
centOS7下Spark安裝配置
阿新 • • 發佈:2018-07-13
節點 bin scala www. emp 讓其 slave park exec
slave1: starting org.apache.spark.deploy.worker.Worker, logging to /usr/spark/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-slave1.com.cn.out
master: starting org.apache.spark.deploy.worker.Worker, logging to /usr/spark/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-master.out
環境說明:
操作系統: centos7 64位 3臺
centos7-1 192.168.190.130 master
centos7-2 192.168.190.129 slave1
centos7-3 192.168.190.131 slave2
安裝spark需要同時安裝如下內容:
jdk scale
1.安裝jdk,配置jdk環境變量
這裏不講如何安裝配置jdk,自行百度。
2.安裝scala
下載scala安裝包,https://www.scala-lang.org/download/選擇符合要求的版本進行下載,使用客戶端工具上傳到服務器上。解壓:
#tar -zxvf scala-2.13.0-M4.tgz
再次修改/etc/profile文件,添加如下內容:
export SCALA_HOME=$WORK_SPACE/scala-2.13.0-M4
export PATH=$PATH:$SCALA_HOME/bin
#source /etc/profile // 讓其立即生效
#scala -version //查看scala是否安裝完成
3.安裝spark
spark下載地址:http://spark.apache.org/downloads.html
說明:有不同的版本包下載,選則你需要的下載安裝即可
Source code: Spark 源碼,需要編譯才能使用,另外 Scala 2.11 需要使用源碼編譯才可使用
Pre-build with user-provided Hadoop: “Hadoop free” 版,可應用到任意 Hadoop 版本
Pre-build for Hadoop 2.7 and later: 基於 Hadoop 2.7 的預先編譯版,需要與本機安裝的 Hadoop 版本對應。可選的還有 Hadoop 2.6。我這裏因為裝的hadoop是3.1.0,所以直接安裝for hadoop 2.7 and later的版本。
註:hadoop的安裝請查看我的上一篇博客,不在重復描述。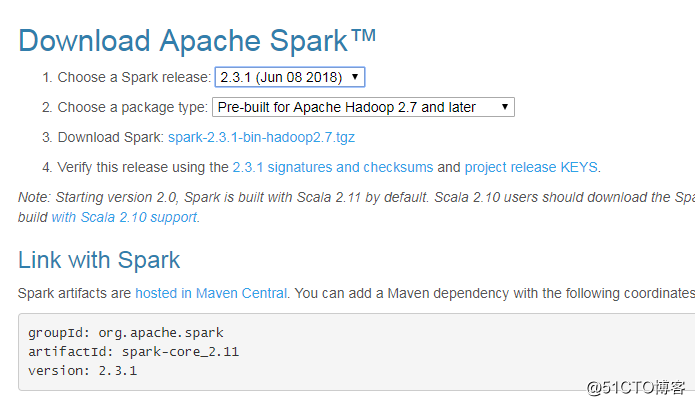
#mkdir spark #cd /usr/spark #tar -zxvf spark-2.3.1-bin-hadoop2.7.tgz #vim /etc/profile #添加spark的環境變量,加如PATH下、export出來 #source /etc/profile #進入conf目錄下,把spark-env.sh.template拷貝一份改名spark-env.sh #cd /usr/spark/spark-2.3.1-bin-hadoop2.7/conf #cp spark-env.sh.template spark-env.sh #vim spark-env.sh export SCALA_HOME=/usr/scala/scala-2.13.0-M4 export JAVA_HOME=/usr/lib/jvm/jre-1.8.0-openjdk-1.8.0.171-8.b10.el7_5.x86_64 export HADOOP_HOME=/usr/hadoop/hadoop-3.1.0 export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop export SPARK_HOME=/usr/spark/spark-2.3.1-bin-hadoop2.7 export SPARK_MASTER_IP=master export SPARK_EXECUTOR_MEMORY=1G #進入conf目錄下,把slaves.template拷貝一份改名為slaves #cd /usr/spark/spark-2.3.1-bin-hadoop2.7/conf #cp slaves.template slaves #vim slaves #添加節點域名到slaves文件中 #master //該域名為centos7-1的域名 #slave1 //該域名為centos7-2的域名 #slave2 //該域名為centos7-3的域名
啟動spark
#啟動spark之前先要把hadoop節點啟動起來
#cd /usr/hadoop/hadoop-3.1.0/
#sbin/start-all.sh
#jps //檢查啟動的線程是否已經把hadoop啟動起來了
#cd /usr/spark/spark-2.3.1-bin-hadoop2.7
#sbin/start-all.sh
備註:在slave1\slave2節點上也必須按照上面的方式安裝spark,或者直接拷貝一份到slave1,slave2節點上
#scp -r /usr/spark root@slave1ip:/usr/spark
啟動信息如下:starting org.apache.spark.deploy.master.Master, logging to /usr/spark/logs/spark-root-org.apache.spark.deploy.master.Master-1-master.out
slave1: starting org.apache.spark.deploy.worker.Worker, logging to /usr/spark/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-slave1.com.cn.out
master: starting org.apache.spark.deploy.worker.Worker, logging to /usr/spark/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-master.out
測試Spark集群:
用瀏覽器打開master節點上的spark集群url:http://192.168.190.130:8080/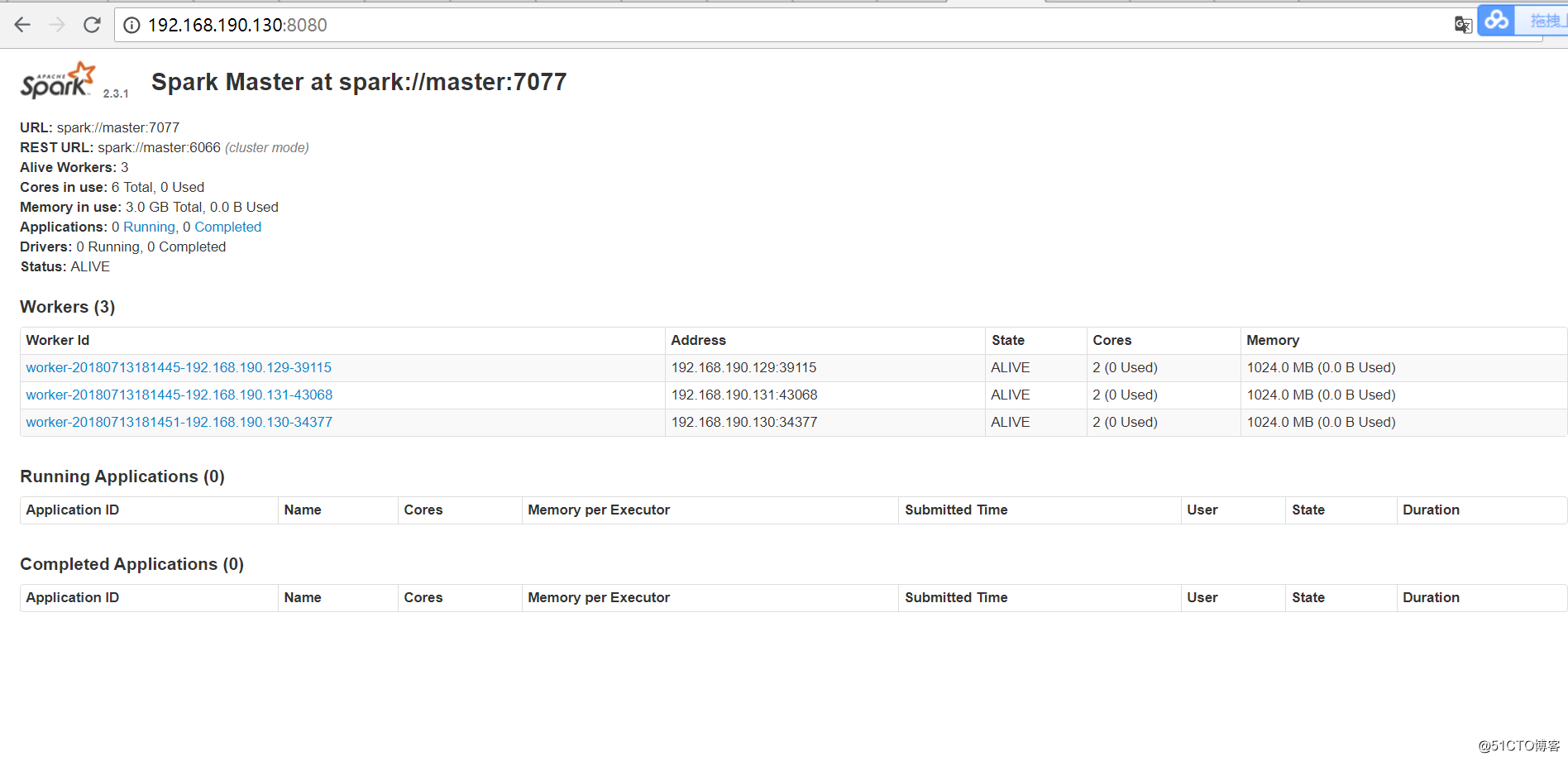
centOS7下Spark安裝配置