
卷積神經網絡CNNs的理解與體會
https://blog.csdn.net/shijing_0214/article/details/53143393
孔子說過,溫故而知新,時隔倆月再重看CNNs,當時不太了解的地方,又有了新的理解與體會,特此記錄下來。文章圖片及部分素材均來自網絡,侵權請告知。
卷積神經網絡(Convolutinal Neural Networks)是非常強大的一種深度神經網絡,它在圖片的識別分類、NLP句子分類等方面已經獲得了巨大的成功,也被廣泛使用於工業界,例如谷歌將它用於圖片搜索、亞馬遜將它用於商品推薦等。
首先給出幾個CNNs應用的兩個例子如下:
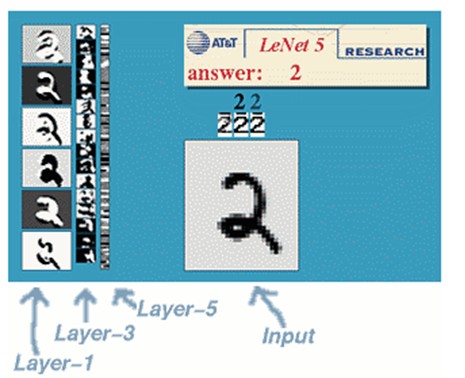 (1)、手寫體數字識別
(1)、手寫體數字識別 (2)、對象識別
(2)、對象識別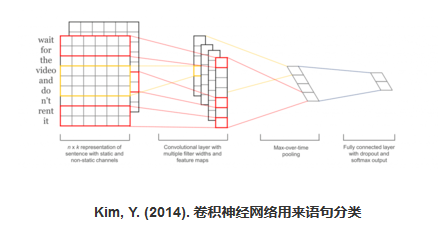
可以看到CNNs可以被用來做許多圖像與NLP的事情,且效果都很不錯。那麽CNNs的工作框架是什麽樣子呢?
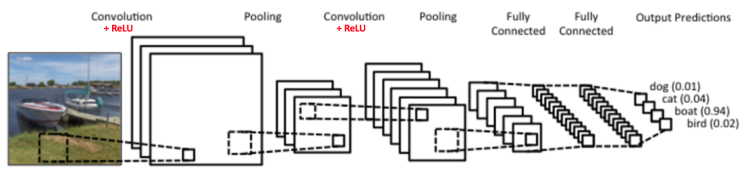
由上可以看到,CNNs的輸入層為原始圖片,當然,在計算機中圖片就是用構成像素點的多維矩陣來表示了。然後中間層包括若幹層的卷積+ReLU+池化,和若幹層的全連接層,這一部分是CNNs的核心,是用來對特征進行學習和組合的,最終會學到一些強特征,具體是如何學習到的會在下面給出。最後會利用中間層學到的強特征做為輸入通過softmax函數來得到輸出標記。
下面就針對上面給出的CNNs框架一層層進行解析。
1、輸入層
輸入層沒有什麽可講的,就是將圖片解析成由像素值表示的多維矩陣即可,如下:
通道為1也就是厚度為1的圖稱為灰度圖,也即上圖。若是由RGB表示的圖片則是一個三維矩陣表示的形式,其中第三維長度為3,包含了RGB每個通道下的信息。
2、隱層
CNNs隱層與ANN相比,不僅增加了隱層的層數,而且在結構上增加了convolution卷積、ReLU線性修正單元和pooling池化的操作。其中,卷積的作用是用來過濾特征,ReLu作為CNNs中的激活函數,作用稍後再說,pooling的作用是用來降低維度並提高模型的容錯性,如保證原圖片的輕微扭曲旋轉並不會對模型產生影響。 由於CNNs與ANN相比,模型中包含的參數多了很多,若是直接使用基於全連接的神經網絡來處理,會因為參數太多而根本無法訓練出來。那有沒有一些方法降低模型的參數數目呢?答案就是局部感知野和權值共享,中間層的操作也就是利用這些trick來實現降低參數數目的目的。
首先解釋一下什麽是局部感知野
舉個例子來講就是,一個32
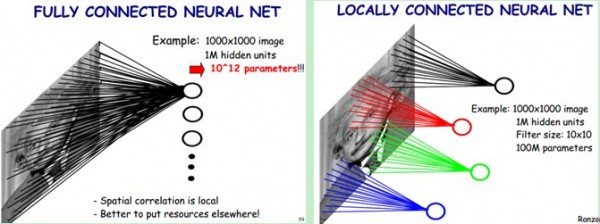
通過局部感知的特性,可以大大減少神經元間的連接數目,也就大大減少了模型參數。
但是這樣還不行,參數還是會有很多,那麽就有了第二個trick,權值共享。那麽什麽是權值共享呢?在上面提到的局部感知中圖中,假設有1m的隱層神經元,每個神經元對應了10
為什麽是一樣的呢?其實,同一層下的神經元的連接參數只與特征提取的方式有關,而與具體的位置無關,因此可以保證同一層中對所有位置的連接是權值共享的。舉個例子來講,第一層隱層是一般用來做邊緣和曲線檢測,第二層是對第一層學到的邊緣曲線組合得到的一些特征,如角度、矩形等,第三層則會學到更復雜的一些特征,如手掌、眼睛等。對於同一層來講,它們提取特征的方式一樣,所以權值也應該一樣。
通過上面講到的局部感知野和權值共享的trick,CNNs中的參數會大幅減少,從而使模型訓練成為可能。
在講局部感知野時提到了卷積操作,卷積操作,說白了就是矩陣的對位位置的相乘相加操作,如下:
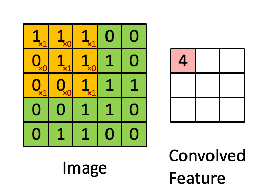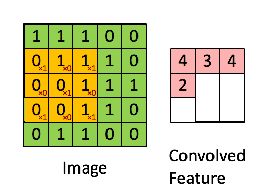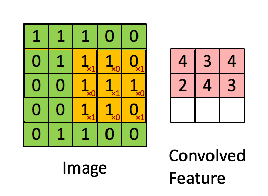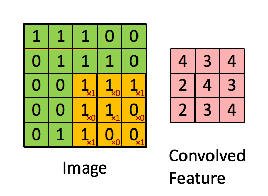
綠色為原始輸入,黃色為卷積核,也稱為過濾器,右側為經過卷積操作生成的特征圖。值得一提的是,卷積核的通道長度需要與輸入的通道長度一致。 下面一張圖很好地詮釋了卷積核的作用,如圖:

上圖中的紅色和綠色兩個小方塊對應兩個卷積核,通過兩輪卷積操作會產生兩個特征圖作為下一層的輸入進行操作。
為什麽在CNNs中激活函數選用ReLU,而不用sigmoid或tanh函數?這裏給出網上的一個回答
第一個問題:為什麽引入非線性激勵函數? 如果不用激勵函數(其實相當於激勵函數是f(x) = x),在這種情況下你每一層輸出都是上層輸入的線性函數,很容易驗證,無論你神經網絡有多少層,輸出都是輸入的線性組合,與沒有隱藏層效果相當,這種情況就是最原始的感知機(Perceptron)了。 正因為上面的原因,我們決定引入非線性函數作為激勵函數,這樣深層神經網絡就有意義了(不再是輸入的線性組合,可以逼近任意函數)。最早的想法是sigmoid函數或者tanh函數,輸出有界,很容易充當下一層輸入(以及一些人的生物解釋balabala)。
第二個問題:為什麽引入ReLU呢? 第一,采用sigmoid等函數,算激活函數時(指數運算),計算量大,反向傳播求誤差梯度時,求導涉及除法,計算量相對大,而采用ReLU激活函數,整個過程的計算量節省很多。 第二,對於深層網絡,sigmoid函數反向傳播時,很容易就會出現梯度消失的情況(在sigmoid接近飽和區時,變換太緩慢,導數趨於0,這種情況會造成信息丟失,參見 @Haofeng Li 答案的第三點),從而無法完成深層網絡的訓練。 第三,ReLU會使一部分神經元的輸出為0,這樣就造成了網絡的稀疏性,並且減少了參數的相互依存關系,緩解了過擬合問題的發生(以及一些人的生物解釋balabala)。
接下來講一下pooling過程。 池化pooling,也稱為欠采樣(subsampling)或下采樣(downsampling),主要用於降低特征的維度,同時提高模型容錯性,主要有max,average和sum等不同類型的操作。如下圖對特征圖進行最大池化的操作:
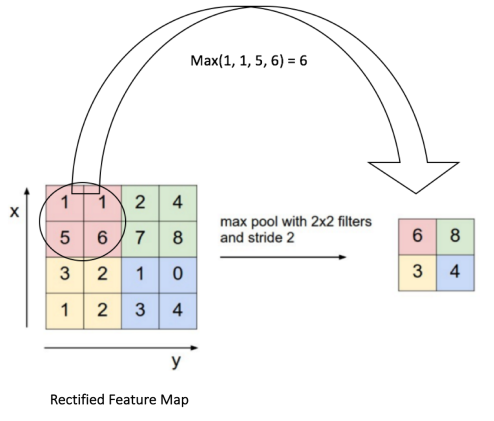
通過池化操作,使原本4
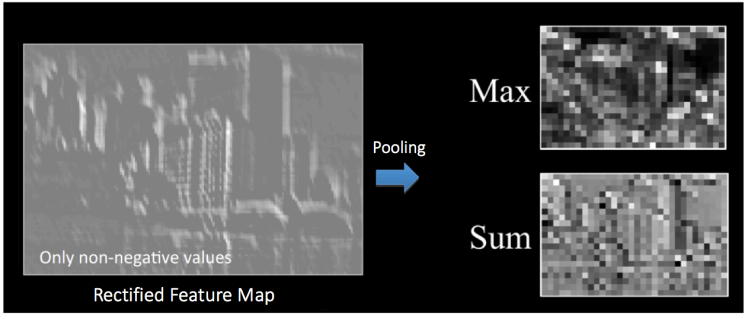 是不是人眼不太容易分辨出來特征了?沒關系,機器還是可以的。
是不是人眼不太容易分辨出來特征了?沒關系,機器還是可以的。
3、輸出層
經過若幹次的卷積+線性修正+pooling後,模型會將學到的高水平的特征接到一個全連接層。這個時候你就可以把它理解為一個簡單的多分類的神經網絡,通過softmax函數得到輸出,一個完整的過程如下圖:

4、可視化
參考【1】中給了一個CNNs做手寫體數字識別的2D可視化展示,可以看到每一層做了什麽工作,很有意思,大家可以看看。
5、參考
【1】、An Intuitive Explanation of Convolutional Neural Networks 【2】、技術向:一文讀懂卷積神經網絡CNN 【3】、知乎Begin Again關於ReLU作用的回答
卷積神經網絡CNNs的理解與體會