
Elasticsearch入門,這一篇就夠了
實時搜索引擎Elasticsearch
Elasticsearch(簡稱ES)是一個基於Apache Lucene(TM)的開源搜索引擎,無論在開源還是專有領域,Lucene可以被認為是迄今為止最先進、性能最好的、功能最全的搜索引擎庫。
Elasticsearch簡介
Elasticsearch是什麽
Elasticsearch是一個基於Apache Lucene(TM)的開源搜索引擎,無論在開源還是專有領域,Lucene可以被認為是迄今為止最先進、性能最好的、功能最全的搜索引擎庫。
但是,Lucene只是一個庫。想要發揮其強大的作用,你需使用Java並要將其集成到你的應用中。Lucene非常復雜,你需要深入的了解檢索相關知識來理解它是如何工作的。
不過,Elasticsearch不僅僅是Lucene和全文搜索引擎,它還提供:
- 分布式的實時文件存儲,每個字段都被索引並可被搜索
- 實時分析的分布式搜索引擎
- 可以擴展到上百臺服務器,處理PB級結構化或非結構化數據
而且,所有的這些功能被集成到一臺服務器,你的應用可以通過簡單的RESTful API、各種語言的客戶端甚至命令行與之交互。上手Elasticsearch非常簡單,它提供了許多合理的缺省值,並對初學者隱藏了復雜的搜索引擎理論。它開箱即用(安裝即可使用),只需很少的學習既可在生產環境中使用。Elasticsearch在Apache 2 license下許可使用,可以免費下載、使用和修改。
以上內容來自 [百度百科]
Elasticsearch中涉及到的重要概念
Elasticsearch有幾個核心概念。從一開始理解這些概念會對整個學習過程有莫大的幫助。
(1) 接近實時(NRT)
Elasticsearch是一個接近實時的搜索平臺。這意味著,從索引一個文檔直到這個文檔能夠被搜索到有一個輕微的延遲(通常是1秒)。
(2) 集群(cluster)
一個集群就是由一個或多個節點組織在一起,它們共同持有你整個的數據,並一起提供索引和搜索功能。一個集群由一個唯一的名字標識,這個名字默認就是“elasticsearch”。這個名字是重要的,因為一個節點只能通過指定某個集群的名字,來加入這個集群。在產品環境中顯式地設定這個名字是一個好習慣,但是使用默認值來進行測試/開發也是不錯的。
(3) 節點(node)
一個節點是你集群中的一個服務器,作為集群的一部分,它存儲你的數據,參與集群的索引和搜索功能。和集群類似,一個節點也是由一個名字來標識的,默認情況下,這個名字是一個隨機的漫威漫畫角色的名字,這個名字會在啟動的時候賦予節點。這個名字對於管理工作來說挺重要的,因為在這個管理過程中,你會去確定網絡中的哪些服務器對應於Elasticsearch集群中的哪些節點。
一個節點可以通過配置集群名稱的方式來加入一個指定的集群。默認情況下,每個節點都會被安排加入到一個叫做“elasticsearch”的集群中,這意味著,如果你在你的網絡中啟動了若幹個節點,並假定它們能夠相互發現彼此,它們將會自動地形成並加入到一個叫做“elasticsearch”的集群中。
在一個集群裏,只要你想,可以擁有任意多個節點。而且,如果當前你的網絡中沒有運行任何Elasticsearch節點,這時啟動一個節點,會默認創建並加入一個叫做“elasticsearch”的集群。
(4) 索引(index)
一個索引就是一個擁有幾分相似特征的文檔的集合。比如說,你可以有一個客戶數據的索引,另一個產品目錄的索引,還有一個訂單數據的索引。一個索引由一個名字來標識(必須全部是小寫字母的),並且當我們要對對應於這個索引中的文檔進行索引、搜索、更新和刪除的時候,都要使用到這個名字。索引類似於關系型數據庫中Database的概念。在一個集群中,如果你想,可以定義任意多的索引。
(5) 類型(type)
在一個索引中,你可以定義一種或多種類型。一個類型是你的索引的一個邏輯上的分類/分區,其語義完全由你來定。通常,會為具有一組共同字段的文檔定義一個類型。比如說,我們假設你運營一個博客平臺並且將你所有的數據存儲到一個索引中。在這個索引中,你可以為用戶數據定義一個類型,為博客數據定義另一個類型,當然,也可以為評論數據定義另一個類型。類型類似於關系型數據庫中Table的概念。
(6)文檔(document)
一個文檔是一個可被索引的基礎信息單元。比如,你可以擁有某一個客戶的文檔,某一個產品的一個文檔,當然,也可以擁有某個訂單的一個文檔。文檔以JSON(Javascript Object Notation)格式來表示,而JSON是一個到處存在的互聯網數據交互格式。
在一個index/type裏面,只要你想,你可以存儲任意多的文檔。註意,盡管一個文檔,物理上存在於一個索引之中,文檔必須被索引/賦予一個索引的type。文檔類似於關系型數據庫中Record的概念。實際上一個文檔除了用戶定義的數據外,還包括_index、_type和_id字段。
(7) 分片和復制(shards & replicas)
一個索引可以存儲超出單個結點硬件限制的大量數據。比如,一個具有10億文檔的索引占據1TB的磁盤空間,而任一節點都沒有這樣大的磁盤空間;或者單個節點處理搜索請求,響應太慢。
為了解決這個問題,Elasticsearch提供了將索引劃分成多份的能力,這些份就叫做分片。當你創建一個索引的時候,你可以指定你想要的分片的數量。每個分片本身也是一個功能完善並且獨立的“索引”,這個“索引”可以被放置到集群中的任何節點上。
分片之所以重要,主要有兩方面的原因:
- 允許你水平分割/擴展你的內容容量
- 允許你在分片(潛在地,位於多個節點上)之上進行分布式的、並行的操作,進而提高性能/吞吐量
至於一個分片怎樣分布,它的文檔怎樣聚合回搜索請求,是完全由Elasticsearch管理的,對於作為用戶的你來說,這些都是透明的。
在一個網絡/雲的環境裏,失敗隨時都可能發生,在某個分片/節點不知怎麽的就處於離線狀態,或者由於任何原因消失了。這種情況下,有一個故障轉移機制是非常有用並且是強烈推薦的。為此目的,Elasticsearch允許你創建分片的一份或多份拷貝,這些拷貝叫做復制分片,或者直接叫復制。復制之所以重要,主要有兩方面的原因:
- 在分片/節點失敗的情況下,提供了高可用性。因為這個原因,註意到復制分片從不與原/主要(original/primary)分片置於同一節點上是非常重要的。
- 擴展你的搜索量/吞吐量,因為搜索可以在所有的復制上並行運行
總之,每個索引可以被分成多個分片。一個索引也可以被復制0次(意思是沒有復制)或多次。一旦復制了,每個索引就有了主分片(作為復制源的原來的分片)和復制分片(主分片的拷貝)之別。分片和復制的數量可以在索引創建的時候指定。在索引創建之後,你可以在任何時候動態地改變復制數量,但是不能改變分片的數量。
默認情況下,Elasticsearch中的每個索引被分片5個主分片和1個復制,這意味著,如果你的集群中至少有兩個節點,你的索引將會有5個主分片和另外5個復制分片(1個完全拷貝),這樣的話每個索引總共就有10個分片。一個索引的多個分片可以存放在集群中的一臺主機上,也可以存放在多臺主機上,這取決於你的集群機器數量。主分片和復制分片的具體位置是由ES內在的策略所決定的。
以上部分內容轉自Elasticsearch基礎教程,並對其進行了補充。
Elasticsearch安裝與配置
安裝與運行
(1) 從這裏下載Elasticsearch安裝包。一共提供4種格式的安裝包(ZIP、TAR.GZ、DEB和RPM),可以根據自己所使用的系統平臺選擇相應格式的安裝包進行下載。(建議使用Linux系統,本人在2臺windows機器上嘗試啟動過,一臺機器上無法正常啟動,另外一臺可以)
(2) 對下載的安裝包進行解壓縮即可完成安裝操作。下面以在Ubuntu操作系統下使用TAR.GZ格式的1.5.0版本的安裝包為例進行安裝。在Linux shell中輸入下面的命令解壓縮。
tar –vxf elasticsearch-1.5.0.tar.gz安裝成功,下面運行ES。
註意:Elasticsearch需要Java虛擬機的支持,在運行之前保證機器上安裝了JDK,並且JDK版本不能低於1.7_55。
(3) 現在可以直接使用默認配置啟動Elasticsearch了。
假設安裝包解壓後的目錄路徑為【/home/elasticsearch/elasticsearch-1.5.0】,下面軍用$ES_HOME來表示這個路徑。執行下面的命令:
cd /home/elasticsearch/elasticsearch-1.5.0/bin/
chmod +x *
./elasticsearch
如果出現如圖所示的界面(最後打印出started),則說明Elasticsearch啟動成功。
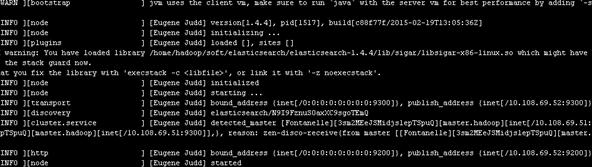
下面來驗證一下是否真的啟動成功。打開瀏覽器,訪問網址 http://host:9200(這裏的host是ES的安裝主機地址,如果安裝在本機,就是http://127.0.0.1:9200)。如果顯示下面的信息,則表示ES安裝成功。
{
"status" : 200,
"name" : "Captain Zero",
"cluster_name" : "elasticsearch",
"version" : {
"number" : "1.5.0",
"build_hash" : "544816042d40151d3ce4ba4f95399d7860dc2e92",
"build_timestamp" : "2015-03-23T14:30:58Z",
"build_snapshot" : false,
"lucene_version" : "4.10.4"
},
"tagline" : "You Know, for Search"
}
上面是前臺啟動方式,一旦關閉Linux shell,ES服務就會停止。所以是實際使用過程中,絕對不會使用這種方式去啟動ES。除了上面的啟動方式外,還可以加上一定的啟動參數。例如:
./elasticsearch –d #在後臺運行Elasticsearch ./elasticsearch -d -Xmx2g -Xms2g #後臺啟動,啟動時指定內存大小(2G) ./elasticsearch -d -Des.logger.level=DEBUG #可以在日誌中打印出更加詳細的信息。
ES的配置
配置文件所在的目錄路徑如下:$ES_HOME/config/elasticsearch.yml。
下面介紹一些重要的配置項及其含義。
(1)cluster.name: elasticsearch
配置elasticsearch的集群名稱,默認是elasticsearch。elasticsearch會自動發現在同一網段下的集群名為elasticsearch的主機,如果在同一網段下有多個集群,就可以用這個屬性來區分不同的集群。生成環境時建議更改。
(2)node.name: “Franz Kafka”
節點名,默認隨機指定一個name列表中名字,該列表在elasticsearch的jar包中config文件夾裏name.txt文件中,其中有很多作者添加的有趣名字,大部分是漫威動漫裏面的人物名字。生成環境中建議更改以能方便的指定集群中的節點對應的機器
(3)node.master: true
指定該節點是否有資格被選舉成為node,默認是true,elasticsearch默認集群中的第一臺啟動的機器為master,如果這臺機掛了就會重新選舉master。
(4)node.data: true
指定該節點是否存儲索引數據,默認為true。如果節點配置node.master:false並且node.data: false,則該節點將起到負載均衡的作用
(5)index.number_of_shards: 5
設置默認索引分片個數,默認為5片。經本人測試,索引分片對ES的查詢性能有很大的影響,在應用環境,應該選擇適合的分片大小。
(6)index.number_of_replicas:
設置默認索引副本個數,默認為1個副本。此處的1個副本是指index.number_of_shards的一個完全拷貝;默認5個分片1個拷貝;即總分片數為10。
(7)path.conf: /path/to/conf
設置配置文件的存儲路徑,默認是es根目錄下的config文件夾。
(8)path.data:/path/to/data1,/path/to/data2
設置索引數據的存儲路徑,默認是es根目錄下的data文件夾,可以設置多個存儲路徑,用逗號隔開。
(9)path.work:/path/to/work
設置臨時文件的存儲路徑,默認是es根目錄下的work文件夾。
(10)path.logs: /path/to/logs
設置日誌文件的存儲路徑,默認是es根目錄下的logs文件夾
(11)path.plugins: /path/to/plugins
設置插件的存放路徑,默認是es根目錄下的plugins文件夾
(12)bootstrap.mlockall: true
設置為true來鎖住內存。因為當jvm開始swapping時es的效率會降低,所以要保證它不swap,可以把ES_MIN_MEM和ES_MAX_MEM兩個環境變量設置成同一個值,並且保證機器有足夠的內存分配給es。同時也要允許elasticsearch的進程可以鎖住內存,linux下可以通過
ulimit -l unlimited命令。
(13)network.bind_host: 192.168.0.1
設置綁定的ip地址,可以是ipv4或ipv6的,默認為0.0.0.0。
(14)network.publish_host: 192.168.0.1
設置其它節點和該節點交互的ip地址,如果不設置它會自動判斷,值必須是個真實的ip地址。
(15)network.host: 192.168.0.1
這個參數是用來同時設置bind_host和publish_host上面兩個參數。
(16)transport.tcp.port: 9300
設置節點間交互的tcp端口,默認是9300。
(17)transport.tcp.compress: true
設置是否壓縮tcp傳輸時的數據,默認為false,不壓縮。
(18)http.port: 9200
設置對外服務的http端口,默認為9200。
(19)http.max_content_length: 100mb
設置內容的最大容量,默認100mb
(20)http.enabled: false
是否使用http協議對外提供服務,默認為true,開啟。
(21)gateway.type: local
gateway的類型,默認為local即為本地文件系統,可以設置為本地文件系統,分布式文件系統,hadoop的HDFS,和amazon的s3服務器,其它文件系統的設置。
(22)gateway.recover_after_nodes: 1
設置集群中N個節點啟動時進行數據恢復,默認為1。
(23)gateway.recover_after_time: 5m
設置初始化數據恢復進程的超時時間,默認是5分鐘。
(24)gateway.expected_nodes: 2
設置這個集群中節點的數量,默認為2,一旦這N個節點啟動,就會立即進行數據恢復。
(25)cluster.routing.allocation.node_initial_primaries_recoveries: 4
初始化數據恢復時,並發恢復線程的個數,默認為4。
(26)cluster.routing.allocation.node_concurrent_recoveries: 2
添加刪除節點或負載均衡時並發恢復線程的個數,默認為4。
(27)indices.recovery.max_size_per_sec: 0
設置數據恢復時限制的帶寬,如入100mb,默認為0,即無限制。
(28)indices.recovery.concurrent_streams: 5
設置這個參數來限制從其它分片恢復數據時最大同時打開並發流的個數,默認為5。
(29)discovery.zen.minimum_master_nodes: 1
設置這個參數來保證集群中的節點可以知道其它N個有master資格的節點。默認為1,對於大的集群來說,可以設置大一點的值(2-4)
(30)discovery.zen.ping.timeout: 3s
設置集群中自動發現其它節點時ping連接超時時間,默認為3秒,對於比較差的網絡環境可以高點的值來防止自動發現時出錯。
(31)discovery.zen.ping.multicast.enabled: false
設置是否打開多播發現節點,默認是true。
(32)discovery.zen.ping.unicast.hosts: [“host1”, “host2:port”, “host3 [portX-portY] “]
設置集群中master節點的初始列表,可以通過這些節點來自動發現新加入集群的節點。
除了上面的在安裝時配置文件中就自帶的配置項外,本人在實際使用過程還使用到了下面的配置:
threadpool:
search:
type: fixed
min: 60
max: 80
queue_size: 1000
// 配置es服務器的執行查詢操作時所用線程池,fix固定線程數的線程池。
index :
store:
type: memory
// 表示索引存儲在內存中,當然es不太建議這麽做。經本人測試,做查詢時,使用內存索引並不會比正常的索引快。
index.mapper.dynamic: false
// 禁止自動創建mapping。默認情況下,es可以根據數據類型自動創建mapping。配置成這樣,可以禁止自動創建mapping的行為。至於什麽是mapping,在之後的博文中再介紹。
index.query.parse.allow_unmapped_fields: false
// 不能查找沒有在mapping中定義的屬性
以上總結介紹了Elasticsearch中的一些基礎知識,包括其中的一些核心概念。只有理解了ES中的這些核心概念,才能對更加得心應手地使用ES,發揮其強大的搜索能力。同時,也介紹了ES的安裝和運行,ES的安裝和運行是很簡單的,只需要極少的簡單步驟,就可以開始體驗ES。ES的配置非常豐富,安裝時自帶的配置文件只包含一部分比較核心的配置項,更多的配置內容需要自己去閱讀ES的源碼時才能被發現。
ES Restful API基本使用:
ES為開發者提供了非常豐富的基於HTTP協議的Rest API,只需要向ES服務端發送簡單的Rest請求,就可以實現非常強大的功能。本篇文章主要介紹ES中常用操作的Rest API的使用,同時會講解ES的源代碼工程中的API接口文檔,通過了解這個API文檔的接口描述結構,就基本上可以實現ES中的絕大部分功能。
註意:查詢是ES的核心。作為一個先進的搜索引擎,ES中提供了多種查詢接口。本篇僅僅會涉及查詢API的結構,而具體如何使用ES所提供的各種查詢API,會在接下來的博文中做詳細介紹。
基礎知識
如果之前沒有用過類似於ES這樣的索引數據庫(暫且將ES歸為數據庫類,與傳統的數據庫有較大的區別),要理解本篇博文介紹的API是有些難度的。本節先介紹一些基礎知識,對理解全文有很幫助。
Rest介紹
筆者在學習軟件開發過程中,多次聽到過Rest Http這個概念,但在很長的一段時間裏,死活搞不懂這玩意到底是個什麽東西。剛開始看相關資料時,看得雲裏霧裏,完全不知所雲 _。這玩意太過於抽象和理論,心裏覺得有必要搞這麽復雜麽。隨著自己動手開發的東西越來越多,才開始對它有了一丟丟感覺。
Rest完全不是三言兩語就能將清楚的,它有自己的一套體系,所以筆者打算以後單獨寫一些有關Rest的博文。在這裏推薦一篇優秀的文章,它對Rest講的相當清楚,本人看完之後真有醍醐灌頂的感覺!
Mapping詳解
Mapping是ES中的一個很重要的內容,它類似於傳統關系型數據中table的schema,用於定義一個索引(index)的某個類型(type)的數據的結構。
在傳統關系型數據庫,我們必須首先創建table並同時定義其schema,如下面的SQL語句。下面代碼中小括號內的代碼的作用就是定義person_info的schema(模式)。
create table person_info
(
name varchar(20),
age tinyint
)
在ES中,我們無需手動創建type(相當於table)和mapping(相關與schema)。在默認配置下,ES可以根據插入的數據自動地創建type及其mapping。在下面的API介紹部分中,會做相關的試驗。當然,在實際使用過程中我們可能就想硬性規定mapping,可以通過配置文件關閉ES的自動創建mapping功能。
mapping中主要包括字段名、字段數據類型和字段索引類型這3個方面的定義。
字段名:這就不用說了,與傳統數據庫字段名作用一樣,就是給字段起個唯一的名字,好讓系統和用戶能識別。
字段數據類型:定義該字段保存的數據的類型,不符合數據類型定義的數據不能保存到ES中。下表列出的是ES中所支持的數據類型。(大類是對所有類型的一種歸類,小類是實際使用的類型。)
| 大類 | 包含的小類 |
|---|---|
| String | string |
| Whole number | byte, short, integer, long |
| Floating point | float, double |
| Boolean | boolean |
| Date | date |
字段索引類型:索引是ES中的核心,ES之所以能夠實現實時搜索,完全歸功於Lucene這個優秀的Java開源索引。在傳統數據庫中,如果字段上建立索引,我們仍然能夠以它作為查詢條件進行查詢,只不過查詢速度慢點。而在ES中,字段如果不建立索引,則就不能以這個字段作為查詢條件來搜索。也就是說,不建立索引的字段僅僅能起到數據載體的作用。string類型的數據肯定是日常使用得最多的數據類型,下面介紹mapping中string類型字段可以配置的索引類型。
| 索引類型 | 解釋 |
|---|---|
| analyzed | 首先分析這個字符串,然後再建立索引。換言之,以全文形式索引此字段。 |
| not_analyzed | 索引這個字段,使之可以被搜索,但是索引內容和指定值一樣。不分析此字段。 |
| no | 不索引這個字段。這個字段不能被搜索到。 |
如果索引類型設置為analyzed,在表示ES會先對這個字段進行分析(一般來說,就是自然語言中的分詞),ES內置了不少分析器(analyser),如果覺得它們對中文的支持不好,也可以使用第三方分析器。由於筆者在實際項目中僅僅將ES用作普通的數據查詢引擎,所以並沒有研究過這些分析器。如果將ES當做真正的搜索引擎,那麽挑選正確的分析器是至關重要的。
mapping中除了上面介紹的3個主要的內容外,還有其他的定義內容,詳見官網文檔。
常用的Rest API介紹
下面介紹一下ES中的一些常用的Rest API。掌握了這些API的用法,基本上就可以簡單地使用ES了。
我們需要借助能夠發送HTTP請求的工具調用這些API,工具是可以任意的,包括網頁瀏覽器。這裏利用Linux上的curl命令來發送HTTP請求。基本的命令結構為:
curl <-Xaction> url -d ‘body‘
# 這裏的action表示HTTP協議中的各種動作,包括GET、POST、PUT、DELETE等。
註意。文中的示例代碼裏面包含了用戶註釋的文字,就是 # 號後面的文字。運行代碼時,請註意刪除這些註釋。
查看集群(Cluster)信息相關API
(1)查看集群健康信息。
curl -XGET "localhost:9200/_cat/heath?v"返回結果為:
epoch timestamp cluster status node.total node.data shards pri relo init unassign pending_tasks
1440206633 18:23:53 elasticsearch green 1 1 0 0 0 0 0 0
返回結果的主要字段意義:
- cluster:集群名,是在ES的配置文件中配置的cluster.name的值。
- status:集群狀態。集群共有green、yellow或red中的三種狀態。green代表一切正常(集群功能齊全),yellow意味著所有的數據都是可用的,但是某些復制沒有被分配(集群功能齊全),red則代表因為某些原因,某些數據不可用。如果是red狀態,則要引起高度註意,數據很有可能已經丟失。
- node.total:集群中的節點數。
- node.data:集群中的數據節點數。
- shards:集群中總的分片數量。
- pri:主分片數量,英文全稱為private。
- relo:復制分片總數。
- unassign:未指定的分片數量,是應有分片數和現有的分片數的差值(包括主分片和復制分片)。
我們也可以在請求中添加help參數來查看每個操作返回結果字段的意義。
curl -XGET "localhost:9200/_cat/heath?help"返回結果如下:
epoch | t,time | seconds since 1970-01-01 00:00:00
timestamp | ts,hms,hhmmss | time in HH:MM:SS
cluster | cl | cluster name
status | st | health status
node.total | nt,nodeTotal | total number of nodes
node.data | nd,nodeData | number of nodes that can store data
shards | t,sh,shards.total,shardsTotal | total number of shards
pri | p,shards.primary,shardsPrimary | number of primary shards
relo | r,shards.relocating,shardsRelocating | number of relocating nodes
init | i,shards.initializing,shardsInitializing | number of initializing nodes
unassign | u,shards.unassigned,shardsUnassigned | number of unassigned shards
pending_tasks | pt,pendingTasks | number of pending tasks
確實是很好很強大。有了這個東東,就可以減少看文檔的時間。ES中許多API都可以添加help參數來顯示字段含義,哪些可以這麽做呢?每個API都試試就知道了。
當然,如果你覺得返回的東西太多,看著眼煩,我們也可以人為地指定返回的字段。
curl -XGET "localhost:9200/_cat/health?h=cluster,pri,relo&v"這次的返回結果就簡單很多羅。對於患有嚴重強迫癥的患者來說,這是福音啊!
cluster pri relo
elasticsearch 0 0 (2)查看集群中的節點信息。
curl -XGET "localhost:9200/_cat/nodes?v"返回節點的詳細信息如下:
host ip heap.percent ram.percent load node.role master name
master.hadoop localhost 3 35 0.00 d * Ezekiel
(3)查看集群中的索引信息。
curl -XGET "localhost:9200/_cat/indices?v"
返回集群中的索引信息如下:
health status index pri rep docs.count docs.deleted store.size pri.store.size
yellow open index_test 5 1 0 0 575b 575b
更多的查看和監視ES的API參見官網文檔。
索引(Index)相關API
(1)創建一個新的索引。
curl -XPUT "localhost:9200/index_test"如果返回下面的信息,則說明索引創建成功。如果不是,則ES會返回相應的異常信息。通常可以通過異常信息的最後一項推斷出失敗的原因。
{
"acknowledged": true
}上面的操作使用默認的配置信息創建一個索引。大多數情況下,我們想在索引創建的時候就將我們所需的mapping和其他配置確定好。下面的操作就可以在創建索引的同時,創建settings和mapping。
curl -XPUT "localhost:9200/index_test" -d ‘ # 註意這裏的‘號
{
"settings": {
"index": {
"number_of_replicas": "1", # 設置復制數
"number_of_shards": "5" # 設置主分片數
}
},
"mappings": { # 創建mapping
"test_type": { # 在index中創建一個新的type(相當於table)
"properties": {
"name": { # 創建一個字段(string類型數據,使用普通索引)
"type": "string",
"index": "not_analyzed"
},
"age": {
"type": "integer"
}
}
}
}
}‘
(2)刪除一個索引。
curl -XDELETE "localhost:9200/index_test"如果返回與創建索引同樣的信息,則說明刪除成功。反之,則返回相應的異常信息。更多的索引操作參見ES官網文檔。
映射(Mapping)相關API
(1)創建索引的mapping。
curl -XPUT ‘localhost:9200/index_test/_mapping/test_type‘ -d ‘
{
"test_type": { # 註意,這裏的test_type與url上的test_type名保存一致
"properties": {
"name": {
"type": "string",
"index": "not_analyzed"
},
"age": {
"type": "integer"
}
}
}
}‘
如果不想單獨創建mapping,可以使用上一節的方法(創建索引時創建mappings)。
假設我們的項目中有多個環境(開發環境、測試環境等),那每一個環境的mapping總要一致的吧,那每次創建一次mappings就比較麻煩了,而且還容易導致數據不一致。莫急,ES還給我們準備另外一種創建mapping的方式。可以按照下面的步驟來做。
步驟1 創建一個擴展名為test_type.json的文件名,其中type_test就是mapping所對應的type名。
步驟2 在test_type.json中輸入mapping信息。假設你的mapping如下:
{
"test_type": { # 註意,這裏的test_type與json文件名必須一致
"properties": {
"name": {
"type": "string",
"index": "not_analyzed"
},
"age": {
"type": "integer"
}
}
}
}
步驟3 在$ES_HOME/config/路徑下創建mappings/index_test子目錄,這裏的index_test目錄名必須與我們要建立的索引名一致。將test_type.json文件拷貝到index_tes目錄下。
步驟4 創建index_test索引。操作如下:
curl -XPUT "localhost:9200/index_test" # 註意,這裏的索引名必須與mappings下新建的index_test目錄名一致這樣我們就創建了一個新的索引,並且使用了test_type.json所定義的mapping作為索引的mapping。就是這麽簡單方便!
(2)刪除mapping。
curl -XDELETE ‘localhost:9200/index_test/_mapping/test_type‘(3)查看索引的mapping。
curl -XGET ‘localhost:9200/index_test/_mapping/test_type‘
更多的mapping相關操作參加官網文檔。
文檔(document)相關API
(1)新增一個文檔。
curl -XPUT ‘localhost:9200/index_test/test_type/1?pretty‘ -d ‘ # 這裏的pretty參數的作用是使得返回的json顯示地更加好看。1是文檔的id值(唯一鍵)。
{
"name": "zhangsan",
"age" : "12"
}‘
(2)更新一個文檔
curl -XPOST ‘localhost:9200/index_test/test_type/1?pretty‘ -d ‘ # 這裏的1必須是索引中已經存在id,否則就會變成新增文檔操作
{
"name": "lisi",
"age" : "12"
}‘
(3)刪除一個文檔
curl -XDELETE ‘localhost:9200/index_test/test_type/1?pretty‘ # 這裏的1必須是索引中已經存在id
(4)查詢單個文檔
curl -XGET ‘localhost:9200/index_test/test_type/1?pretty‘
上面的操作僅僅查詢id為1的一條文檔,這樣看似乎ES的查詢也太弱了。前面已經說過了,查詢操作是ES中的核心,是其立身的根本。但是本文的重點並不在這裏,為了防止文章的篇幅過長,之後將專本介紹ES中的查詢操作。
源代碼中提供的Rest API文檔結構
ES的源代碼托管在Github上。將源代碼下載下來之後,裏面有一個文件夾專門存放ES中絕大部分的Rest API。有了這些文檔,就不必每次都要到官網上查詢接口文檔了(PS:ES的官網真的很慢)。
下面以cat.health.json文件為例簡單地介紹這些Rest API文檔的結構。一旦結構搞清楚了,文檔看起來就比較順心,ES用起來就更加得心應手了!
{
"cat.health": {
"documentation": "http://www.elastic.co/guide/en/elasticsearch/reference/master/cat-health.html", # 該文檔對應的官方站點
"methods": ["GET"],
"url": { # url部分可選
"path": "/_cat/health",
"paths": ["/_cat/health"],
"parts": {
},
"params": {
"local": {
"type" : "boolean",
"description" : "Return local information, do not retrieve the state from master node (default: false)"
},
"master_timeout": {
"type" : "time",
"description" : "Explicit operation timeout for connection to master node"
},
"h": {
"type": "list",
"description" : "Comma-separated list of column names to display"
},
"help": {
"type": "boolean",
"description": "Return help information",
"default": false
},
"ts": {
"type": "boolean",
"description": "Set to false to disable timestamping",
"default": true
},
"v": {
"type": "boolean",
"description": "Verbose mode. Display column headers",
"default": true
}
}
},
"body": null
}
}
上面文檔接口所對應的Reqeust操作如下:
curl -XGET "localhost:9200/_cat/health?v" -d ‘body‘
該操作命令可劃分為5個部分,下面把這5個部分與文檔對應起來。通過這個例子,就可以在閱讀其他文檔後,使用正確的操作了。
- 第1部分(-XGET):對應文檔中methods所包含的GET操作。
- 第2部分(localhost:9200):是ES服務端所在主機的hostname和port。
- 第3部分(/_cat/health):對應文檔中的url。其中path是最簡單的url;paths是除了path之外的其他url;parts描述和解釋paths裏面的url的可變部分(通常用{}包裹,如{index})。
- 第4部分v:表示參數,對應文檔中的params。像“v”這種boolean類型的參數,不需要特意指定其布爾值(true或者false),出現即表示true,否則為false。
- 第5部分body:表示要傳遞的數據主體,對應文檔中的body。如果body裏面指明“required=true”,則表示必須傳入body數據。具體body裏面需要傳怎樣的數據,則可以訪問文檔中的documentation字段所指明的官方站點進行查詢。
總結
本文重點介紹了ES中的一些常用Rest API的用法,並在開始部分簡單地介紹了一些基礎知識(Rest和mapping)。掌握了這些API的調用,就可以利用ES完成簡單的應用程序了。當然,ES的API遠不止這些,如果想要更加深入地了解ES的使用及其內部原理,建議先仔細地閱讀ES的官網文檔。然後下載其源代碼進行研究。
想進階的同學,請參考:
Elasticsearch: 權威指南
Elasticsearch入門,這一篇就夠了