
Hadoop數據操作系統YARN全解析
Hadoop 2.0引入了數據操作系統YARN。YARN的引入,大大提高了集群的資源利用率,並降低了集群管理成本。首先,YARN允許多個應用程序運行在一個集群中,並將資源按需分配給它們,這大大提高了資源利用率,其次,YARN允許各類短作業和長服務混合部署在一個集群中,並提供了容錯、資源隔離及負載均衡等方面的支持,這大大簡化了作業和服務的部署和管理成本。
[toc]
分享之前我還是要說下我自己創建的大數據交流群:784557197, 不管是學生還是大神 ,都歡迎加入一起探討
YARN總體上采用master/slave
master被稱為ResourceManager,slave被稱為NodeManager,ResourceManager負責對各個NodeManager上的資源進行統一管理和調度。當用戶提交一個應用程序時,需要提供一個用以跟蹤和管理這個程序的ApplicationMaster,它負責向ResourceManager申請資源,並要求NodeManger啟動可以占用一定資源的Container。由於不同的ApplicationMaster被分布到不同的節點上,並通過一定的隔離機制進行了資源隔離,因此它們之間不會相互影響。
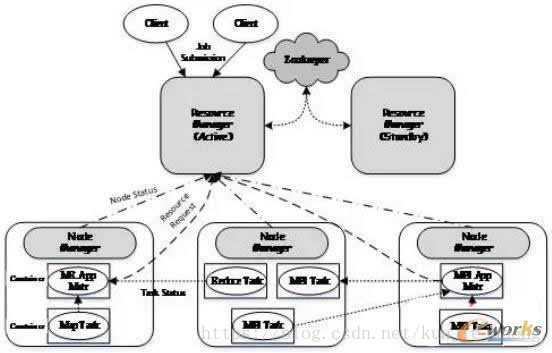
YARN中的資源管理和調度功能由資源調度器負責,它是Hadoop YARN中最核心的組件之一,是ResourceManager中的一個插拔式服務組件 。YARN通過層級化隊列的方式組織和劃分資源,並提供了多種多租戶資源調度器,這種調度器允許管理員按照應用需求對用戶或者應用程序分組,並為不同的分組分配不同的資源量,同時通過添加各種約束防止單個用戶或者應用程序獨占資源,進而能夠滿足各種QoS需求,典型代表是Yahoo!的Capacity Scheduler
Facebook的Fair Scheduler。
YARN作為一個通用數據操作系統,既可以運行像MapReduce、Spark這樣的短作業,也可以部署像Web Server、MySQL Server這種長服務,真正實現一個集群多用途,這樣的集群,我們通常稱為輕量級彈性計算平臺,說它輕量級,是因為YARN采用了cgroups輕量級隔離方案,說它彈性,是因為YARN能根據各種計算框架或者應用的負載或者需求調整它們各自占用的資源,實現集群資源共享,資源彈性收縮。
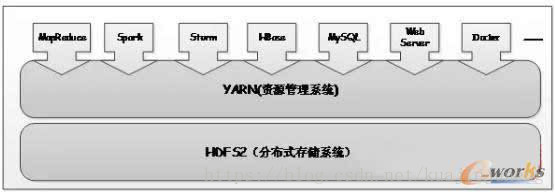
Hadoop YARN在異構集群中的應用
從2.6.0版本開始,YARN引入了一種新的調度策略:基於標簽的調度機制。該機制的主要引入動機是更好地讓YARN運行在異構集群中,進而更好地管理和調度混合類型的應用程序
1.什麽是基於標簽的調度
故名思議,基於標簽的調度是一種調度策略,就像基於優先級的調度一樣,是調度器中眾多調度策略中的一種,可以跟其他調度策略混合使用。該策略的基本思想是:用戶可為每個NodeManager打上標簽,比如highmem,highdisk等,以作為NodeManager的基本屬性;同時,用戶可以為調度器中的隊列設置若幹標簽,以限制該隊列只能占用包含對應標簽的節點資源,這樣,提交到某個隊列中的作業,只能運行在特定一些節點上。通過打標簽,用戶可將Hadoop分成若幹個子集群,進而使得用戶可將應用程序運行到符合某種特征的節點上,比如可將內存密集型的應用程序(比如Spark)運行到大內存節點上。
2.Hulu應用案例
基於標簽的調度策略在Hulu內部有廣泛的應用。之所以啟用該機制,主要出於以下三點考慮:
- 集群是異構的。在Hadoop集群演化過程中,後來新增機器的配置通常比舊機器好,這使得集群最終變為一個異構的集群。Hadoop設計之初眾多設計機制假定集群是同構的,即使發展到現在,Hadoop對異構集群的支持仍然很不完善,比如MapReduce推測執行機制尚未考慮異構集群情形
- 應用是多樣化的。Hulu在YARN集群之上同時部署了MapReduce、Spark、Spark Streaming、Docker Service等多種類型的應用程序 。當在異構集群混合運行多類應用程序時,經常發生由於機器配置不一導致並行化任務完成時間相差較大的情況,這非常不利於分布式程序的高效執行。此外,由於 YARN無法進行完全的資源隔離,多個應用程序混合運行在一個節點上容易相互幹擾,對於低延遲類型的應用通常是難以容忍的。
- 個性化機器需求。由於對特殊環境的依賴,有些應用程序只能運行在大集群中的特定節點上。典型的代表是spark和docker,spark MLLib可能用到一些native庫,為了防止汙染系統,這些庫通常只會安裝在若幹節點上;docker container的運行依賴於docker engine,為了簡化運維成本,我們 只會讓docker運行在若幹指定的節點上。
為了解決以上問題,Hulu在Capacity Scheduler基礎上啟用了基於標簽的調度策略。如圖3所示,我們根據機器配置和應用程序需求,為集群中的節點打上了多種標簽,包括:
- spark-node:用於運行spark作業的機器,這些機器通常配置較高,尤其是內存較大;
- mr-node:運行MapReduce作業的機器,這些機器配置是多樣的;
- docker-node:運行docker應用程序的機器,這些機器上裝有docker engine;
- streaming-node:運行spark streaming流式應用的機器。
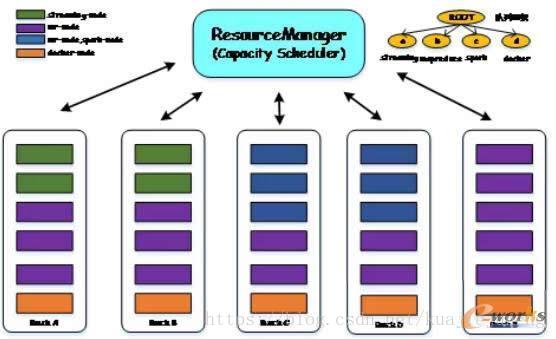
需要註意的是,YARN允許一個節點同時存在多個標簽,進而實現一臺機器混合運行多類應用程序(在hulu內部,我們允許一些節點是共享的,同時可以運行多種應用程序)。表面上看來,通過引入標簽將集群分成了多個物理集群,但實際上,這些物理集群跟傳統意義上完全隔離的集群是不同的,這些集群既相互獨立又相互關聯,用戶可非常容易地通過修改標簽動態調整某個節點的用途。
Hadoop YARN應用案例及經驗總結
.
Hadoop YARN作為一個數據操作系統,提供了豐富的API供用戶開發應用程序。Hulu在YARN應用程序設計方面進行了大量探索和實踐,開發了多個可直接運行在YARN上的分布式計算框架和計算引擎,典型的代表是voidbox和nesto。
(1)基於Docker的容器計算框架 voidbox
Docker是近兩年非常流行的容器虛擬化技術,可以自動化打包部署絕大部分應用,它使得任何程序能夠運行在資源隔離的容器環境,從而提供了一套更加優雅的項目構建、發布、運行的解決方案。
為了整合YARN和Docker各自的獨特優勢,Hulu北京大數據團隊開發了Voidbox。Voidbox是一個分布式的計算框架,利用 YARN作為資源管理模塊,用Docker作為執行任務的引擎,從而讓YARN既可以調度傳統的MapReduce和Spark等類型的應用程序,也可以調度封裝在Docker鏡像中的應用程序。
Voidbox支持基於Docker Container的DAG(有向無環圖)任務和長服務(比如web service),提供命令行方式與IDE方式等多種應用程序提交方式,滿足了生產環境和開發環境的需求。此外,Voidbox可以配合 Jenkins,GitLab,私有的Docker倉庫完成一整套開發、測試、自動發布的流程。
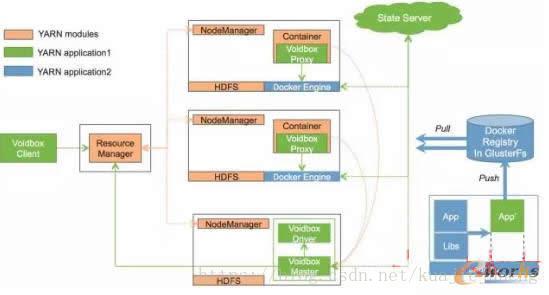
在Voidbox中,YARN負責集群的資源調度,Docker作為一個執行引擎,從Docker Registry中拉取鏡像執行。Voidbox負責為基於容器的DAG任務申請資源,運行Docker任務。如圖4所示,每個黑線框代表一臺機器,上面運行著幾個模塊,具體如下:
Voidbox組件:
- VoidboxClient:客戶端程序。用戶可通過該組件管理Voidbox應用程序(Voidbox應用程序包含一個或多個Docker作業,一個作業包含一個或多個Docker任務),比如提交和殺死Voidbox應用程序等。
- VoidboxMaster:實際上是一個YARN的Application Master,負責向YARN申請資源,並將得到的資源進一步分配給內部的Docker任務。
- VoidboxDriver:負責單個Voidbox應用程序的任務調度。Voidbox支持基於Docker Container的DAG任務調度並且在任務之間可以插入其他用戶代碼,Voidbox Driver負責處理DAG任務之間的依賴順序調度以及運行用戶代碼。
- VoidboxProxy:是YARN與Docker引擎之間的橋梁,負責中轉YARN發向Docker引擎的命令,比如啟動或殺死Docker容器等。
- StateServer:維護各個Docker引擎的健康狀況信息,向Voidbox Master提供可運行Docker Container的機器列表,使得Voidbox Master可以更有效地申請資源。
Docker組件:
- DockerRegistry:存儲Docker鏡像,作為內部Docker鏡像的版本管理工具。
- DockerEngine: Docker Container執行的引擎,從Docker Registry獲取相應的Docker鏡像,執行Docker相關命令。
- Jenkins:配合GitLab進行應用程序的版本管理,當應用版本更新時,Jenkins負責編譯打包,生成Docker鏡像,上傳至Docker Registry,從而完成應用程序自動發布的流程。
類似於spark on yarn,Voidbox也提供兩種應用程序運行模式,分別是yarn-cluster模式和yarn-client模式。yarn-cluster模式中應用程序的控制組件和資源管理組件都運行在集群中,Voidbox應用程序提交成功後,客戶端可以隨時退出而不影響集群中應用程序的運行。yarn- cluster模式適合生產環境提交應用程序;yarn-client模式中應用程序的控制組件運行在客戶端,其他組件運行在集群中,客戶端可以看到關於應用程序運行狀態的更多信息,客戶端退出後,在集群中運行的應用程序也隨即退出,yarn-client模式可以方便用戶進行調試。
(2)並行計算引擎nesto
nesto是hulu內部一個類似於presto/impala的MPP計算引擎,它是專門為處理復雜的嵌套式數據而設計的,支持復雜的數據處理邏輯(SQL難以表達),其采用了列式存儲、code generation等優化技術以加速數據處理效率。Nesto架構類似於presto/impala,它是無中心化的,多個nesto server通過zookeeper進行服務發現。
為了簡化nesto部署和管理成本,hulu直接將nesto部署到YARN上。這樣,nesto安裝部署過程將變得非常簡單:Nesto安裝程序 (包括配置文件和jar包)被打成一個獨立的壓縮包存放到HDFS,用戶可通過運行一個提交命令,並指定啟動的nesto server數目、每個server需要的資源等信息,即可快速部署一套nesto集群。
Nesto on yarn程序由一個ApplicationMaster和多個Executor構成,其中ApplicationMaster負責像YARN申請資源,並啟動Executor,而Executor的作用是啟動nesto server,關鍵設計點在ApplicationMaster,它的功能包括:
與ResourceManager通信,申請資源,這些資源需保證來自不同的結點,以達到每個節點只啟動一個Executor的目的;
與NodeManager通信,啟動Executor,並監控這些Executor健康狀況,一旦發現某個Executor出現故障,則重新在其他節點上啟動一個新的Executor;
提供一個嵌入式web server,以便展示各個nesto server中任務運行狀況。
2.Hadoop YARN開發經驗總結
(1)巧用資源申請API
Hadoop YARN提供了較為豐富的資源表達語義,用戶可以申請特定節點/機架上的資源,也可以通過黑名單的方式不再接受某個節點上的資源。
(2)註意memory overhead
一個container的內存是由java heap,jvm overhead和non-java memory三部分構成的,如果用戶為應用程序設置的內存大小為X GB(-xmxXg),則ApplicationMaster為其申請的container內存大小應為X+D,其中D為jvm overhead,否則可能會因總內存超出限制被YARN殺死。
(3) log rotation
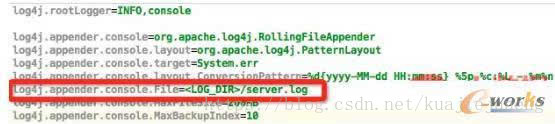
對於長服務而言,服務日誌會越積攢越多,因而log rotation顯得尤為重要。由於啟動之前,應用程序是無法知道日誌具體存放位置(比如哪個節點的哪個目錄下)的,為了方便用戶操作日誌目錄,YARN 提供了宏,當該宏出現在啟動命令中時,YARN會自動將其替換為具體的日誌目錄,比如:
echo $log4jcontent > $PWD/log4j.properties && java -Dlog4j.configuration=log4j.properties …
com.example.NestoServer 1>>/server.log 2>>/server.log其中變量log4jcontent內容如下:
(4)調試技巧
NodeManager啟動Container之前,會將該Container相關的環境變量、啟動命令等信息寫入一個shell腳本,並通過啟動該腳本的方式啟動Container。有些情況下,Container啟動失敗可能是由於啟動命令寫錯的緣故(比如某些特殊字符被轉義了),為此,可通過查看最後執行腳本內容判斷啟動命令是否存在問題,具體方法是,在container執行命令之前添加打印腳本內容的命令。

(5)共享集群帶來的性能問題
當在YARN集群中同時運行多種應用程序時,可能造成節點負載不一,進而導致某些節點上的任務運行速度慢於其他節點,這對於OLAP需求的應用是不能接受的。為了解決該問題,通常有兩種解決方式:1)通過打標簽的方式將這類應用運行到一些獨享的節點上 2)在應用程序內部實現類似於MapReduce和Spark的推測執行機制,為慢任務額外啟動一個或多個同樣的任務,以空間換時間的方式,避免慢任務拖慢整個應用程序的運行效率。
Hadoop YARN發展趨勢
對於 YARN,會朝著通用資源管理和調度方向發展,而不僅僅限於大數據處理領域,包括對 MapReduce、Spark 短作業的支持,以及對 Web Service 等長服務的支持。
Hadoop數據操作系統YARN全解析