
jmeter 正則獲取多個返回token至本地文件,並跨線程組調用
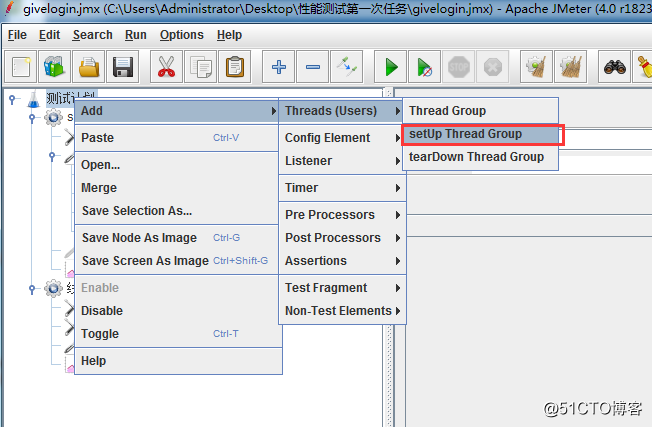
對於setup Thread Group和tearDown Thread Group來說,從字面意思上來看就是安裝線程組和卸載線程組,所以可以理解為對於線程組的初始化和完成時處理,setup Thread Group是所有我們真正開始線程並發之前的準備工作,必須是在線程組開始之前完成的並且擁有自己獨立的線程設置。
2、添加HTTP信息投管理工具
將接口需要的頭信息放在這裏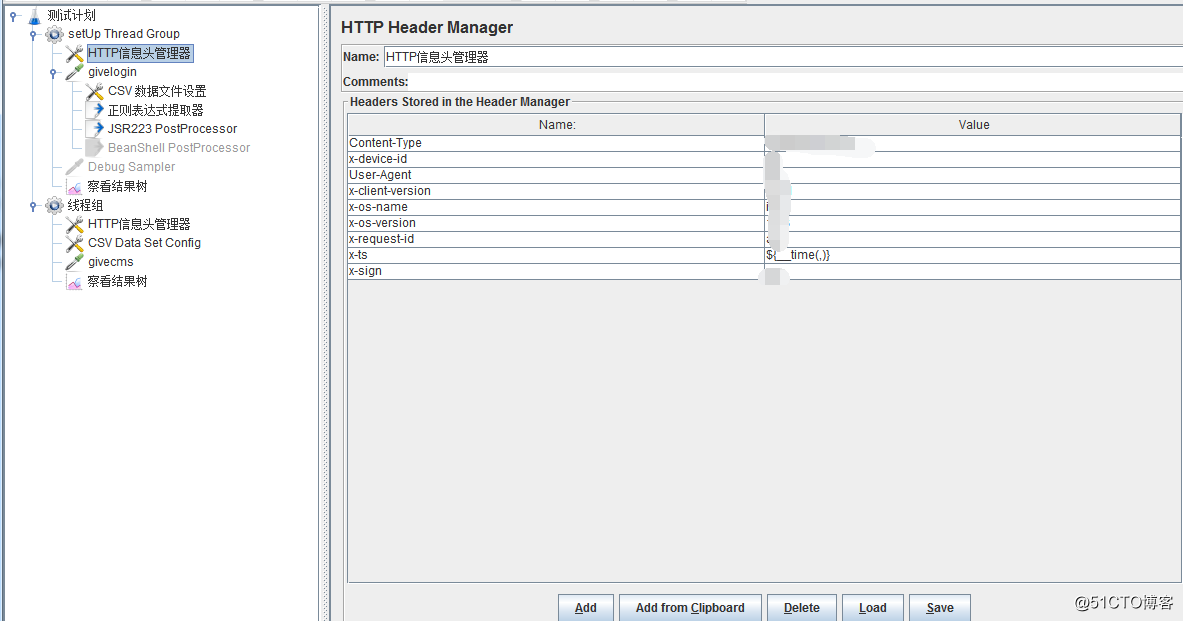
3、添加接口信息:setup Thread Group-->add-->sampler-->http request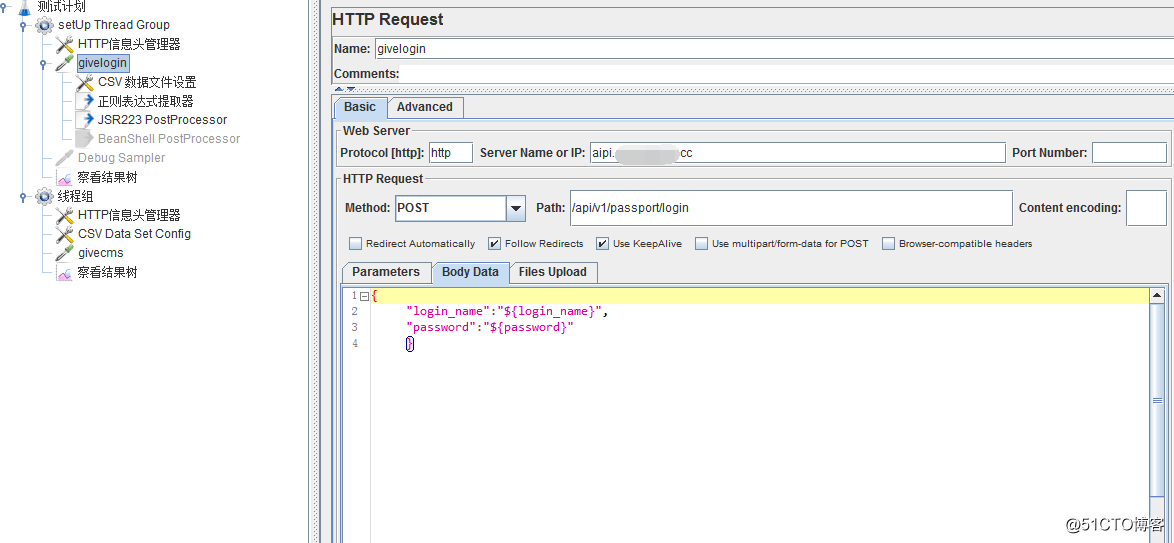
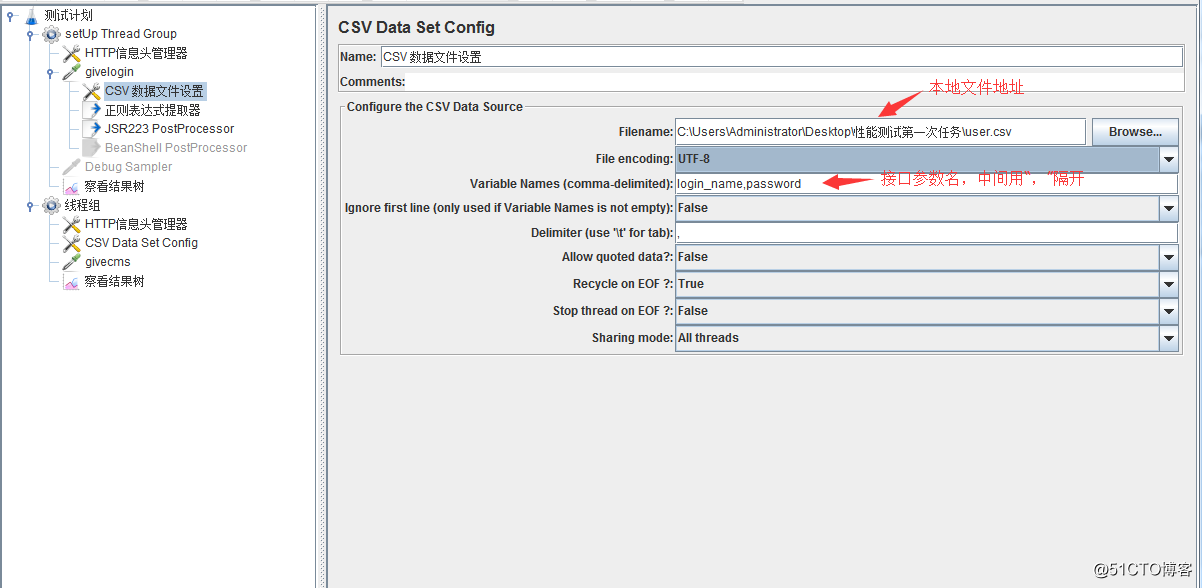
4、因要從本地文件中獲取多個登錄賬號密碼實現多線程測試,所以這裏使用CSV數據文件:
5、只用正則表達式,提取登錄接口返回的token值,以便後續接口使用: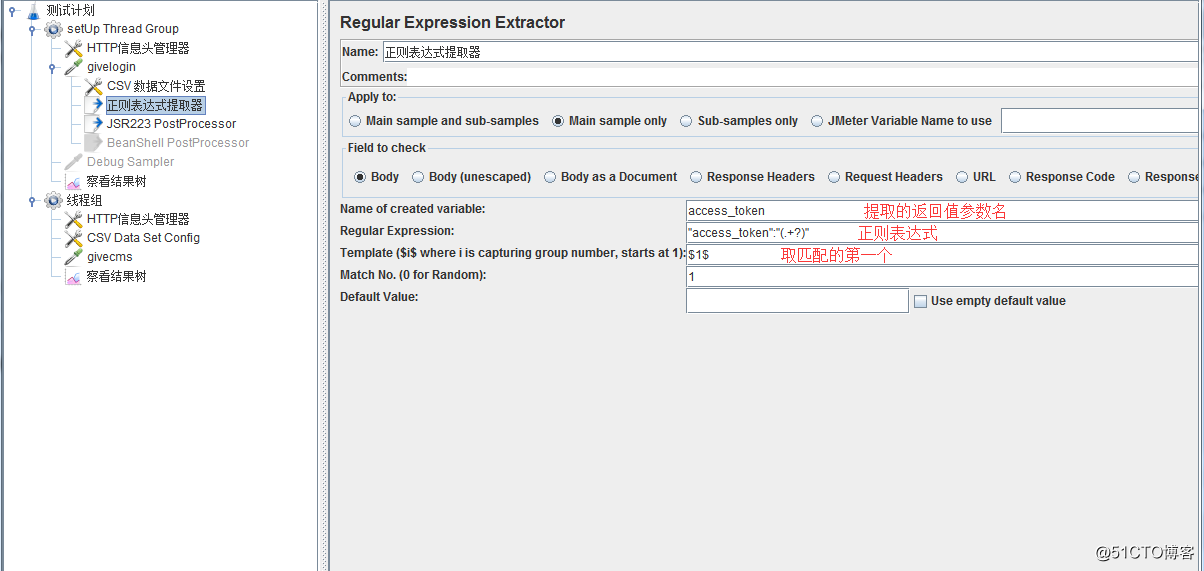
正則使用說明:
引用名稱(Reference Name):Jmeter變量的名稱,存儲提取的結果;即下個請求需要引用的值、字段、變量名。
引用方法:引用方法:${引用名稱}。
正則表達式(Regular Expression):使用正則表達式解析響應結果,“()”表示提取字符串中的部分值,請不要使用“||”,除非你本身需要匹配這個字符。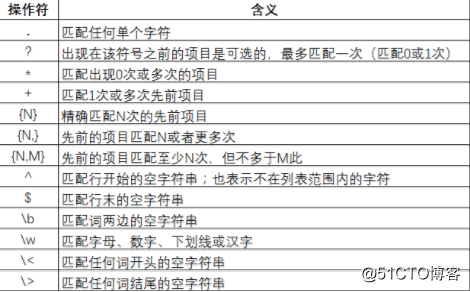
模板(Template):從匹配的結果中創建一個字符串,這是通過正則表達式匹配出來的一組值,意為使用提取到的第幾個值(可能有多個值匹配,因此使用模板);從1開始匹配,以此類推。 參數可以在取值模板組合使用,例如:“1-2”作為模板得到的值是使用“-”連接的第一個待匹配內容與第二個待匹配內容組合而成的字符串。
匹配數字(Match No):正則表達式匹配數據的結果可以看做一個數組,表示如何取值:0代表隨機取值,正數n則表示取第n個值(比如1代表取第一個值),負數則表示提取所有符合條件的值。
缺省值:匹配失敗時候的默認值;通常用於後續的邏輯判斷,一般通常為特定含義的英文大寫組合,比如:ERROR。
6、添加後置處理器JSR223 PostProcessor,將正則獲取到的token數據寫到本地文件: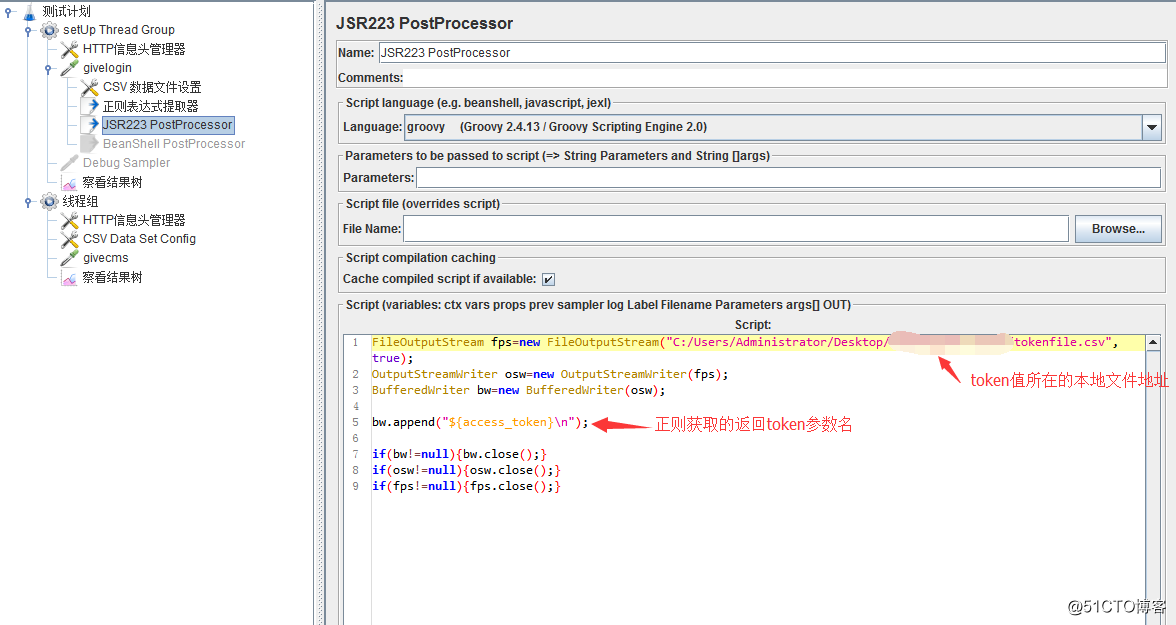
7、添加新的線程組,該線程組中添加的是需要做壓測的接口及相關配置: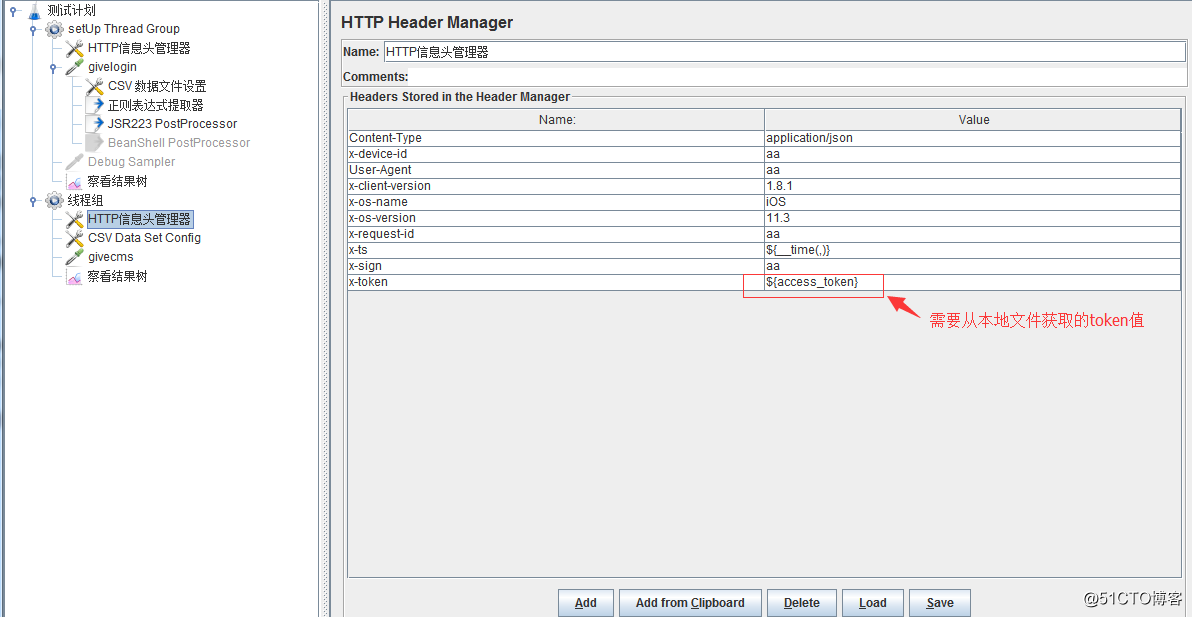
獲取本地文件中的token值依舊使用CSV文件操作。
8、註意事項
獲取token時,需要把其他線程組禁用,只開啟獲取token的接口。
當文件中有token數據時,再講獲取token的接口禁用,開啟其他需要調用token的線程組。
jmeter 正則獲取多個返回token至本地文件,並跨線程組調用