
淺談數據庫集群(一)
現在,隨著上網人數的激增,一些大型的網站開始使用數據庫集群來提高數據庫的可靠性和數據庫的性能。那麽在介紹數據庫集群之前首先需要弄清楚幾個問題。
1.為什麽要用數據庫集群
(1)通過使用數據庫集群可以使讀寫分離,提高數據庫的系統性能。
大家都知道,mysql是支持分布式的。MySQL Proxy最強大的一項功能是實現“讀寫分離(Read/Write Splitting)”。基本的原理是讓主數據庫處理事務性查詢,而從數據庫處
理SELECT查詢。數據庫復制被用來把事務性查詢導致的變更同步到集群中的從數據庫,從而使從數據庫和主數據庫的數據保持一致。 當然,主服務器也可以提供查詢服務。
使用讀寫分離最大的作用無非是環境服務器壓力。可以看下這張圖:
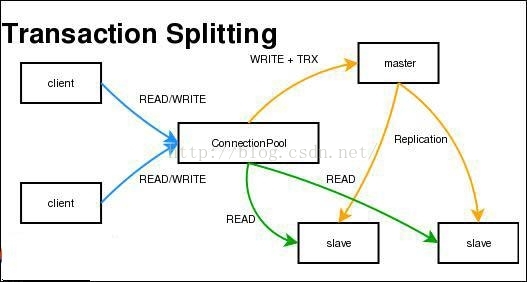
——————————————————————————————————————————————————————————
為什麽讀寫分離能提高數據庫的性能?(摘自網絡)
1.物理服務器增加,負荷增加
2.主從只負責各自的寫和讀,極大程度的緩解X鎖和S鎖爭用
3.從庫可配置myisam引擎,提升查詢性能以及節約系統開銷
4.從庫同步主庫的數據和主庫直接寫還是有區別的,通過主庫發送來的binlog恢復數據,但是,最重要區別在於主庫向從庫發送binlog是異步的,從庫恢復數據也是異步的
5.讀寫分離適用與讀遠大於寫的場景,如果只有一臺服務器,當select很多時,update和delete會被這些select訪問中的數據堵塞,等待select結束,並發性能不高。 對於寫和讀比例相近的應用,應該部署雙主相互復制
6.可以在從庫啟動是增加一些參數來提高其讀的性能,例如--skip-innodb、--skip-bdb、--low-priority-updates以及--delay-key-write=ALL。當然這些設置也是需要根據具體業務需求來定得,不一定能用上
7.分攤讀取。假如我們有1主3從,不考慮上述1中提到的從庫單方面設置,假設現在1 分鐘內有10條寫入,150條讀取。那麽,1主3從相當於共計40條寫入,而讀取總數沒變,因此平均下來每臺服務器承擔了10條寫入和50條讀取(主庫不 承擔讀取操作)。因此,雖然寫入沒變,但是讀取大大分攤了,提高了系統性能。另外,當讀取被分攤後,又間接提高了寫入的性能。所以,總體性能提高了,說白 了就是拿機器和帶寬換性能。MySQL官方文檔中有相關演算公式:官方文檔 見6.9FAQ之“MySQL復制能夠何時和多大程度提高系統性能”
8.MySQL復制另外一大功能是增加冗余,提高可用性,當一臺數據庫服務器宕機後能通過調整另外一臺從庫來以最快的速度恢復服務,因此不能光看性能,也就是說1主1從也是可以的。
——————————————————————————————————————————————————————————
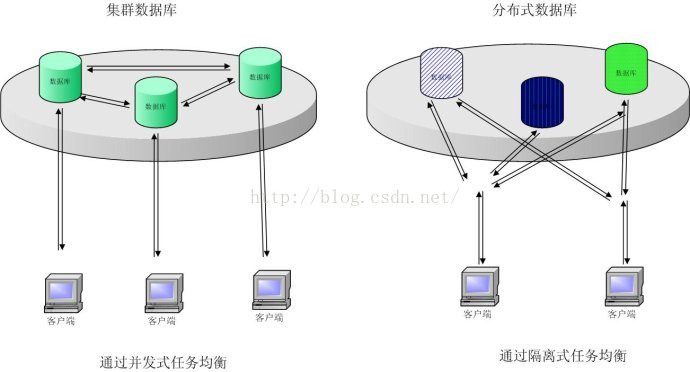
2.數據庫集群和分布式數據庫有什麽區別?
一句話:分布式是並聯工作的,集群是串聯工作的。
1:分布式是指將不同的業務分布在不同的地方。 而集群指的是將幾臺服務器集中在一起,實現同一業務。分布式中的每一個節點,都可以做集群。 而集群並不一定就是分
布式的。
舉例:就比如新浪網,訪問的人多了,他可以做一個群集,前面放一個響應服務器,後面幾臺服務器完成同一業務,如果有業務訪問的時候,響應服務器看哪臺服務器的
負載不是很重,就將給哪一臺去完成。而分布式,從窄意上理解,也跟集群差不多, 但是它的組織比較松散,不像集群,有一個組織性,一臺服務器垮了,其它的服務器可以頂上來。
分布式的每一個節點,都完成不同的業務,一個節點垮了,哪這個業務就不可訪問了。
2:簡單說,分布式是以縮短單個任務的執行時間來提升效率的,而集群則是通過提高單位時間內執行的任務數來提升效率。
舉例:如果一個任務由10個子任務組成,每個子任務單獨執行需1小時,則在一臺服務器上執行該任務需10小時。
采用分布式方案,提供10臺服務器,每臺服務器只負責處理一個子任務,不考慮子任務間的依賴關系,執行完這個任務只需一個小時。(這種工作模式的一個典型代表就是
Hadoop的Map/Reduce分布式計算模型)
而采用集群方案,同樣提供10臺服務器,每臺服務器都能獨立處理這個任務。假設有10個任務同時到達,10個服務器將同時工作,1小時後,10個任務同時完成,這樣,
整身來看,還是1小時內完成一個任務!
看下圖:
轉載自:http://blog.csdn.net/zhangzijiejiayou
淺談數據庫集群(一)