
大端BigEndian、小端LittleEndian與字符集編碼
BigEndian(大端):低字節在高內存地址
LittleEndian(小端):低字節在低內存地址
也就是看低字節在高內存地址還是低內存地址,也就是看低字節在前還是高字節在前,低字節在前自然是小端,高字節在前就是大端。
所謂大小端,是指字節存儲或傳輸時的順序。
註:最小尋址單位是指特定的計算機硬件機構所支持的最小數據訪問塊大小。以
個人電腦為例,內存機構的最小尋址單位為1個字節(1 Byte)即8個bit。也就
是說,你無法單獨訪問1 bit的信息或者任意小於1字節的信息。個人電腦中的硬
盤部分最小訪問單位為4KB(依廠商不同而有所區別,較早的硬盤該單位比較
小),這就是通常所講的“硬盤按塊尋址”,一塊既指4KB的數據。

例如:
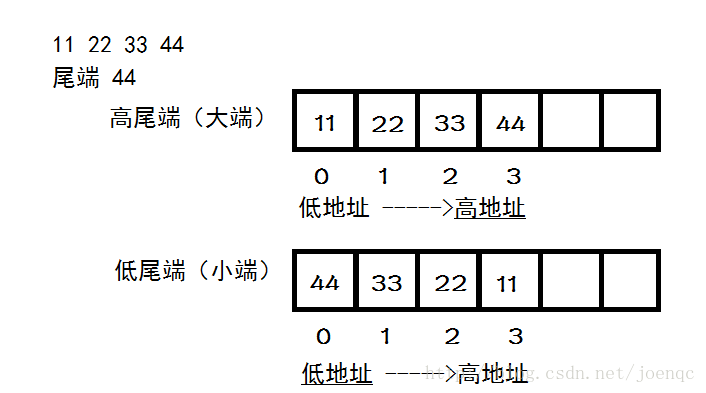
大小端字節序與字符集編碼之間的聯系就是BOM,即 Byte Order Mark,字節順序標記。例如可以以utf16編碼將數據存儲到文件中,在文件頭部,會存入BOM,以表示在讀取數據的時候是按照大端讀取還是小端讀取。FEFF表示大端,FFFE表示小端。而utf-8由於其特殊的變長編碼規則,導致它是可以自解釋的,所以以utf-8編碼存儲、傳輸數據時可以選擇不加入BOM,同時這也是推薦的方式。

因為utf-8代碼單元為1字節,每個字節高位都有標識,每當讀到一個字節時,可以根據其高位進行判斷。如上圖,如果讀到0開頭的字節,則此字節單獨編碼;如果讀到110、1110、11110開頭的字節,則接著讀取對應個數的字節;如果讀到10開頭的字節,則繼續讀取,讀到110、1110、11110開頭的字節為止。
由此看來,無需BOM並且可以無視字節序。只是utf-8解碼程序稍稍麻煩一些。
而utf-16編碼方式的代碼單元為2字節,則一個代碼單元內的兩個字節的先後順序對讀取會產生影響,必須指定字節序,否則只能靠猜。
參考:
http://blog.csdn.net/joenqc/article/details/54891731
http://www.cnblogs.com/skywang12345/p/3360348.html
http://www.360doc.com/content/15/0915/14/26654031_499295872.shtml
在網絡傳輸中,tcp協議采用大端字節序,也就是先接收到的字節為數據的高位。在不同的操作系統平臺中,內存采用的字節序可能不同,x86和一般的OS(如windows,FreeBSD,Linux)使用的是小端模式。但比如Mac OS是大端模式。在不同平臺之間進行網絡傳輸時,需要進行特殊的轉換,詳見
http://www.cnblogs.com/fuchongjundream/p/3914770.html
在java中,通過 ByteOrder.nativeOrder() 方法可以判斷當前平臺采用的時大端字節序還是小端字節序。
public static ByteOrder nativeOrder() {
return Bits.byteOrder();
}
static ByteOrder byteOrder() {
if (byteOrder == null)
throw new Error("Unknown byte order");
return byteOrder;
}
static {
long a = unsafe.allocateMemory(8);
try {
unsafe.putLong(a, 0x0102030405060708L);
byte b = unsafe.getByte(a);
switch (b) {
case 0x01: byteOrder = ByteOrder.BIG_ENDIAN; break;
case 0x08: byteOrder = ByteOrder.LITTLE_ENDIAN; break;
default:
assert false;
byteOrder = null;
}
} finally {
unsafe.freeMemory(a);
}
}
主要實現為static靜態方法,首先為long分配了8個字節內存,然後為long分配了值,之後拿出long的第一個字節,如果為數據的高位,那麽平臺采用的是大端字節序,如果為數據的低位,那麽平臺采用的時小端字節序。
大端BigEndian、小端LittleEndian與字符集編碼