
equals、HashCode與實體類的設計
equals和HashCode都是用來去重的,即判斷兩個對象是否相等。如果是String類則我們直接用.equals()判斷,如果是我們自己定義的類,需要有自己的判斷方法,重寫equals,如果是集合(HashSet、HashMap)判斷加入的元素是否為重復,並且加入的元素是我們自己定義的類,這時用重寫equals和HashCode兩個一起判斷:插入的元素是否相等(HashSet中),插入的key是否相同(HashMap中)。
設計一個標準的實體類四大原則:
1、封裝:屬性私有化,提供get/set方法等;
2、提供無參構造;
3、重寫toString()、HashCode()、equals()這三個方法,(繼承自根Object,不必須都重寫按自己的需求定);
4、實現序列化接口(implements Serializable),這樣類的對象可以經過二進制數據流進行傳輸。
例如:
- class Person2 implements Serializable{
- private static final long serialVersionUID = 1L;
- private String name;
- private int age;
- public Person2(){}
- public Person2(String name, int age){
- this.name = name;
- this.age = age;
- }
- // 重寫equals,定義同一類型,並且屬性name和age全部相等則實例對象相等
- public boolean equals(Object obj){
- if(this == obj){
- return true;
- }
- if(!(obj instanceof Person2)){
- return false;
- }
- Person2 p = (Person2) obj;
- if(this.name.equals(p.name)&&this.age == p.age){
- return
- }else{
- return false;
- }
- }
- // 重寫HashCode將對象的某些信息映射成一個數值---散列值
- public int hashCode(){
- return this.name.hashCode()*this.age;
- }
- // 重寫toString打印自己想要的格式,如果不重寫默認直接繼承Object類的toString 方法是獲取對象在內存中的值可能會亂碼
- public String toString(){
- return "姓名:"+this.name+";年齡:"+this.age;
- }
- }
1、首先說一下,什麽情況下要重寫toString,object類裏的toString只是把字符串的直接打印,數字的要轉化成字符再打印,而對象,則直接打印該對象的hash碼。所以當你要想按照你想要的格式去字符串一些對象的時候,就需要重寫toString了。比如一個Student對象,直接toString肯定是一個hash碼。然而你想得到的比如是:name:***,age:***。這時就重寫toString就是在toString裏寫:System.out.println(“name:”+student.getName);System.out.println(“age:”+student.getAge)。這樣再toString就直接反回你想要的格式。通過查api我們就可以知道HashSet的toString是把s的值格式化成[*, * ,*],就是給s的加個中括號,而且用逗號分開。而HashMap的toString是把m的值格式化成{key1=value1,key2=value2,key3=value3}所以你打印出來的是那樣的格式,這就是重寫toString的作用
equals和HashCode都是用來鑒定兩個對象是否相等的。2、一般來講,equals是給用戶調用的,如果你想判斷兩個實例對象是否相等,可以在自己定義的類中重寫equals方法,然後在代碼中調用這個方法就可以判斷是否相等了。
簡單的說,equals就是從表面和自己定義的規範內容上看兩個對象是否相等。
舉個例子,有個學生類,屬性只有姓名和性別,那麽我們可以認為只要姓名和性別相等,那麽就說這2個對象是相等的。
3、HashCode的方法只有在散列集合中用到,這樣的散列集合包括HashSet、HashMap以及HashTable。
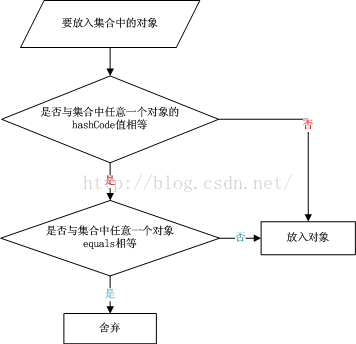
例如在集合存儲中,判斷並不再插入重復的元素,也許大多數人都會想到調用equals方法來逐個進行比較,這個方法確實可行。但是如果集合中已經存在一萬條數據或者更多的數據,如果采用equals方法去逐一比較,效率必然是一個問題。此時hashCode方法的作用就體現出來了。
當集合要添加新的對象時,先調用這個對象的hashCode方法,得到對應的hashcode值,實際上在HashMap的具體實現中會用一個table保存已經存進去的對象的hashcode值,如果table中沒有該hashcode值,它就可以直接存進去,不用再進行任何比較了;如果存在該hashcode值,
就調用它的equals方法(可是被重寫的)與新元素進行比較,相同的話就不存了,不相同就散列其它的地址,所以這裏存在一個沖突解決的問題,這樣一來實際調用equals方法的次數就大大降低了,說通俗一點:Java中的hashCode方法就是根據一定的規則將與對象相關的信息(比如對象的存儲地址,對象的字段等)映射成一個數值,這個數值稱作為散列值
將元素放在集合中的流程:
equals、HashCode與實體類的設計