
高並發下怎麽優化能避免服務器壓力過大?

用戶多,不代表你服務器訪問量大,訪問量大不一定你服務器壓力大!我們換成專業點的問題,高並發下怎麽優化能避免服務器壓力過大?
1,整個架構:可采用分布式架構,利用微服務架構拆分服務部署在不同的服務節點,避免單節點宕機引起的服務不可用!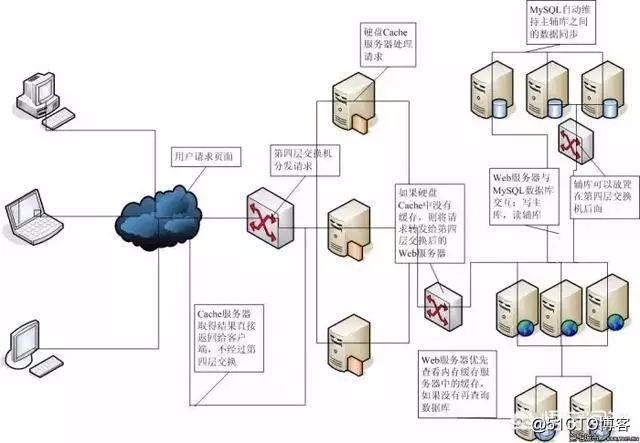
2,數據庫:采用主從復制,讀寫分離,甚至是分庫分表,表數據根據查詢方式的不同采用不同的索引比如b tree,hash,關鍵字段加索引,sql避免復合函數,避免組合排序等,避免使用非索引字段作為條件分組,排序等!減少交互次數,一定不要用select *!
3,加緩存:使用諸如memcache,redis,ehcache等緩存數據庫定義表,結果表等等,數據庫的中間數據放緩存,避免多次訪問修改表數據!登錄信息session等放緩存實現共享!諸如商品分類,省市區,年齡分類等不常改變的數據,放緩存,不要放數據庫!
同時要避免緩存雪崩和穿透等問題的出現導致緩存崩潰!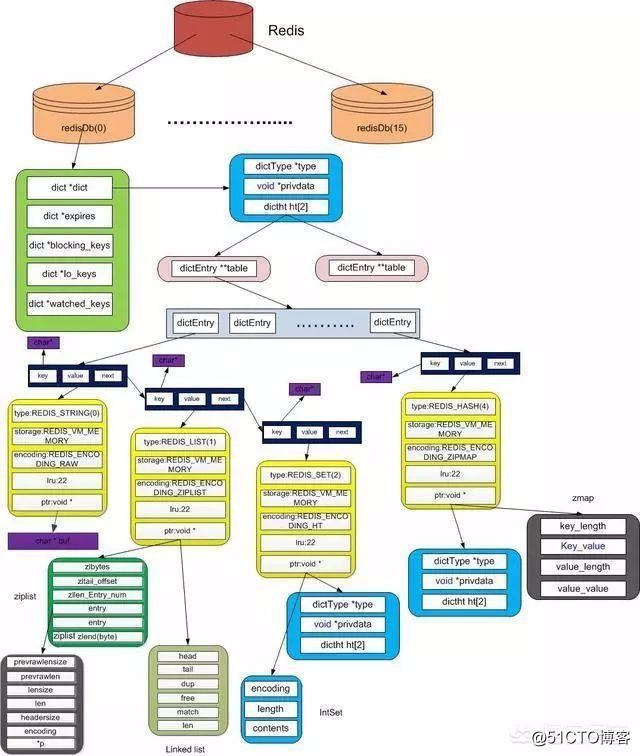
4,增量統計:不要實時統計大量的數據,應該采用晚間定時任務統計,增量統計等方式提前進行統計,避免實時統計的內存,CPU壓力!
5,加圖片服務器:圖片等大文件,一定要單獨經過文件服務器,避免IO速度對動態數據的影響!保證系統不會因為文件而崩潰!
6,HTML文件,枚舉,靜態的方法返回值等靜態化處理,放入緩存!
7,負載均衡:使用nginx等對訪問量過大的服務采用負載均衡,實現服務集群,提高服務的最大並發數,防止壓力過大導致單個服務的崩潰!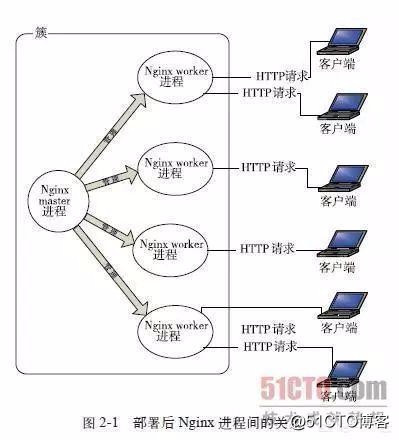
8,加入搜索引擎:對於sql中常出現的like,in等語句,使用lucence或者solr中間件,將必要的,依賴模糊搜索的字段和數據使用搜索引擎進行存儲,提升搜索速度!#註意:全量數據和增量數據進行定時任務更新!
9,使用消息中間件:對服務之間的數據傳輸,使用諸如rabbit mq,kafka等等分布式消息隊列異步傳輸,防止同步傳輸數據的阻塞和數據丟失!
10,拋棄tomcat:做web開發,接觸最早的應用服務器就是tomcat了,但是tomcat的單個最大並發量只能不到1w!采取netty等actor模型的高性能應用服務器!
11,多線程:現在的服務器都是多核心處理模式,如果代碼采用單線程,同步方式處理,極大的浪費了CPU使用效率和執行時間!
12,避免阻塞:避免bio,blockingqueue等常常引起長久阻塞的技術,而改為nio等異步處理機制!
13,CDN加速:如果訪問量實在過大,可根據請求來源采用CDN分流技術,避免大流量完成系統崩潰!
14,避免低效代碼:不要頻繁創建對象,引用,少用同步鎖,不要創建大量線程,不要多層for循環!
當然還有更多的細節優化技術!
高並發下怎麽優化能避免服務器壓力過大?