實例代碼塊初始化總是發生在構造函數初始化之前,那麽我們下面著重看看構造函數初始化過程。眾所周知,每一個Java中的對象都至少會有一個構造函數,如果我們沒有顯式定義構造函數,那麽它將會有一個默認無參的構造函數。在編譯生成的字節碼中,這些構造函數會被命名成<init>()方法,參數列表與Java語言書寫的構造函數的參數列表相同。
我們知道,Java要求在實例化類之前,必須先實例化其超類,以保證所創建實例的完整性。事實上,這一點是在構造函數中保證的:Java強制要求Object對象(Object是Java的頂層對象,沒有超類)之外的所有對象構造函數的第一條語句必須是超類構造函數的調用語句或者是類中定義的其他的構造函數,如果我們既沒有調用其他的構造函數,也沒有顯式調用超類的構造函數,那麽編譯器會為我們自動生成一個對超類構造函數的調用,比如:
public class ConstructorExample {
} 對於上面代碼中定義的類,我們觀察編譯之後的字節碼,我們會發現編譯器為我們生成一個構造函數,如下,
aload_0
invokespecial #8; //Method java/lang/Object."<init>":()V
return 上面代碼的第二行就是調用Object類的默認構造函數的指令。也就是說,如果我們顯式調用超類的構造函數,那麽該調用必須放在構造函數所有代碼的最前面,也就是必須是構造函數的第一條指令。正因為如此,Java才可以使得一個對象在初始化之前其所有的超類都被初始化完成,並保證創建一個完整的對象出來。
特別地,如果我們在一個構造函數中調用另外一個構造函數,如下所示,
public class ConstructorExample {
private int i;
ConstructorExample() {
this(1);
....
}
ConstructorExample(int i) {
....
this.i = i;
....
}
} 對於這種情況,Java只允許在ConstructorExample(int i)內調用超類的構造函數,也就是說,下面兩種情形的代碼編譯是無法通過的:
public class ConstructorExample {
private int i;
ConstructorExample() {
super();
this(1); // Error:Constructor call must be the first statement in a constructor
....
}
ConstructorExample(int i) {
....
this.i = i;
....
}
} 或者,
public class ConstructorExample {
private int i;
ConstructorExample() {
this(1);
super(); //Error: Constructor call must be the first statement in a constructor
....
}
ConstructorExample(int i) {
this.i = i;
}
} Java通過對構造函數作出這種限制以便保證一個類的實例能夠在被使用之前正確地初始化。
3、 小結
總而言之,實例化一個類的對象的過程是一個典型的遞歸過程,如下圖所示。進一步地說,在實例化一個類的對象時,具體過程是這樣的:
在準備實例化一個類的對象前,首先準備實例化該類的父類,如果該類的父類還有父類,那麽準備實例化該類的父類的父類,依次遞歸直到遞歸到Object類。此時,首先實例化Object類,再依次對以下各類進行實例化,直到完成對目標類的實例化。具體而言,在實例化每個類時,都遵循如下順序:先依次執行實例變量初始化和實例代碼塊初始化,再執行構造函數初始化。也就是說,編譯器會將實例變量初始化和實例代碼塊初始化相關代碼放到類的構造函數中去,並且這些代碼會被放在對超類構造函數的調用語句之後,構造函數本身的代碼之前。
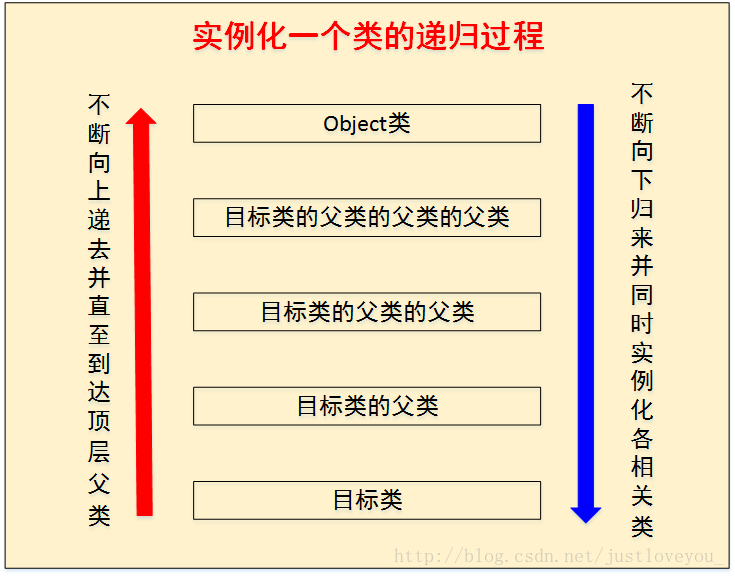
Ps: 關於遞歸的思想與內涵的介紹,請參見我的博文《 算法設計方法:遞歸的內涵與經典應用》。
4、實例變量初始化、實例代碼塊初始化以及構造函數初始化綜合實例
筆者在《 JVM類加載機制概述:加載時機與加載過程》一文中詳細闡述了類初始化時機和初始化過程,並在文章的最後留了一個懸念給各位,這裏來揭開這個懸念。建議讀者先看完《 JVM類加載機制概述:加載時機與加載過程》這篇再來看這個,印象會比較深刻,如若不然,也沒什麽關系~~
//父類
class Foo {
int i = 1;
Foo() {
System.out.println(i); -----------(1)
int x = getValue();
System.out.println(x); -----------(2)
}
{
i = 2;
}
protected int getValue() {
return i;
}
}
//子類
class Bar extends Foo {
int j = 1;
Bar() {
j = 2;
}
{
j = 3;
}
@Override
protected int getValue() {
return j;
}
}
public class ConstructorExample {
public static void main(String... args) {
Bar bar = new Bar();
System.out.println(bar.getValue()); -----------(3)
}
}/* Output:
2
0
2
*///:~根據上文所述的類實例化過程,我們可以將Foo類的構造函數和Bar類的構造函數等價地分別變為如下形式:
//Foo類構造函數的等價變換:
Foo() {
i = 1;
i = 2;
System.out.println(i);
int x = getValue();
System.out.println(x);
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
//Bar類構造函數的等價變換
Bar() {
Foo();
j = 1;
j = 3;
j = 2
}這樣程序就好看多了,我們一眼就可以觀察出程序的輸出結果。在通過使用Bar類的構造方法new一個Bar類的實例時,首先會調用Foo類構造函數,因此(1)處輸出是2,這從Foo類構造函數的等價變換中可以直接看出。(2)處輸出是0,為什麽呢?因為在執行Foo的構造函數的過程中,由於Bar重載了Foo中的getValue方法,所以根據Java的多態特性可以知道,其調用的getValue方法是被Bar重載的那個getValue方法。但由於這時Bar的構造函數還沒有被執行,因此此時j的值還是默認值0,因此(2)處輸出是0。最後,在執行(3)處的代碼時,由於bar對象已經創建完成,所以此時再訪問j的值時,就得到了其初始化後的值2,這一點可以從Bar類構造函數的等價變換中直接看出。
三. 類的初始化時機與過程
關於類的初始化時機,筆者在博文《 JVM類加載機制概述:加載時機與加載過程》已經介紹的很清楚了,此處不再贅述。簡單地說,在類加載過程中,準備階段是正式為類變量(static 成員變量)分配內存並設置類變量初始值(零值)的階段,而初始化階段是真正開始執行類中定義的java程序代碼(字節碼)並按程序猿的意圖去初始化類變量的過程。更直接地說,初始化階段就是執行類構造器<clinit>()方法的過程。<clinit>()方法是由編譯器自動收集類中的所有類變量的賦值動作和靜態代碼塊static{}中的語句合並產生的,其中編譯器收集的順序是由語句在源文件中出現的順序所決定。
類構造器<clinit>()與實例構造器<init>()不同,它不需要程序員進行顯式調用,虛擬機會保證在子類類構造器<clinit>()執行之前,父類的類構造<clinit>()執行完畢。由於父類的構造器<clinit>()先執行,也就意味著父類中定義的靜態代碼塊/靜態變量的初始化要優先於子類的靜態代碼塊/靜態變量的初始化執行。特別地,類構造器<clinit>()對於類或者接口來說並不是必需的,如果一個類中沒有靜態代碼塊,也沒有對類變量的賦值操作,那麽編譯器可以不為這個類生產類構造器<clinit>()。此外,在同一個類加載器下,一個類只會被初始化一次,但是一個類可以任意地實例化對象。也就是說,在一個類的生命周期中,類構造器<clinit>()最多會被虛擬機調用一次,而實例構造器<init>()則會被虛擬機調用多次,只要程序員還在創建對象。
註意,這裏所謂的實例構造器<init>()是指收集類中的所有實例變量的賦值動作、實例代碼塊和構造函數合並產生的,類似於上文對Foo類的構造函數和Bar類的構造函數做的等價變換。
四. 總結
1、一個實例變量在對象初始化的過程中會被賦值幾次?
我們知道,JVM在為一個對象分配完內存之後,會給每一個實例變量賦予默認值,這個時候實例變量被第一次賦值,這個賦值過程是沒有辦法避免的。如果我們在聲明實例變量x的同時對其進行了賦值操作,那麽這個時候,這個實例變量就被第二次賦值了。如果我們在實例代碼塊中,又對變量x做了初始化操作,那麽這個時候,這個實例變量就被第三次賦值了。如果我們在構造函數中,也對變量x做了初始化操作,那麽這個時候,變量x就被第四次賦值。也就是說,在Java的對象初始化過程中,一個實例變量最多可以被初始化4次。
2、類的初始化過程與類的實例化過程的異同?
類的初始化是指類加載過程中的初始化階段對類變量按照程序猿的意圖進行賦值的過程;而類的實例化是指在類完全加載到內存中後創建對象的過程。
3、假如一個類還未加載到內存中,那麽在創建一個該類的實例時,具體過程是怎樣的?
我們知道,要想創建一個類的實例,必須先將該類加載到內存並進行初始化,也就是說,類初始化操作是在類實例化操作之前進行的,但並不意味著:只有類初始化操作結束後才能進行類實例化操作。例如,筆者在博文《 JVM類加載機制概述:加載時機與加載過程》中所提到的下面這個經典案例:
public class StaticTest {
public static void main(String[] args) {
staticFunction();
}
static StaticTest st = new StaticTest();
static { //靜態代碼塊
System.out.println("1");
}
{ // 實例代碼塊
System.out.println("2");
}
StaticTest() { // 實例構造器
System.out.println("3");
System.out.println("a=" + a + ",b=" + b);
}
public static void staticFunction() { // 靜態方法
System.out.println("4");
}
int a = 110; // 實例變量
static int b = 112; // 靜態變量
}/* Output:
2
3
a=110,b=0
1
4
*///:~ 大家能得到正確答案嗎?筆者已經在博文《 JVM類加載機制概述:加載時機與加載過程》中解釋過這個問題了,此不贅述。
總的來說,類實例化的一般過程是:父類的類構造器<clinit>() -> 子類的類構造器<clinit>() -> 父類的成員變量和實例代碼塊 -> 父類的構造函數 -> 子類的成員變量和實例代碼塊 -> 子類的構造函數。
五. 更多
更多關於類初始化時機和初始化過程的介紹,請參見我的博文《 JVM類加載機制概述:加載時機與加載過程》。
更多關於類加載器等方面的內容,包括JVM預定義的類加載器、雙親委派模型等知識點,請參見我的轉載博文《深入理解Java類加載器(一):Java類加載原理解析》。
關於遞歸的思想與內涵的介紹,請參見我的博文《 算法設計方法:遞歸的內涵與經典應用》。
引用:
Java對象初始化詳解
Java中創建對象的幾種方式
深入理解Java對象的創建過程:類的初始化與實例化